




sora视频生成AI

patches
在文字训练模型中,各种文本,代码,数学内容都是以token作为基本单位,GPT的主要工作就是预测下一个token。而在Sora中就将多种类型的视觉数据转化为统一的表示方法——patches:(有关patches,就是把原图拆成很多小的图像块,每个小块我们称之为patch,每个patch被进一步序列化,转换成一维向量+再加上每一个patch 的位置信息,就形成了最终训练所需要的向量。然后就放入到transformer架构进行训练。其中对于大多数雷同的patches可以在一定程度上丢弃,正好sora的视频的每一帧会有大量的重复patches,这样可以精简训练集。并且把图片拆成一个图片块还有另外一个好处,就是可以形成长宽高和清晰度不相同的视频。
stable diffusion
对于很大的视频文件,采用了stable diffusion——对原图提取前空间特征,然后对潜空间进行操作,最后可以生成新的图(将原图的关键信息内容提炼成潜空间特征“浓缩精华的特征图”)。然后之后就可以 写出关键字–>潜空间特征–》形成一堆AI图。
transfrom diffusion:
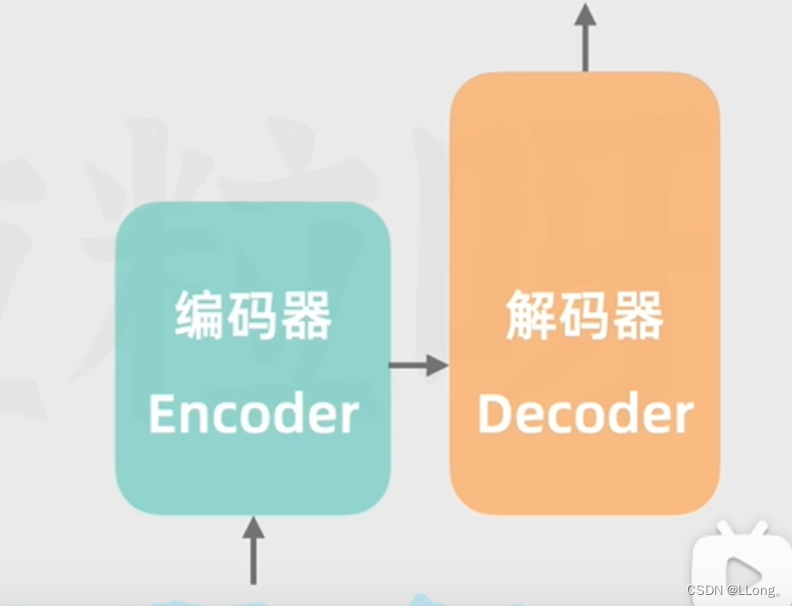
文本 --> token—> token ID (数字表示文本)——>向量表示token(通过向量可以知道各个单词之间的关联差距等等信息)—>把位置编码向量 + 向量表示的token一起放入编码器 ——>通过编码器的自注意力机制捕捉到了语法语义上的关键特征(ps:自注意力指的是通过计算各个词之间的相关性来调整注意力比重);
解码器比较类似:
输入文本文本 --> token—> token ID (数字表示文本)——>向量表示token(通过向量可以知道各个单词之间的关联差距等等信息)—>把位置编码向量 + 向量表示的token一起放入解码器——>
编码器训练的数据 + 把位置编码向量 + 向量表示的token一起放入解码器 ——>放入解码器。
也是通过自注意来猜测下一个词是什么,从而达到文本生成。
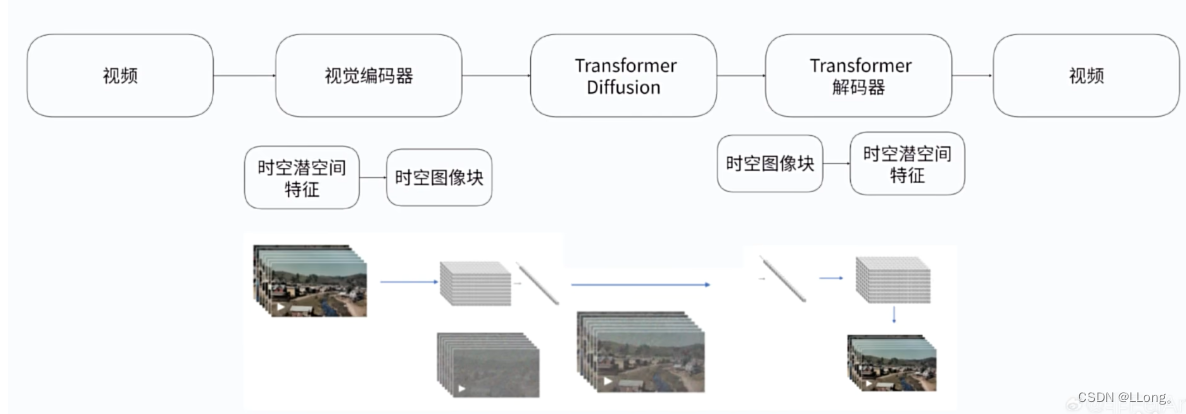
Sora的做法:
原始视频–>序列帧图片–>序列帧h图片转为时空潜空间特征 ——>将潜空间特征转换为时空块(space patches)——>可以训练的时空向量
文本描述怎么来呢?
序列帧图片——>让GPT4v按规范,让AI工整的描述视频内容——>文本描述向量
文本描述和时空向量两个放入diffusion里面训练
Sora的推理过程:
用户文本输入——>AI扩展成标准的视频描述语言——>Sora从噪声点生成初始的时空图像块(timespace patches)——>基于已有的时空图像块,推测下一个时空图像块——>将时空图像块还原成序列帧——>视频
OpenAI的Sora模型作为一种先进的视频生成技术,虽然在视频生成领域取得了显著的进展,但仍然存在一些缺陷和挑战。以下是Sora模型目前面临的一些主要问题:
- 物理交互的不准确模拟:Sora在模拟基本物理交互,如玻璃破碎等方面,可能不够精确。这可能是因为模型在训练数据中缺乏足够的这类物理事件的示例,或者模型无法充分学习和理解这些复杂物理过程的底层原理。
- 对象状态变化的不正确:在模拟涉及对象状态显著变化的交互时,如吃食物,Sora可能无法始终正确反映出变化。这表明模型可能在理解和预测对象状态变化的动态过程方面存在局限。
- 长时视频样本的不连贯性:在生成长时间的视频样本时,Sora可能会产生不连贯的情节或细节,这可能是由于模型难以在长时间跨度内保持上下文的一致性。
- 对象的突然出现:视频中可能会出现对象的无缘无故出现,这表明模型在空间和时间连续性的理解上还有待提高。
- 缺乏声音生成功能:尽管Sora在视频内容生成方面表现出色,但它目前还不能为生成的视频添加声音。这限制了视频的完整性和用户体验。
- 难以处理复杂的物理过程:Sora在渲染复杂的物理过程,如流体动力学、复杂的光影效果等方面存在一定难度。
- 缺乏物理引擎:与真正的世界模型相比,Sora缺乏物理引擎来运行前向时间模拟,这意味着它在模拟真实世界物理规律方面存在局限。
- 训练过程中的潜在问题:尽管Sora在训练过程中表现出了一定的提升,但其训练过程是否使用了特定的游戏引擎(如虚幻引擎5)尚无确切证据,且训练数据中可能没有包含足够的物理规律信息。
- 用户反馈和需求的响应:Sora的开发团队正在积极收集用户反馈,并考虑如何通过更精细、直接的控制方式来改进模型。
尽管存在这些挑战,Sora的开发团队正在不断努力改进模型,以解决这些问题并提升其性能。随着技术的不断进步和更多用户反馈的收集,预计Sora模型将在未来得到进一步的优化和完善。
Midjourney原理
自动驾驶汽车的网络安全问题(可以和物联网安全扯上关系)
-
鲁棒性一词在各个领域应用广泛,本意指的系统在被干扰或不确定的情况下仍能保持它们的特征行为的能力。神经网络的鲁棒性指神经网络模型防御对抗攻击的能力。鲁棒性越强,模型防御能力越高。鲁棒性也可用来指对抗噪声的能力。
-
自动驾驶车如何被攻击?
- 汽车的通信和娱乐系统是最容易被黑客通过入侵手机网络、WiFi、蓝牙等通道,找到车载App漏洞进行攻击,就能获取用户在这些App上的隐私数据、历史记录,实现监听或促发导航偏离。
-
另外传感器也是黑客入侵可能的途径。像GPS、摄像头、激光雷达、毫米波雷达、IMU等常见传感器装置,都可以被黑客干扰进而影响自动驾驶的判断机制和行驶轨道。比如攻击激光雷达让其辨别不了即时性不良数据,或者是试着干扰他们长期积累的聚合数据等等。
-
如何保护个人信息安全?
- 一是要制定自动驾驶网络安全相关法律。法律的保障总是第一位的,眼下自动驾驶相关法律的完善还处于初始阶段,一部专门的网络安全法规的出台意义重大。目前,英国已经发布了《联网与自动驾驶汽车网络安全主要原则》,对设计阶段以及上路后的自动驾驶汽车安全问题做出了要求,这对于我国的相关法律制定是一大参考。
- 二是要明确自动驾驶个人信息安全监管机构。若是职责不清、监管分散,很可能会形成“九龙治水”的局面,影响到实际监管力度与执行。因此,需要明确自动驾驶领域的个人信息安全监管机构,例如将监管职责整体赋予交通主管部门。
- 三是要促进行业企业自觉维护个人信息安全。对于行业企业而言,除了要提高个人信息安全保护意识,正确、积极实施个人信息保护措施,合法、合理收集和利用相关信息数据,同时也要始终以“安全”为第一要义,在重视车辆运行安全的基础上,也要高度重视网络安全技术的升级与完善,从而在源头遏制自动驾驶汽车网络安全风险
-
现有的人工智能模型,尤其是深度学习模型容易受到对抗性攻击,而由于智能模型是自动驾驶系统进行感知和决策的核心组件,智能模型的安全性极大地影响着自动驾驶系统的整体安全性
-
由于自动驾驶系统往往配备多个传感器且需要综合处理融合这些传感器信息,因此自动驾驶系统所面临的攻击手段更加复杂多样,涵盖的攻击面更加广泛、
-
核心部分由三个功能层组成,包括传感器层、感知层和决策层
-
依据攻击者能够采取的干扰手段,攻击被分为:
① 物理世界攻击.攻击者改变物理世界的驾驶环境来影响自动驾驶智能模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









