




 本文介绍了如何使用Pandas加载和处理高中体测数据,包括读取Excel文件的不同工作表,处理多层列索引,转换数据类型。针对不同项目的评分标准,进行了数据转换,如将时间格式转为float类型。接着,运用map、apply、transform方法进行分数转换,并重新排列列索引。最后,通过Matplotlib进行可视化,包括饼图展示男1000米跑和男引体的得分分布,直方图呈现女800米跑和女跳远的分数段人数,以及嵌套饼图对比男女生体重指数的分类比例。
本文介绍了如何使用Pandas加载和处理高中体测数据,包括读取Excel文件的不同工作表,处理多层列索引,转换数据类型。针对不同项目的评分标准,进行了数据转换,如将时间格式转为float类型。接着,运用map、apply、transform方法进行分数转换,并重新排列列索引。最后,通过Matplotlib进行可视化,包括饼图展示男1000米跑和男引体的得分分布,直方图呈现女800米跑和女跳远的分数段人数,以及嵌套饼图对比男女生体重指数的分类比例。
1、数据加载, pd.read_excel('./18级高一体测成绩汇总.xls')默认加载第一个工作表
# 引入模块
import numpy as np
import pandas as pd
ma= pd.read_excel('./18级高一体测成绩汇总.xls')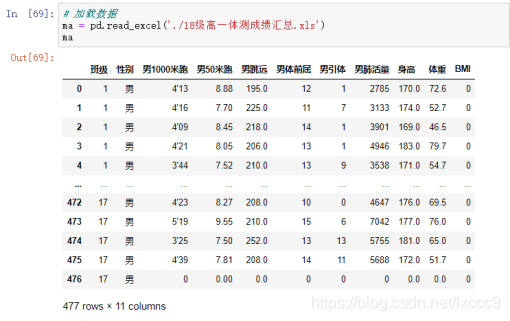
2、数据加载, pd.read_excel('./18级高一体测成绩汇总.xls',sheet_name = 1)指定加载第二个工作表
fe = pd.read_excel('./18级高一体测成绩汇总.xls',sheet_name=1)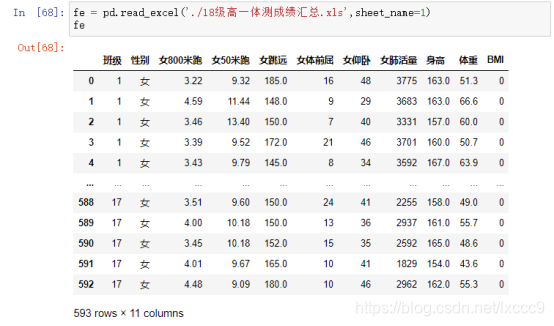
3、评分标准加载,pd.read_excel('./体侧成绩评分表.xls',header = [0,1]),header=[0,1]表示多层列索引
stand = pd.read_excel('./体侧成绩评分表.xls',header=[0,1]) 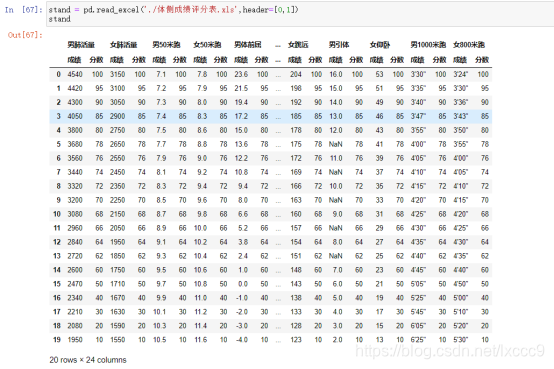
4、数据类型转换
男1000米跑,数据类型是str,并且是4’26这种形式,需要变成float类型的值
ma['男1000米跑'] = ma['男1000米跑'].str.replace("'",".")
ma['男1000米跑'] = ma['男1000米跑'].astype(float) ![]()
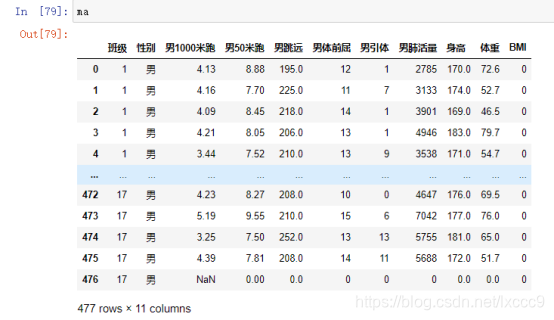
评分标准中男1000米跑和女800米跑的成绩都是4‘10’‘这种形式,需要转化为float类型值
stand = stand.replace("'",".",regex=True)
stand = stand.replace('"',"",regex=True) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









