import os
import cv2
import json
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import albumentations as A
from albumentations.pytorch import ToTensorV2
# 1. 视频帧提取
def extract_video_frames(video_path, output_dir, frame_interval=10):
"""从视频中提取帧"""
os.makedirs(output_dir, exist_ok=True)
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
raise IOError(f"无法打开视频: {video_path}")
fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(f"视频信息: {fps:.1f} FPS, 总帧数: {total_frames}")
frame_count = 0
saved_count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if frame_count % frame_interval == 0:
filename = os.path.join(output_dir, f"frame_{saved_count:05d}.jpg")
cv2.imwrite(filename, frame)
saved_count += 1
frame_count += 1
cap.release()
print(f"✅ 成功提取 {saved_count} 帧到 {output_dir}")
return saved_count
# 2. 交互式标注工具
def annotate_points(image_dir, annotation_file):
"""手动标注黑色小圆点位置(添加返回上一张功能)"""
if os.path.exists(annotation_file):
with open(annotation_file) as f:
annotations = json.load(f)
else:
annotations = {"images": [], "annotations": []}
image_files = sorted([f for f in os.listdir(image_dir)
if f.lower().endswith(('.jpg', '.png'))])
cv2.namedWindow("标注工具 - 黑色小圆点", cv2.WINDOW_NORMAL)
# 添加当前处理的图片索引
current_idx = 0
while current_idx < len(image_files):
img_file = image_files[current_idx]
img_path = os.path.join(image_dir, img_file)
# 检查是否已标注
img_info = next((img for img in annotations["images"] if img["file_name"] == img_file), None)
if img_info:
img_id = img_info["id"]
# 加载已标注的点
points = [ann["point"] for ann in annotations["annotations"]
if ann["image_id"] == img_id]
else:
points = []
img_info = None
img = cv2.imread(img_path)
if img is None:
print(f"⚠️ 无法读取图像: {img_path}")
current_idx += 1
continue
img_disp = img.copy()
# 显示当前图像信息
info_text = f"图像 {current_idx+1}/{len(image_files)}: {img_file}"
cv2.putText(img_disp, info_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.putText(img_disp, "左键: 添加点 | 右键: 删除点", (10, 60),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 255), 1)
cv2.putText(img_disp, "s: 保存 | b: 上一张 | n: 下一张 | q: 退出", (10, 90),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 0), 1)
# 绘制已有点
for pt in points:
cv2.circle(img_disp, tuple(pt), 5, (0, 0, 255), -1)
# 鼠标回调函数
def mouse_callback(event, x, y, flags, param):
nonlocal img_disp, img, points
if event == cv2.EVENT_LBUTTONDOWN:
points.append((x, y))
cv2.circle(img_disp, (x, y), 5, (0, 0, 255), -1)
cv2.imshow("标注工具 - 黑色小圆点", img_disp)
elif event == cv2.EVENT_RBUTTONDOWN and points:
# 移除距离点击位置最近的点
if points:
dists = [((x - pt[0])**2 + (y - pt[1])**2) for pt in points]
nearest_idx = np.argmin(dists)
points.pop(nearest_idx)
# 重绘图
img_disp = img.copy()
cv2.putText(img_disp, info_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
cv2.putText(img_disp, "左键: 添加点 | 右键: 删除点", (10, 60),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 255), 1)
cv2.putText(img_disp, "s: 保存 | b: 上一张 | n: 下一张 | q: 退出", (10, 90),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 0), 1)
for pt in points:
cv2.circle(img_disp, pt, 5, (0, 0, 255), -1)
cv2.imshow("标注工具 - 黑色小圆点", img_disp)
cv2.setMouseCallback("标注工具 - 黑色小圆点", mouse_callback)
cv2.imshow("标注工具 - 黑色小圆点", img_disp)
while True:
key = cv2.waitKey(1) & 0xFF
if key == ord('s'): # 保存
height, width = img.shape[:2]
if not img_info:
# 新建图像记录
img_id = len(annotations["images"])
annotations["images"].append({
"id": img_id,
"file_name": img_file,
"width": width,
"height": height
})
else:
img_id = img_info["id"]
# 删除旧标注
annotations["annotations"] = [
ann for ann in annotations["annotations"]
if ann["image_id"] != img_id
]
# 添加新标注
for pt in points:
annotations["annotations"].append({
"image_id": img_id,
"point": list(pt),
"category": "black_dot"
})
with open(annotation_file, 'w') as f:
json.dump(annotations, f, indent=2)
print(f"✅ 标注保存: {img_file} - {len(points)}个点")
current_idx += 1 # 保存后自动下一张
break
elif key == ord('n'): # 下一张(不保存)
current_idx += 1
break
elif key == ord('b'): # 上一张
if current_idx > 0:
current_idx -= 1
else:
print("已经是第一张图像")
break
elif key == ord('q'): # 退出
cv2.destroyAllWindows()
return annotations
cv2.destroyAllWindows()
print(f"✅ 所有标注保存到 {annotation_file}")
return annotations
# 3. 数据集构建
class DotDataset(Dataset):
"""黑色小圆点检测数据集"""
def __init__(self, image_dir, annotations, img_size=256, transform=None):
self.image_dir = image_dir
self.annotations = annotations
self.img_size = (img_size, img_size)
self.transform = transform
self.img_size = (img_size, img_size)
# 创建图像ID到点坐标的映射
self.image_points = {}
for ann in annotations["annotations"]:
img_id = ann["image_id"]
if img_id not in self.image_points:
self.image_points[img_id] = []
self.image_points[img_id].append(ann["point"])
# 创建图像ID到文件名的映射
self.image_files = {img["id"]: img["file_name"] for img in annotations["images"]}
def __len__(self):
return len(self.annotations["images"])
def __getitem__(self, idx):
img_info = self.annotations["images"][idx]
img_id = img_info["id"]
img_file = self.image_files[img_id]
img_path = os.path.join(self.image_dir, img_file)
# 读取图像
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
orig_h, orig_w = image.shape[:2]
# 调整图像大小
image = cv2.resize(image, self.img_size)
# 创建热力图标签 (缩小4倍)
heatmap = np.zeros((self.img_size[1], self.img_size[0]), dtype=np.float32)
points = self.image_points.get(img_id, [])
for pt in points:
# 归一化坐标
nx = pt[0] / orig_w
ny = pt[1] / orig_h
# 转换到热力图坐标
hx = int(nx * (self.img_size[0]))
hy = int(ny * (self.img_size[1]))
if 0 <= hx < heatmap.shape[0] and 0 <= hy < heatmap.shape[1]:
# 应用高斯分布
heatmap = self.apply_gaussian(heatmap, hx, hy, sigma=4.0)
# 应用数据增强
if self.transform:
transformed = self.transform(image=image, mask=heatmap)
image = transformed["image"]
heatmap = transformed["mask"]
return image, heatmap.unsqueeze(0) # 添加通道维度
def apply_gaussian(self, heatmap, x, y, sigma=1.0):
"""在指定位置添加高斯分布"""
h, w = heatmap.shape
xv, yv = np.meshgrid(np.arange(w), np.arange(h))
dist = (xv - x)**2 + (yv - y)**2
gaussian = np.exp(-dist / (2 * sigma**2))
return np.maximum(heatmap, gaussian)
def visualize(self, idx):
"""可视化样本"""
image, heatmap = self.__getitem__(idx)
if isinstance(image, torch.Tensor):
image = image.permute(1, 2, 0).numpy()
heatmap = heatmap.squeeze().numpy()
# 创建热力图可视化
heatmap_viz = cv2.normalize(heatmap, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8)
heatmap_viz = cv2.applyColorMap(heatmap_viz, cv2.COLORMAP_JET)
heatmap_viz = cv2.resize(heatmap_viz, self.img_size)
# 叠加热力图
overlay = cv2.addWeighted((image*255).astype(np.uint8), 0.7, heatmap_viz, 0.3, 0)
plt.figure(figsize=(15, 5))
plt.subplot(131)
plt.imshow(image)
plt.title("原始图像")
plt.subplot(132)
plt.imshow(heatmap_viz)
plt.title("热力图")
plt.subplot(133)
plt.imshow(overlay)
plt.title("叠加效果")
plt.show()
# 4. 检测模型
class DotDetector(nn.Module):
"""黑色小圆点检测模型"""
def __init__(self, in_channels=3, out_channels=1, base_channels=32):
super().__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, base_channels, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(base_channels),
nn.MaxPool2d(2), # 32x128x128
nn.Conv2d(base_channels, base_channels*2, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(base_channels*2),
nn.MaxPool2d(2), # 64x64x64
nn.Conv2d(base_channels*2, base_channels*4, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(base_channels*4),
nn.MaxPool2d(2), # 128x32x32
nn.Conv2d(base_channels*4, base_channels*8, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(base_channels*8),
nn.MaxPool2d(2), # 256x16x16
)
# 解码器
self.decoder = nn.Sequential(
nn.Conv2d(base_channels*8, base_channels*4, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(base_channels*4),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True), # 128x32x32
nn.Conv2d(base_channels*4, base_channels*2, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(base_channels*2),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True), # 64x64x64
nn.Conv2d(base_channels*2, base_channels, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(base_channels),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True), # 32x128x128
nn.Conv2d(base_channels, base_channels//2, 3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(base_channels//2),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True), # 16x256x256
nn.Conv2d(base_channels//2, out_channels, 1),
nn.Sigmoid() # 输出概率图 [0,1]
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# 5. 训练函数
def train_model(model, train_loader, val_loader, epochs=50, lr=0.001):
"""训练检测模型"""
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 损失函数和优化器
criterion = nn.BCELoss() # 二元交叉熵
optimizer = optim.Adam(model.parameters(), lr=lr)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=5)
best_val_loss = float('inf')
for epoch in range(epochs):
# 训练阶段
model.train()
train_loss = 0.0
for images, targets in tqdm(train_loader, desc=f"训练轮次 {epoch+1}/{epochs}"):
images = images.to(device)
targets = targets.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, targets)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * images.size(0)
train_loss /= len(train_loader.dataset)
# 验证阶段
model.eval()
val_loss = 0.0
with torch.no_grad():
for images, targets in val_loader:
images = images.to(device)
targets = targets.to(device)
outputs = model(images)
loss = criterion(outputs, targets)
val_loss += loss.item() * images.size(0)
val_loss /= len(val_loader.dataset)
scheduler.step(val_loss)
# 打印进度
print(f"轮次 [{epoch+1}/{epochs}] - 训练损失: {train_loss:.4f}, 验证损失: {val_loss:.4f}")
# 保存最佳模型
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), "best_dot_detector.pth")
print(f"✅ 保存最佳模型 (验证损失: {val_loss:.4f})")
print("训练完成!")
return model
# 6. 主流程
def main():
# 1. 视频帧提取
video_path = r"E:\专业综合实践-光电镊\参考资料\参考资料\41378_2025_892_MOESM3_ESM.mp4" # 替换为你的视频路径
frames_dir = "extracted_frames"
print("📹 提取视频帧...")
extract_video_frames(video_path, frames_dir, frame_interval=15)
# 2. 手动标注
annotation_file = "dot_annotations.json"
print("\n🖱️ 开始标注黑色小圆点...")
annotations = annotate_points(frames_dir, annotation_file)
# 3. 数据预处理
print("\n📊 准备数据集...")
transform = A.Compose([
A.RandomRotate90(),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.5),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
ToTensorV2()
])
dataset = DotDataset(frames_dir, annotations, img_size=256, transform=transform)
# 可视化样本
print("\n👀 可视化样本...")
dataset.visualize(0)
# 划分训练集和验证集
train_idx, val_idx = train_test_split(
range(len(dataset)),
test_size=0.2,
random_state=42
)
train_set = torch.utils.data.Subset(dataset, train_idx)
val_set = torch.utils.data.Subset(dataset, val_idx)
# 创建数据加载器
train_loader = DataLoader(
train_set,
batch_size=8,
shuffle=True,
num_workers=2
)
val_loader = DataLoader(
val_set,
batch_size=8,
shuffle=False,
num_workers=2
)
# 4. 训练模型
print("\n🤖 创建和训练模型...")
model = DotDetector()
train_model(
model,
train_loader,
val_loader,
epochs=50,
lr=0.001
)
print("\n✅ 训练完成! 最佳模型已保存为 'best_dot_detector.pth'")
if __name__ == "__main__":
main()
得到了figure1,然后怎么操作





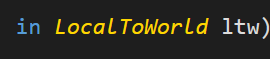

 LTW与transform.forward:在Unity中理解局部到世界坐标转换
LTW与transform.forward:在Unity中理解局部到世界坐标转换
 本文讲解了如何在Unity编程中使用Entities.ForEach和ltw.LocalToWorldltw来实现对象从局部坐标到世界坐标的转换,并重点介绍了ltw.Forward的应用。
本文讲解了如何在Unity编程中使用Entities.ForEach和ltw.LocalToWorldltw来实现对象从局部坐标到世界坐标的转换,并重点介绍了ltw.Forward的应用。
 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























