




一、背景
前面学习了 Transformer,本文再来学习 ViT,阅读论文的基础上结合代码实践。ViT 刚发布的时候本人还在读研,ViT 一出来 CV 领域也开始频繁出现 Transformer 的身影,无奈当时已经确定了研究方向和技术路线,就没有再研究 ViT。一晃几年过去,现在才算是开始学习 ViT,虽然可能用到的机会不多,但学习一下论文思想和模型结构相信还是很有用的。
二、论文
Paper:[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
1. 模型结构
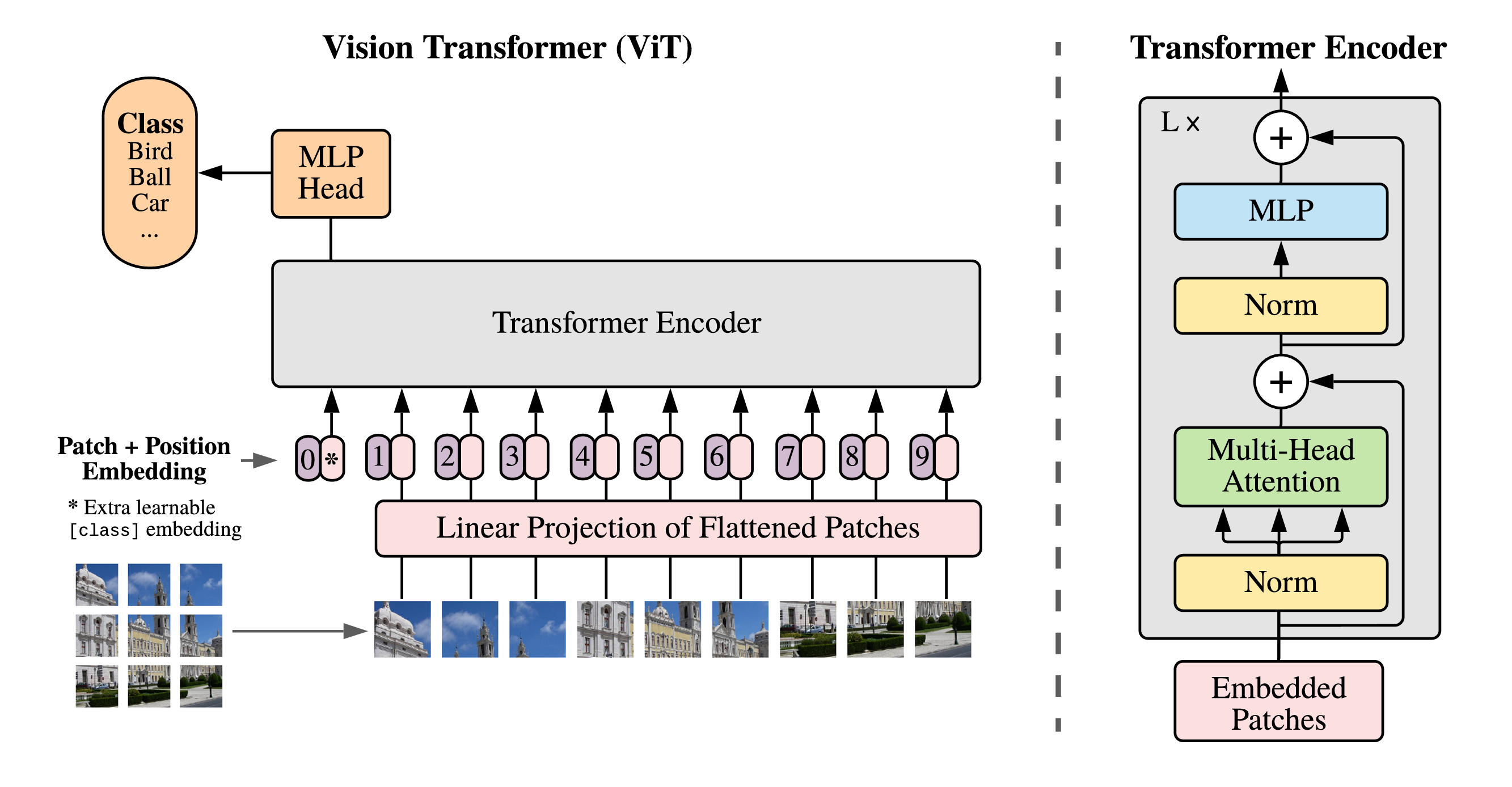
核心思想:将图像切成一个个小块(patch),经过线性投影转换为 token 序列,每个 token 拼接一个位置编码表示 patch 之间的位置关系,[class] token 标识图像类别,然后将这个序列送入 Transformer 的 Encoder,MLP 中的分类头负责预测类别信息。
下面结合代码分析处理过程,代码使用的 pytorch 版本的 ViT:https://github.com/kentaroy47/vision-transformers-cifar10
ViT 主体实现:
class ViT(nn.Module):
"""
image_size: 32*32*3
patch_size: 4
dim: 各层输出维度,Transformer中的d_model=512
depth: Transformer的堆叠数,N
heads: 多头注意力头数
pool: 类别预测的方式,cls: 单独添加类别token(论文中的方式,默认);mean: 所有token的特征平均
dim_head: 每个注意力头的维度,d_model/heads
"""
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
# 确保能切分出整数个patch
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
# patch个数
num_patches = (image_height // patch_height) * (image_width // patch_width)
# 每个patch的大小=P^2 * C
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
# 图像嵌入层,维度映射为d_model
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
# 位置嵌入层
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
# class token 层
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# dropout层
self.dropout = nn.Dropout(emb_dropout)
# Transformer层
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
# pool 类型
self.pool = pool
# 恒等映射层,对输入做原样输出,这里貌似没啥作用
self.to_latent = nn.Identity()
# MLP分类层,先做LN,再将d_model映射为类别数进行预测
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
# 图像嵌入 (img: [128, 3, 32, 32] --> x: [128, 64, 512])
x = self.to_patch_embedding(img)
b, n, _ = x.shape
#为当前批数据添加class token (self.cls_token: [1, 1, 512],cls_token: [128, 1, 512])
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
# 在patch序列中嵌入class token (x: [128, 64, 512] --> x: [128, 65, 512])
x = torch.cat((cls_tokens, x), dim=1)
# 每个token添加位置信息
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
# 取出序列中的第一个token,即class token
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
# 返回分类预测
return self.mlp_head(x)2. 图像嵌入
实现如何将图像数据转换为 Transformer 需要的序列数据。
2.1 patch embedding
对于一张输入图像 ,将其切分成 patch 序列,每个 patch
,共
个,由 patch 组成的序列
。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1177
1177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









