



一.背景
LangGraph 作为 LangChain 生态中专注于大模型应用流程编排与多智能体协作的核心框架,其核心能力是将复杂业务流程抽象为可视化的有向图(StateGraph),支持节点执行、状态流转与分支决策。但在企业级复杂场景中,单一图结构已无法满足 “流程分层管理、复用与协同” 的需求,因此 “父子图(Parent-Child Graph)构建” 能力应运而生 —— 本质是将一个主图(父图)与多个子图(子流程)嵌套组合,实现流程的模块化拆分、层级化管理与跨图协同。这一能力的需求源于单一 LangGraph 结构在复杂流程编排中的痛点,也是 LangGraph 从 “单流程编排” 走向 “企业级复杂流程管理” 的关键支撑。
1.单一 LangGraph 结构编排复杂流程的核心痛点
在父子图能力出现前,企业级大模型流程(如智能客服全流程、企业级合同审核、多步骤数据分析、跨部门业务审批)若基于单一 LangGraph 结构开发,会面临诸多难以解决的问题:
1. 流程耦合度高,维护成本剧增
复杂流程往往包含数十个节点与分支(如智能客服流程涵盖 “用户意图识别→问题分类→知识库检索→大模型生成→人工介入→结果反馈” 等步骤,且每个步骤又包含子逻辑),若将所有节点与逻辑都写在同一个图中,会形成 “巨型图”:节点之间耦合严重,修改某一个子逻辑(如 “知识库检索” 的方式)需改动整个图的代码,易引发连锁错误;且代码可读性极差,新开发者需花费大量时间梳理节点关系,维护成本随流程复杂度呈指数级增长。
2. 流程逻辑无法复用,重复开发效率低
企业不同业务流程往往包含相同的子逻辑(如 “文本向量检索”“敏感信息校验”“人工审核节点”),单一图结构下,这些子逻辑需在每个图中重复编写节点与流转规则:例如智能客服流程和合同审查流程都需要 “敏感信息校验”,却要分别实现对应的节点与分支,不仅重复开发浪费人力,还会导致不同流程中相同逻辑的实现不一致,后期优化时需逐个修改,效率极低。
3. 多智能体协作难以分层管控
在多智能体协作场景中(如 “数据分析师智能体→法务智能体→财务智能体” 协同完成项目评估),每个智能体的工作流程是独立的子流程,若将所有智能体的逻辑融入单一图中,无法实现 “主流程管控智能体调度,子流程负责单个智能体的具体操作” 的分层管理:主流程无法灵活调用不同智能体的子流程,也无法监控子流程的执行状态,导致多智能体协作混乱,难以适配复杂的协同逻辑。
4. 流程执行状态管理混乱,无法精细化控制
单一图结构下,流程的状态是全局的,若流程包含多个独立的子步骤(如 “数据采集→数据清洗→数据分析→报告生成”),无法单独暂停、重启或回滚某个子步骤的执行:例如 “数据分析” 步骤执行失败,需重新运行整个流程,而非仅重启 “数据分析” 子流程,资源浪费严重;且无法针对子步骤设置独立的状态持久化与权限管控,精细化控制能力不足。
5. 流程扩展能力不足,适配业务变化难
企业业务流程会随需求变化不断扩展(如智能客服流程新增 “语音转文字” 步骤、合同审查流程新增 “跨境条款校验” 步骤),单一图结构下,新增步骤需直接嵌入现有节点之间,易破坏原有流程的流转逻辑;且无法实现 “即插即用” 的扩展(如直接引入第三方开发的 “跨境条款校验” 子图),适配业务变化的灵活性差。
2.LangGraph 父子图构建的核心价值
LangGraph 父子图构建能力通过 “父图作为主流程入口,子图作为模块化子流程” 的嵌套架构,将复杂流程拆分为 “主流程 - 子流程” 的层级结构,解决单一图结构的痛点,核心价值体现在:
1. 流程模块化拆分,降低耦合与维护成本
将复杂流程按业务逻辑拆分为多个独立的子图(如将智能客服流程拆分为 “意图识别子图”“知识库检索子图”“人工介入子图”),父图仅负责子图的调度与流转控制,每个子图专注于实现单一业务逻辑:修改某一个子图的逻辑(如更换知识库检索的向量数据库),不会影响父图与其他子图的运行;且代码按模块划分,可读性与可维护性大幅提升,即使是复杂流程,也能快速定位与修改问题。
2. 子图逻辑复用,提升开发效率
将企业通用的子逻辑封装为可复用的子图(如 “敏感信息校验子图”“文本向量检索子图”“人工审核子图”),在不同的父图中可直接调用这些子图,无需重复开发:例如智能客服流程和合同审查流程可共用 “敏感信息校验子图”,只需在父图中配置调用逻辑即可;且子图可单独维护与优化,优化后所有调用该子图的父图都会同步受益,大幅降低开发与维护成本。
3. 多智能体协作分层管控,实现有序协同
在多智能体协作场景中,将每个智能体的工作流程封装为子图,父图作为 “智能体调度中心”,负责根据业务逻辑调用不同的智能体子图、接收子图的执行结果并进行下一步决策:例如项目评估流程中,父图先调用 “数据分析师智能体子图” 完成数据收集与分析,再将结果传递给 “法务智能体子图” 进行风险评估,最后由 “财务智能体子图” 完成成本核算;父图可实时监控每个子图的执行状态,实现多智能体的有序协同。
4. 精细化的状态管理与流程控制
父子图架构下,父图与子图拥有独立的状态存储(基于 LangGraph 的 Checkpoint 机制),可实现对流程的精细化控制:
- 子流程独立执行:父图调用子图时,子图可在独立的上下文环境中执行,不会污染父图的全局状态;
- 子流程单独管控:可针对某个子图单独进行暂停、重启、回滚操作(如 “数据分析子图” 执行失败,仅重启该子图即可,无需重新运行整个流程);
- 权限精细化配置:可为不同的子图配置不同的访问权限(如 “财务审核子图” 仅允许财务人员访问,“法务审核子图” 仅允许法务人员访问),满足企业的权限管控要求。
5. 流程灵活扩展,适配业务变化
父子图架构支持 “即插即用” 的流程扩展:新增业务步骤时,只需开发对应的子图,在父图中添加调用逻辑即可,无需修改原有流程;还支持引入外部子图(如第三方开发的行业专用子图),快速扩展流程能力。例如,合同审查流程需新增 “跨境条款校验” 步骤,只需开发该子图并在父图的 “条款校验” 节点后调用,即可完成扩展,不影响原有流程的运行。
6. 可视化层级化展示,提升流程可理解性
LangGraph 提供可视化工具,父子图架构可实现流程的层级化展示:父图展示主流程的整体流转逻辑,子图展示具体的子步骤细节,点击父图中的子图节点可展开查看子图的内部结构。这使得非技术人员(如产品经理、业务人员)也能清晰理解复杂流程的逻辑,便于业务与技术团队的协作。
3.LangGraph 父子图构建的典型应用场景
-
企业级智能客服全流程将智能客服流程拆分为父图(用户对话主流程:意图识别→问题处理→结果反馈)与子图(意图识别子图、知识库检索子图、人工介入子图、语音转文字子图)。父图根据用户输入调用对应的子图,子图完成具体操作后将结果返回父图,实现客服流程的模块化管理与灵活扩展。
-
多智能体协同的合同审查流程父图作为合同审查主流程(合同上传→条款拆分→多智能体审核→报告生成),子图为各智能体的工作流程(文本提取子图、法务审核子图、财务审核子图、敏感信息校验子图)。父图调度不同的子图协同工作,完成全流程合同审查,同时可单独管控每个子图的执行状态。
-
多步骤大数据分析流程将数据分析流程拆分为父图(数据处理主流程:数据采集→数据清洗→数据分析→报告生成)与子图(数据采集子图、数据清洗子图、SQL 分析子图、可视化报告子图)。每个子图负责一个数据处理步骤,父图控制整体流转,若某个子步骤失败,可单独重启该子图,提升流程执行效率。
-
跨部门业务审批流程父图作为审批主流程(提交申请→部门审核→财务审核→总经理审批→结果通知),子图为各部门的审核流程(技术部门审核子图、财务部门审核子图、行政部门审核子图)。不同部门的审核逻辑封装在对应的子图中,父图根据审批规则调用子图,实现跨部门审批的模块化与标准化。
-
多模态内容生成流程将内容生成流程拆分为父图(需求解析→内容生成→合规校验→输出结果)与子图(文本生成子图、图片生成子图、视频脚本生成子图、敏感信息校验子图)。父图根据用户的多模态需求调用对应的子图,完成内容生成与校验,实现多模态流程的分层管理。
4.关键优势总结
LangGraph 父子图构建的核心价值,是将复杂的大模型流程从 “单一的扁平结构” 转化为 “模块化的层级结构”:既解决了单一图结构耦合度高、复用性差、管控难的痛点,又通过模块化拆分与分层管控,实现了流程的高效开发、灵活扩展与精细化管理。这一能力让 LangGraph 能够适配企业级的复杂业务场景,成为大模型应用从 “单一流程演示” 走向 “复杂业务落地” 的关键技术支撑。
综上,LangGraph 父子图构建的需求,源于企业对大模型流程 “模块化、复用性、可管控性” 的核心诉求:解决了单一图结构在复杂流程编排中的诸多痛点,支撑智能客服、多智能体协作、大数据分析等企业级核心场景,为复杂大模型应用的稳定落地与高效维护提供了可靠的技术路径。
二.具体实现
1.引入依赖
import sys
import io
# 设置标准输出编码为UTF-8,解决Windows中文乱码问题
if sys.platform == 'win32':
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
from IPython.display import Image, display
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.graph.state import CompiledStateGraph
from typing_extensions import TypedDict
import threading
import time
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
from langgraph.types import interrupt
from langgraph.types import Command
from langgraph.checkpoint.memory import MemorySaver
2.定义状态类
class EventState(TypedDict):
count_status: int #累计计数状态
3.定义节点1,节点2
def first_node(state: EventState) -> EventState:
state["count_status"] += 1
print("当前计数状态:", state["count_status"])
return state
def second_node(state: EventState) -> EventState:
state["count_status"] += 2
print("当前计数状态:", state["count_status"])
return state
4.定义子图1,子图2
memory = MemorySaver()
# 创建事件流
graph = StateGraph(EventState)
graph.add_node("first_node", first_node)
graph.add_node("second_node", second_node)
graph.add_edge(START, "first_node")
graph.add_edge("first_node", "second_node")
graph.add_edge("second_node", END)
graph = graph.compile(checkpointer=memory)
graph02 = StateGraph(EventState)
graph02.add_node("first_node", first_node)
graph02.add_node("second_node", second_node)
graph02.add_edge(START, "first_node")
graph02.add_edge("first_node", "second_node")
graph02.add_edge("second_node", END)
graph02 = graph02.compile(checkpointer=memory)
5.定义父图
graph03 = StateGraph(EventState)
graph03.add_node("first_node", graph)
graph03.add_node("second_node", graph02)
graph03.add_edge(START, "first_node")
graph03.add_edge("first_node", "second_node")
graph03.add_edge("second_node", END)
graph03 = graph03.compile(checkpointer=memory)
6.执行图流程
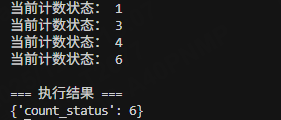
state = {"count_status": 0}
rs = graph03.invoke(state, config=config)
print("\n=== 执行结果 ===")
print(rs)
执行结果如下:


















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











