 LangGraph长记忆实现与应用
LangGraph长记忆实现与应用




一.背景
LangGraph 作为 LangChain 生态中专注于大模型流程编排与多轮交互的核心框架,其核心优势是通过有向图结构实现复杂流程的动态流转与状态管理。但在企业级长期运行场景中,单一图流程的 “短期记忆”(仅保留当前流程执行周期内的状态)已无法满足需求,因此 “长记忆(Long-term Memory)” 的引入成为必然 —— 本质是将图流程的关键状态(节点执行记录、上下文数据、决策路径)持久化存储并灵活复用,突破 “单次流程执行即失忆” 的限制。这一能力的需求源于 LangGraph 原生记忆机制在复杂场景中的痛点,也是其适配 “长期多轮交互、跨流程协同、历史数据依赖” 企业级诉求的关键升级。
1.LangGraph 原生记忆机制的核心痛点
LangGraph 原生的记忆机制以 “单次流程执行” 为单位,流程结束后仅保留最终状态(或通过 Checkpoint 保留有限历史),缺乏对 “长期、跨流程” 记忆的管理能力,在以下场景中痛点突出:
1. 长期多轮交互场景中,上下文断裂
在需要持续交互的场景(如智能助手、客户服务、项目协作)中,用户需求往往分散在多次流程执行中:例如用户第一天通过 LangGraph 图流程咨询 “项目进度”,第二天继续追问 “补充上周的研发数据”,原生记忆机制无法关联两次流程的上下文,导致大模型无法识别 “上周研发数据” 对应的是前序咨询的项目,需用户重复说明背景,交互体验极差;且多次交互的历史信息(如用户偏好、已确认的需求)无法复用,流程需重复处理相同信息,效率低下。
2. 跨流程协同场景中,数据无法共享
企业级复杂业务往往需要多个独立 LangGraph 图流程协同完成(如 “需求收集图”“方案设计图”“审批图” 协同支撑项目立项),原生记忆机制下,每个图流程的状态仅保存在自身执行周期内,无法实现跨图数据共享:例如 “方案设计图” 需要获取 “需求收集图” 中的用户需求细节,只能通过手动传递参数或外部数据库存储,不仅开发成本高,还易出现数据不一致;且跨图流程的执行轨迹无法关联,难以追溯 “需求→方案→审批” 的全链路历史。
3. 历史依赖型场景中,缺乏数据支撑
部分图流程的执行高度依赖历史数据(如趋势分析、风险监控、用户行为预测):例如基于 LangGraph 构建的 “业务数据监控图”,需对比近 30 天的每日数据波动来判断是否触发告警;“用户行为分析图” 需结合用户过去一个月的交互记录生成个性化报告。原生记忆机制无法长期存储这些历史数据,需额外对接外部存储并手动编写数据查询逻辑,导致流程复杂度剧增,且数据访问效率低。
4. 流程中断后恢复,状态完整性不足
LangGraph 虽支持通过 Checkpoint 恢复单次流程的中断状态,但无法保留 “跨中断周期” 的长期记忆:例如项目协作图流程因假期中断,复工后恢复流程时,仅能获取中断时的即时状态,无法追溯该项目前序多次交互的历史信息(如之前确认的需求变更、已达成的共识),导致流程恢复后需重新梳理背景,浪费时间;且若流程需跨多个中断周期(如分阶段推进的项目),原生记忆机制无法串联各阶段的状态,流程连贯性差。
5. 大模型上下文窗口受限,长文本记忆难
大模型存在上下文窗口限制,即使 LangGraph 图流程在单次执行中拆分节点,也无法将超长历史交互信息(如数万字的多轮对话、数十次流程的执行记录)全部纳入当前上下文。原生记忆机制缺乏对长记忆的 “摘要、提炼、按需召回” 能力,导致大模型无法利用长期历史信息辅助决策,仅能基于当前节点的短期数据生成结果,准确性与针对性不足。
2.LangGraph 图中使用长记忆的核心价值
LangGraph 图中引入长记忆,本质是通过 “持久化存储 + 智能检索 + 记忆管理” 机制,将短期流程状态扩展为长期可复用的结构化记忆,解决原生机制的痛点,核心价值体现在:
1. 支撑长期多轮交互,保持上下文连贯性
长记忆可持久化存储多次图流程执行的关键信息(用户输入、节点输出、决策结果、交互偏好),后续流程执行时可自动召回相关历史记忆:例如用户多次咨询同一项目时,长记忆会关联所有交互记录,大模型无需用户重复说明即可理解上下文;智能助手场景中,长记忆可记录用户的使用习惯(如偏好的报告格式、关注的核心指标),后续流程自动适配,交互体验大幅提升。
2. 实现跨流程记忆共享,打通协同链路
长记忆可作为独立的 “记忆中心”,供多个 LangGraph 图流程访问:例如 “需求收集图” 将用户需求存储至长记忆后,“方案设计图”“审批图” 可直接从长记忆中读取相关数据,无需手动传递;跨图流程的执行轨迹会统一记录在长记忆中,可追溯 “需求提交→方案生成→审批通过” 的全链路历史,便于故障排查与合规审计。
3. 提供历史数据支撑,优化决策准确性
长记忆可长期存储流程执行的历史数据(如每日业务指标、风险检测结果、用户行为记录),图流程中的分析类节点可直接调用这些数据进行趋势分析、对比判断:例如业务监控图流程中,节点可从长记忆中读取近 30 天的历史数据,对比当前数据波动是否异常,避免仅基于单点数据误判;用户行为分析图流程可利用长期行为数据构建更精准的用户画像,提升分析结果的针对性。
4. 增强流程中断恢复能力,保障连贯性
长记忆不仅存储单次流程的中断状态,还会保留该业务的全量历史记忆:例如项目协作图流程中断多日后恢复时,可从长记忆中召回项目启动至今的所有交互记录、已完成节点、未解决问题,流程无需重新梳理背景,直接从中断节点结合历史记忆继续执行;跨多个中断周期的流程,可通过长记忆串联各阶段状态,保持执行连贯性。
5. 突破大模型上下文限制,高效利用长文本记忆
长记忆具备 “记忆摘要与按需召回” 能力:对于超长历史记录(如数万字的多轮对话),会自动提炼核心信息生成摘要存储,避免占用过多存储资源;当图流程需要时,仅将与当前任务相关的记忆片段(而非全部历史)召回至大模型上下文,既突破了上下文窗口限制,又保证了大模型决策的高效性与准确性。
3.典型应用场景
-
长期智能助手 / 客户服务:企业内部智能助手需长期响应员工的项目咨询、流程查询,长记忆可记录员工的咨询历史、项目背景、偏好设置,实现 “一次说明、长期复用” 的交互体验;客户服务场景中,长记忆存储客户的历史诉求、处理记录,后续服务无需重复询问基础信息,提升服务效率。
-
跨流程项目协作:项目立项、需求收集、方案设计、审批落地等多个 LangGraph 图流程协同时,长记忆作为共享数据中心,打通各流程的信息壁垒,确保项目全生命周期的信息连贯性与一致性。
-
长期业务监控与分析:基于 LangGraph 构建的业务监控、数据趋势分析流程,需依赖长期历史数据(如月度销售数据、季度风险指标),长记忆可持久化存储这些数据,支撑跨时间维度的分析与决策。
-
个性化内容生成与推荐:内容生成类图流程(如报告生成、方案推荐)可通过长记忆记录用户的个性化需求(如报告格式、关注重点、行业偏好),长期生成贴合用户需求的内容,无需每次手动配置。
-
多智能体长期协作:多个智能体通过 LangGraph 图流程协同完成长期任务(如长期项目评估、持续法务合规审查),长记忆可存储各智能体的协作历史、决策依据、已处理事项,确保多智能体协作的连贯性与一致性。
4.关键优势总结
LangGraph 图中使用长记忆的核心价值,是将图流程从 “单次执行的独立单元” 转化为 “长期演进的智能系统”:既解决了原生记忆机制在长期交互、跨流程协同、历史数据依赖场景中的痛点,又通过智能记忆管理突破了大模型上下文限制,提升了流程的连贯性、准确性与用户体验。这一能力让 LangGraph 能够适配更复杂的企业级长期运行场景,成为大模型应用从 “单次任务处理” 走向 “长期智能服务” 的关键技术支撑。
综上,LangGraph 图中使用长记忆的需求,源于企业对大模型流程 “长期化、协同化、个性化” 的核心诉求:解决了原生记忆机制的诸多痛点,支撑智能助手、项目协作、业务监控等核心场景,为复杂大模型应用的长期稳定运行提供了高效、可靠的技术路径。
二.具体实现
1.添加依赖
# -*- coding: utf-8 -*-
import sys
import io
# 设置标准输出编码为UTF-8,解决中文乱码问题
if sys.platform == 'win32':
# Windows系统设置控制台编码为UTF-8
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
# 设置环境变量
import os
os.environ['PYTHONIOENCODING'] = 'utf-8'
from langchain.embeddings import init_embeddings
from langgraph.store.memory import InMemoryStore
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.graph.state import CompiledStateGraph
from typing_extensions import TypedDict
from langgraph.store.base import BaseStore
from langgraph.checkpoint.memory import MemorySaver
2.定义代理使用向量模型
def init_embeddings_with_proxy(
model: str,
proxy_url: str = None,
proxy_key: str = None
):
"""
初始化embeddings,支持代理OpenAI的URL和key
# 设置代理OpenAI的base URL
if proxy_url:
os.environ["OPENAI_API_BASE"] = proxy_url
# 设置代理服务的API key
if proxy_key:
os.environ["OPENAI_API_KEY"] = proxy_key
# 初始化embeddings
return init_embeddings(model)
3.定义向量化存储
embeddings = init_embeddings_with_proxy(
"openai:text-embedding-3-small",
proxy_url="", # 代理OpenAI的URL
proxy_key="" # 代理服务的API key
)
store = InMemoryStore(
index={
"embed": embeddings,
"dims": 1536,
}
)
4.定义状态类
# 1. 定义状态
class EventState(TypedDict):
count_status: int #累计计数状态
5.定义节点1,存储记忆
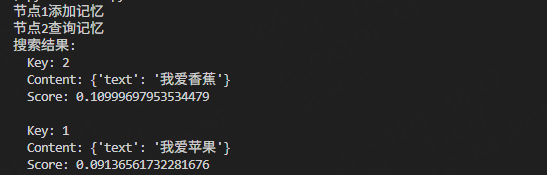
def first_node(state: EventState, *, store: BaseStore) -> EventState:
state["count_status"] += 1
print("节点1添加记忆")
store.put(("user_123", "memories"), "1", {"text": "我爱苹果"})
store.put(("user_123", "memories"), "2", {"text": "我爱香蕉"})
return state
6.定义节点2,查询记忆
def second_node(state: EventState, *, store: BaseStore) -> EventState:
state["count_status"] += 3
print("节点2查询记忆")
items = store.search(
("user_123", "memories"), query="我喜欢吃什么水果", limit=2
)
# 打印搜索结果
print("搜索结果:")
for item in items:
print(f" Key: {item.key}")
print(f" Content: {item.value}")
print(f" Score: {item.score}")
print()
return state
7.定义图执行
# 初始化状态
state = {"count_status": 0}
# 创建事件流
graph = StateGraph(EventState)
graph.add_node("first_node", first_node)
graph.add_node("second_node", second_node)
graph.add_edge(START, "first_node")
graph.add_edge("first_node", "second_node")
graph.add_edge("second_node", END)
memory = MemorySaver()
graph = graph.compile(checkpointer=memory, store=store)
config = {"configurable": {"thread_id": "thread-155"}}
graph.invoke(state, config=config)
结果如下:


















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











