




文章目录
前言
08/21周四开启的本周学习,加上已经落下了许多课程,前期学习目标较为繁多。
学习目标
- 【第一周】深度学习基础
- 【第二周】卷积神经网络
- 【第三周】ResNet+ResNeXt
- 《神经网络与深度学习》复旦大学 邱锡鹏 阅读(快速阅读两周,精读两周)(now: 快速阅读week01)。
- 丛润民老师的《深度学习课程》学习
(分两周进行,now: week01)
学习内容
【第一周】深度学习基础
1. 视频学习
1.1 绪论
- 从专家系统到机器学习
- 从传统机器学习到深度学习
- 深度学习的能与不能
1.2 深度学习概述
- 浅层神经网络:生物神经元到单层感知器,多层感知器,反向传播和梯度消失
- 神经网络到深度学习:逐层预训练,自编码器和受限玻尔兹曼机
2. 代码练习
代码练习参照教程使用谷歌的 Colab,虽然免费但是限额,newtask:寻找其他可供替代的炼丹环境。
2.1 pytorch 基础练习
基础练习部分包括 pytorch 基础操作,
任务要求: 把代码输入colab,在线运行观察效果,关键步骤截图,并附⼀些自己的想法和解读。
对于有Python语言使用经验的人来说算是入门难度。
第一部分在colab上运行的时候忘记截图了,加上colab其实不是很好用,随即在yao37的帮助下用他的v100跑了(08/22),如下:
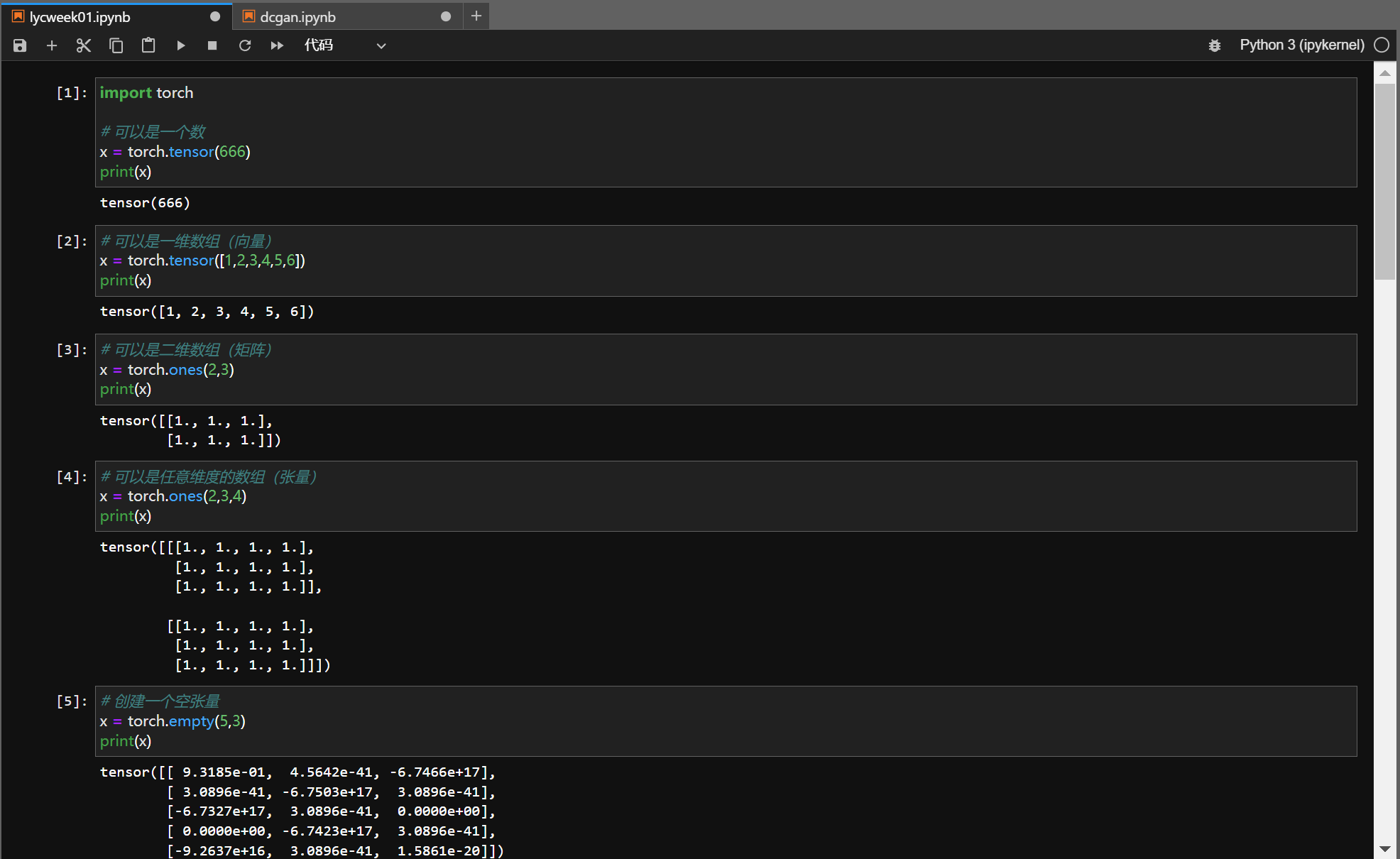
基本没什么问题,照本宣科即可。
一点小问题:
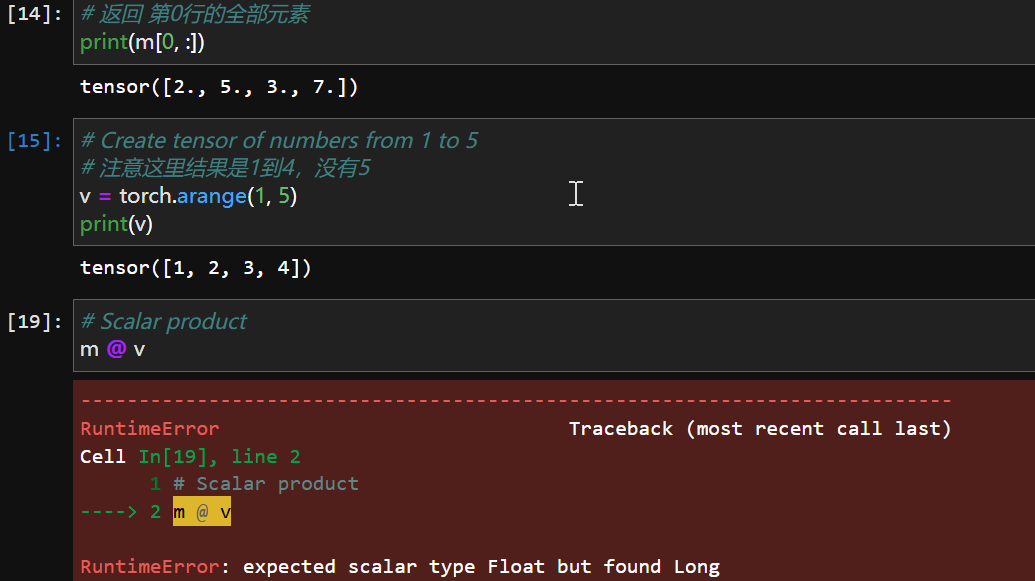
这里报错了,不过没关系,刚好学习怎么看pytorch的报错:其实还是python
Cell In[19], line 2
1 # Scalar product
----> 2 m @ v
在第十九个单元格第二行抛出了一个RuntimeError,
箭头指出了错误的位置,
后面有具体的修改信息:
RuntimeError: expected scalar type Float but found Long
报错说这里的标量类型应该是Float,但是实际上是Long,所以他抛出了异常,所以其实修改起来非常简单,.float()即可,顺带一提,在 PyTorch 中,“标量类型”(scalar type) 指的是张量中每个元素的数据类型(data type)。
修改之后一切正常。
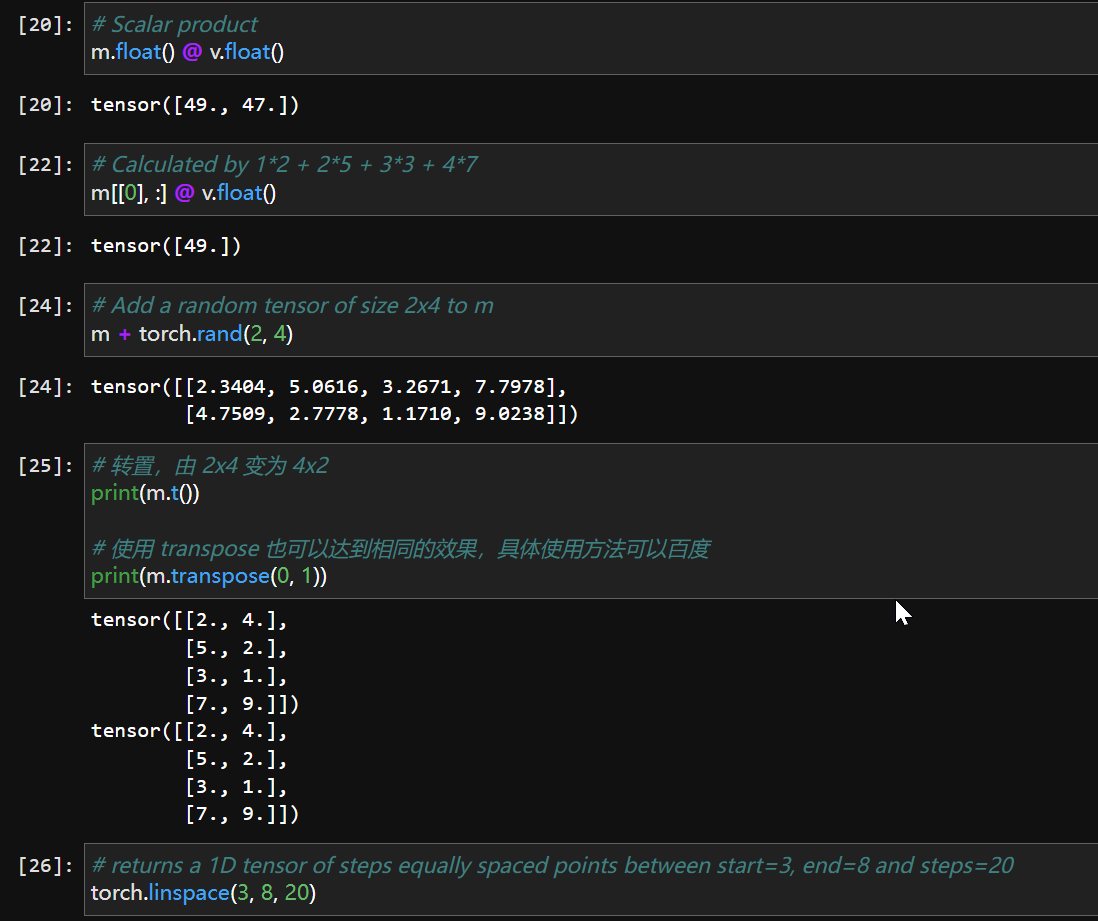
coding部分结束,以下是简述:
PyTorch是一个python深度学习库,
它主要提供了两个高级功能:
- GPU加速的张量计算
- 构建在反向自动求导系统上的深度神经网络
看不懂没关系,后面慢慢理解。
一般定义数据使用torch.Tensor , tensor的意思是张量,是数字各种形式的总称,
可以理解为pytorch库内置了一个数据类型,名字是tensor。
基本操作
凡是用Tensor进行各种运算的,都是Function,
最终,还是需要用Tensor来进行计算的,计算无非是:
基本运算,加减乘除,求幂求余
布尔运算,大于小于,最大最小
线性运算,矩阵乘法,求模,求行列式
Function很多,功能很强大,不过不用背书,
需要使用的时候谷歌一下或者查阅文档 PyTorch中文文档 都可,熟能生巧。
2.2 螺旋数据分类
实验目的: ⽤神经⽹络实现简单数据分类,
任务要求: 把代码输入colab,在线运⾏观察效果,关键步骤截图,并附⼀些⾃⼰的想法和解读。
过程中有点小瑕疵,刚起步深度学习,很多知识只是听闻而没有实践,这次有幸尝试:
先是缺少一张在res里的图片,解决方案很简单,在jupyter同级目录中新建一个res,里面放置
ziegler.png即可。
程序正常运行:
跟2.1的熟悉pytorch操作不同,本节已经确实的有了实验的味道,所以我们不妨来熟悉一下代码:
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
# 因为colab是支持GPU的,torch 将在 GPU 上运行
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device: ', device)
# 初始化随机数种子。神经网络的参数都是随机初始化的,
# 不同的初始化参数往往会导致不同的结果,当得到比较好的结果时我们通常希望这个结果是可以复现的,
# 因此,在pytorch中,通过设置随机数种子也可以达到这个目的
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量
先是引入库,具体作用之后碰到了再解释。
cuda是GPU的接口,在检测有无GPU,没有的话就用cpu。
接下来是超参的设置,都给了对应的注释。
关于随机数:
启发式算法都多少带点随机性,这也让其饱受诟病,但就目前发展前景来看,神经网络表现得确实不错,
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
顺带一提,上面这两个给GPU设置随机数种子的算法也会用到。
调超参也是炼丹的一大快乐之处呢
X = torch.zeros(N * C, D).to(device)
Y = torch.zeros(N * C, dtype=torch.long).to(device)
for c in range(C):
index = 0
t = torch.linspace(0, 1, N) # 在[0,1]间均匀的取10000个数,赋给t
# 下面的代码不用理解太多,总之是根据公式计算出三类样本(可以构成螺旋形)
# torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 每个样本的(x,y)坐标都保存在 X 里
# Y 里存储的是样本的类别,分别为 [0, 1, 2]
for ix in range(N * c, N * (c + 1)):
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index])))
Y[ix] = c
index += 1
print("Shapes:")
print("X:", X.size())
print("Y:", Y.size())
'''out:
Shapes:
X: torch.Size([3000, 2])
Y: torch.Size([3000])
'''
这段代码的目的十分明显,是用 pytorch 生成一个用于分类任务的 螺旋形(spiral)数据集,用来测试神经网络的非线性分类能力。
X是所有样本的坐标,Y是样本的类别标签。(Y设成long了,应该是方便算loss)
linspace 函数在区间 [0, 1] 上创建包含 N 个等间距值的张量
例如,如果 N=5,则 t = [0.0, 0.25, 0.5, 0.75, 1.0]#这里N=1000,间距就是0.001
虽然接下来的code老师说不用理解,但来都来了~
前面的linspace显然是按角度给三组数据分类,后面+ torch.randn(N) * 0.2
是加上高斯噪声,让点不完全在理想曲线上(模拟真实数据噪声)
torch.randn(N)实际上生成了 N 个来自标准正态分布的随机数,
*0.2是在调噪声的标准差,可以理解为使数据点围绕理想螺旋线随机偏移约 ±0.2 弧度
总而言之,这部分代码生成了一个带噪声的三螺旋分类数据集。
# visualise the data
plot_data(X, Y)
'''out:photo1
'''
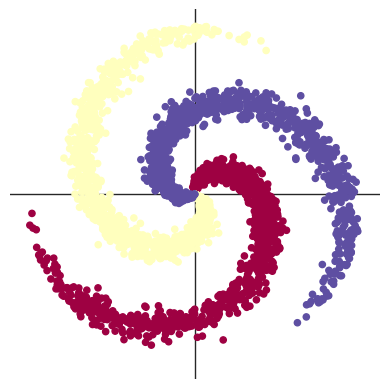
数据可视化~
learning_rate = 1e-3
lambda_l2 = 1e-5
# nn 包用来创建线性模型
# 每一个线性模型都包含 weight 和 bias
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
# nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数
criterion = torch.nn.CrossEntropyLoss()
# 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播前把梯度置 0
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer.step()
'''out:
[EPOCH]: 999, [LOSS]: 0.861541, [ACCURACY]: 0.504
'''
learning_rate 设置了优化算法的学习率,这里为0.001。
lambda_l2 是L2正则化的权重衰减系数,用来防止过拟合,值为0.00001。
跟其他启发式算法类似的,超参基本都没什么逻辑可言,主要看经验。
输入维度 D ,隐藏层维度 H,输出维度 C
criterion = torch.nn.CrossEntropyLoss()
损失函数用交叉熵~(损失函数也是深度学习的重点,会专门出一期blog讲解)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
优化器用SGD(随机梯度下降),设置了学习率和L2正则化项的权重衰减系数。
后面的代码挺详细了:
-
- 循环执行1000次迭代,进行模型训练。
- 前向传播、计算损失和准确率:
- 前向传播得到预测结果
y_pred。 - 计算预测值与真实标签之间的损失
loss和准确率acc。
- 前向传播得到预测结果
- 反向传播和参数更新:
- 在每次迭代中,先调用
optimizer.zero_grad()清除之前的梯度信息。 - 然后通过
loss.backward()执行反向传播,计算梯度。 - 最后调用
optimizer.step()根据计算得到的梯度更新模型参数。
- 在每次迭代中,先调用
- 输出训练状态:
- 每轮迭代结束后,打印当前的迭代次数、损失值以及准确率,使用
display.clear_output(wait=True)动态更新显示内容。
- 每轮迭代结束后,打印当前的迭代次数、损失值以及准确率,使用
可以发现我又讲了一堆废话,but对于初学者来说这玩意当然不是废话,每一步做了什么,为什么做,预期结果估计都应该明白,但我们现在先把他们列出来,表示这里其实可以探究一下他的机理(也可能大多数时候都并不必要,毕竟底层代码的维护又是另一个世界了)
print(y_pred.shape)
print(y_pred[10, :])
print(score[10])
print(predicted[10])
'''out:
torch.Size([3000, 3])
tensor([-0.2245, -0.2594, -0.2080], device='cuda:0', grad_fn=<SliceBackward0>)
tensor(-0.2080, device='cuda:0', grad_fn=<SelectBackward0>)
tensor(2, device='cuda:0')
'''
随便挑了一个样本看看效果(也可能另有深意但我水平太菜看不出来)
# Plot trained model
print(model)
plot_model(X, Y, model)
'''out:photo2
Sequential(
(0): Linear(in_features=2, out_features=100, bias=True)
(1): Linear(in_features=100, out_features=3, bias=True)
)
'''
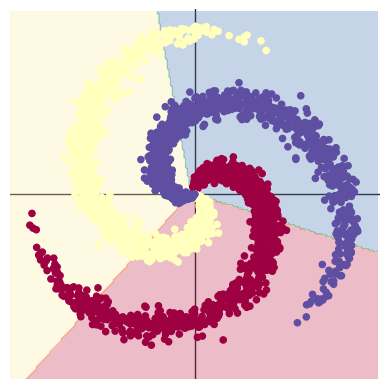
看了看网络结构,然后可视化了一下,可以发现效果非常糟糕,完全的线性划分。
learning_rate = 1e-3
lambda_l2 = 1e-5
# 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
model.to(device)
# 下面的代码和之前是完全一样的,这里不过多叙述
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2
# 训练模型,和之前的代码是完全一样的
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = ((Y == predicted).sum().float() / len(Y))
print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc))
display.clear_output 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 804
804




 到【灌水乐园】发言
到【灌水乐园】发言








{kind=link}