 CNN与LeNet在图像分类中的实践
CNN与LeNet在图像分类中的实践




文章目录
| 姓名和学号? | 刘翼晨,24020007077 |
|---|---|
| 本实验属于哪门课程? | 中国海洋大学25秋《软件工程原理与实践》 |
| 实验名称? | 实验3 卷积神经网络 |
| 博客链接: | 新芽-深度学习-week02 |
一、代码练习
实验3: 使用CNN对MINIST数据集分类
代码分析
'''
get_n_params:get number of parameters
函数接收一个参数 model,要求是一个 PyTorch 的神经网络模型对象(例如,torch.nn.Module 的实例)。
model.parameters(): 这是 PyTorch 模型的一个方法,它会返回一个生成器(generator),包含模型中所有需要梯度更新的参数(例如,卷积层的权重和偏置、全连接层的权重和偏置等)。
list(...): 将生成器转换为一个列表,以便在 for 循环中遍历。
for p in ...: 遍历模型中的每一个参数张量(p 是一个 torch.Tensor 对象)。例如,一个卷积层的权重张量可能是一个 4D 张量 (out_channels, in_channels, kernel_height, kernel_width)。
p.nelement(): 这是 PyTorch 张量(Tensor)的一个方法,它返回该张量中元素的总个数。例如:
一个形状为 (3, 4) 的二维张量有 3 * 4 = 12 个元素。
一个形状为 (64, 3, 3, 3) 的卷积核张量有 64 * 3 * 3 * 3 = 1728 个参数。
'''
# 一个函数,用来计算模型中有多少参数
def get_n_params(model):
np=0
for p in list(model.parameters()):
np += p.nelement()
return np
这个函数可以用来简单地评估模型复杂度:参数越多,模型通常越复杂,计算量越大,也更容易过拟合。比较熟练的选手也可以通过参数来进行资源预估:估算模型训练和推理时的内存占用(参数是内存消耗的主要部分之一)。
注意:这个函数只计算 requires_grad=True 的参数(即参与梯度更新的参数)。如果模型中有不需要更新的参数(例如冻结的层),它们不会被计入。
'''
数据集加载的内容我们不展示了,稍微提一下这两个变量
input_size = 28*28: 定义了模型的输入大小。MNIST 数据集中的每张图片都是 28 像素 × 28 像素的灰度图像,所以展平后(flattened)有 784 个输入特征。
output_size = 10: 定义了模型的输出大小。MNIST 有 10 个类别(数字 0 到 9),因此模型最终需要输出一个长度为 10 的向量,表示图片属于每个类别的概率。
这两个变量通常用于后续定义神经网络的输入层和输出层的大小。
'''
input_size = 28*28 # MNIST上的图像尺寸是 28x28
output_size = 10 # 类别为 0 到 9 的数字,因此为十类
'''
这里用 Matplotlib 库来可视化 MNIST 训练数据集
建议大家熟悉一下 Matplotlib 库。(有机会我们会专门开一个week来讲这个库)
源代码如下,但有两个点可以注意一下,
一是image.squeeze().numpy()可以写成image.squeeze(),因为
从 Matplotlib 3.4 版本开始,它增加了对 PyTorch Tensor 的原生支持。
这意味着你可以直接将一个 torch.Tensor 传递给 imshow,它会自动进行内部转换。
二是plt.axis('off') 后面的分号 ;
分号 ; 在 Jupyter Notebook / JupyterLab 等基于 IPython 的交互式环境中,
主要作用是抑制输出。这个点我们知道就好,用不用无所谓。
'''
plt.figure(figsize=(8, 5))
for i in range(20):
plt.subplot(4, 5, i + 1)
image, _ = train_loader.dataset.__getitem__(i)
plt.imshow(image.squeeze().numpy(),'gray')
plt.axis('off');

以上是图片展示。
后面三个代码块是一个完整的 PyTorch 深度学习实验,用于在 MNIST 手写数字数据集上训练和测试两个不同的神经网络模型:一个全连接网络(FNN)和一个卷积神经网络(CNN),包含了模型定义、训练循环、测试逻辑以及最终的训练和评估。我们这里挑重点说一下。
'''
全连接网络模型 (FC2Layer)
nn.Linear(input_size, n_hidden): 第一个全连接层(输入层到隐藏层)。
ReLU 激活函数
nn.Linear(n_hidden, n_hidden): 第二个全连接层(隐藏层到隐藏层)。
ReLU 激活函数。
nn.Linear(n_hidden, output_size): 输出层,输出 10 个类别的分数。
nn.LogSoftmax(dim=1): 将输出转换为对数概率(logsoftmax我们讲过)dim=1 表示在类别维度上进行归一化。这通常与 F.nll_loss 损失函数配合使用。。
下面的def forward(self, x):
view:一般出现在model类的forward函数中,用于改变输入或输出的形状
x.view(-1, self.input_size) 的意思是多维的数据展成二维,
代码中行数 -1 表示我们不想算,电脑会自己计算对应的数字,
同时指定二维数据的列数为 input_size=784,
在 DataLoader 部分,我们可以看到 batch_size 是64,
所以得到 x 的行数是64,加一行代码:print(x.cpu().numpy().shape)
就可以在训练过程中看到 (64, 784) 的输出,和我们的预期是一致的
forward :该函数的作用是,指定网络的运行过程,虽然这个全连接网络可能看不出啥
意义,但下面的CNN网络就可以看出 forward 的作用。
'''
class FC2Layer(nn.Module):
def __init__(self, input_size, n_hidden, output_size):
super(FC2Layer, self).__init__()
self.input_size = input_size
self.network = nn.Sequential(
nn.Linear(input_size, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
x = x.view(-1, self.input_size)
return self.network(x)
'''
卷积神经网络模型 (CNN)
FNN直接用 Sequential 就定义了网络,我们的 CNN 就特别很多,
卷积层定义:
conv1: 第一个卷积层,输入通道为 1(灰度图),输出 n_feature 个特征图(滤波器),卷积核大小为 5×5。
conv2: 第二个卷积层,输入和输出通道数均为 n_feature。
全连接层定义:
fc1: 第一个全连接层,输入大小为 n_feature*4*4,输出 50 个神经元。
fc2: 输出层,输出 10 个类别的分数。
这是网络里典型结构的一些定义,一般就是卷积和全连接,
池化、ReLU一类的不用在这里定义
下面的def forward(self, x, verbose=False):
可能大家首先注意到这里的forward多出一个verbose的参数,
verbose 是一个可选的调试或日志记录功能,默认为False,
当 verbose=True 时,通常意味着在前向传播过程中打印出中间层的输出形状或一些调试信息,帮助开发者理解数据在网络中的流动和变换过程。
当 verbose=False(默认值)时,这些调试信息不会被打印,保持程序的安静运行。
因为False是默认的,所以这里不写也行,写出来可能是为了突出CNN比较FNN而言是更为复杂的网络结构吧。
前向传播流程:
卷积 + ReLU + 池化:输入图像经过第一个卷积层,然后 ReLU 激活,再经过 2×2 最大池化(降采样)。
卷积 + ReLU + 池化:结果再经过第二个卷积层、ReLU 和最大池化。
展平:经过两次 2×2 池化后,原始 28×28 的图像被缩小为 4×4((28-4)/2/2 = 4)。x.view(-1, self.n_feature*4*4) 将每个样本的特征图展平为一维向量,作为全连接层的输入。
全连接 + ReLU:展平后的向量通过 fc1 , ReLU。
输出层 + LogSoftmax:最后通过 fc2 并使用 F.log_softmax 得到对数概率输出。
注意:FC2Layer 使用了 nn.ReLU()(作为层),而 CNN 使用了 F.relu()(作为函数)。两者功能相同,但用法不同:nn.ReLU 是一个可学习的模块(通常用于 Sequential),F.relu 是一个函数(在 forward 中灵活调用)。
可以发现CNN的forward相当灵活,但里面到底有什么门道,其实我也搞不清楚。
'''
class CNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
super(CNN, self).__init__()
self.n_feature = n_feature
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x, verbose=False):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
训练函数没什么说的,标准的清梯度 → 前向 → 计算损失 → 反向传播 → 更新参数。
测试函数也差不多。
'''
模型实例化、训练与测试:
我们直接将两个网络对比一下
model_fnn:
使用 SGD(随机梯度下降) 优化器,学习率 lr=0.01,动量 momentum=0.5。
打印模型的总参数数量。
调用 train 和 test 函数,对这个全连接网络进行训练和评估。
model_cnn:
n_features: 这是一个超参数,表示卷积层中特征图(feature maps)的数量,也可以理解为卷积核(filters)的数量。
其他超参都相同。
'''
n_hidden = 8 # number of hidden units
model_fnn = FC2Layer(input_size, n_hidden, output_size)
model_fnn.to(device)
optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_fnn)))
train(model_fnn)
test(model_fnn)
# Training settings
n_features = 6 # number of feature maps
model_cnn = CNN(input_size, n_features, output_size)
model_cnn.to(device)
optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_cnn)))
train(model_cnn)
test(model_cnn)
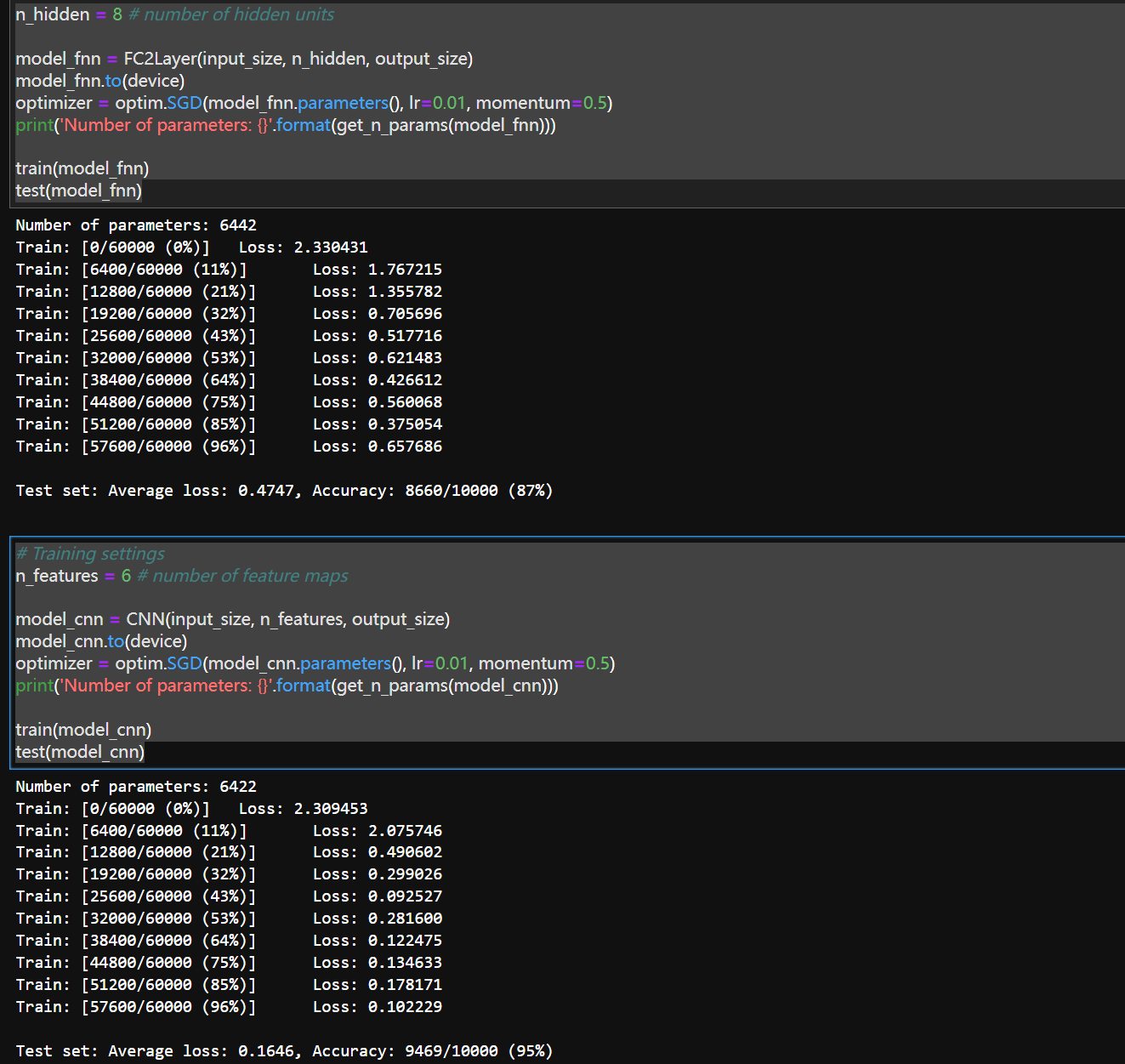
两个网络的训练结果对比,可以发现CNN与FNN相比,不但Average loss更低了,而且 Accuracy也提升了。
tips:
通常,CNN 的参数比同等规模的全连接网络(FNN)少得多,因为它利用了权重共享和局部连接。
但我们可以看到这里的两个网络在超参几乎一样的情况下,CNN(6422)和FNN(6442)并没有什么区别,甚至我们将CNN的特征图加到8(和FNN的隐藏层相同 虽然不能这么比较 ,的情况下,CNN的参数来到了8776,略超FNN)
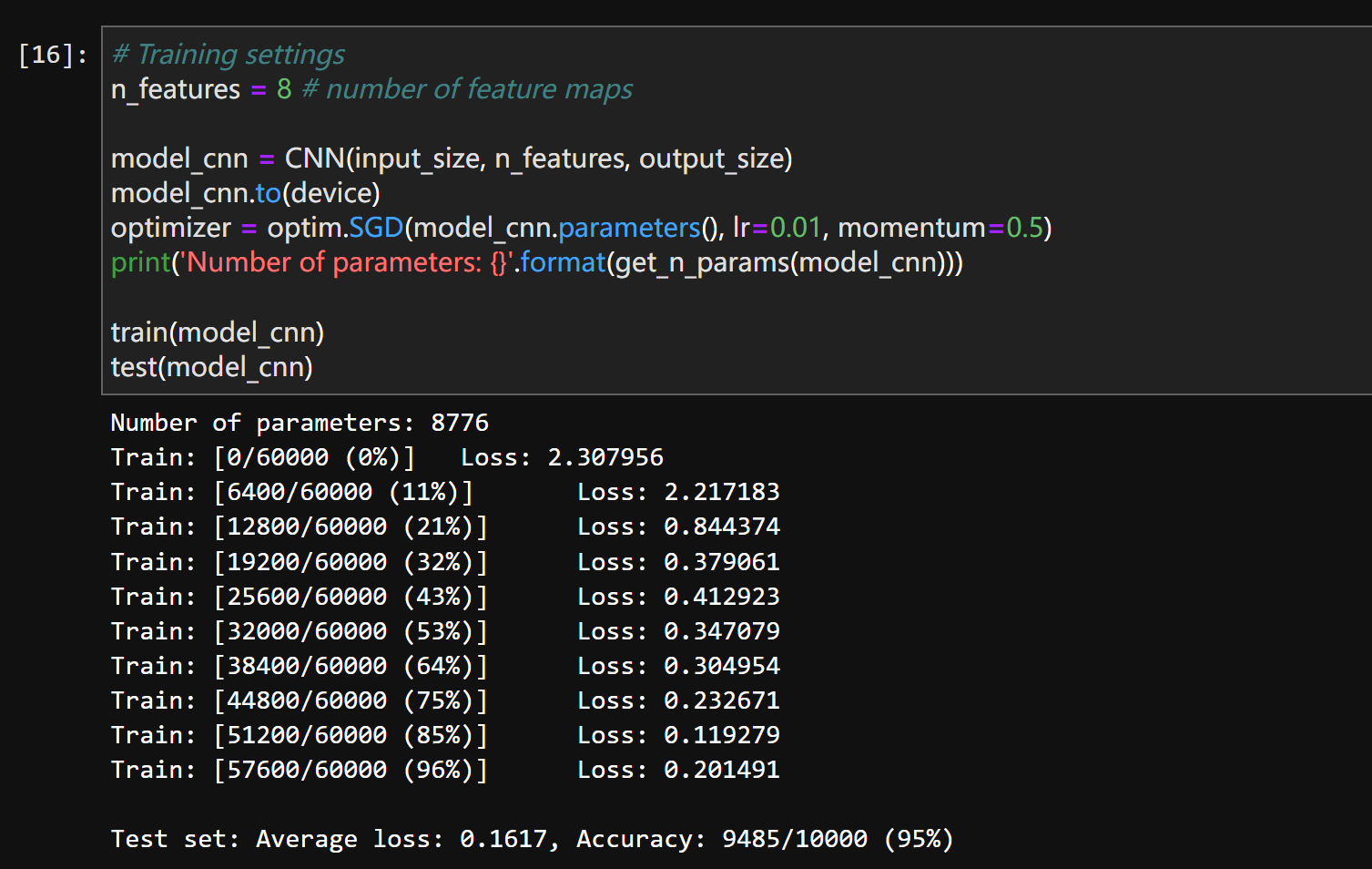
神经网络架构设计–参数分析
这里我们详细讲一下,因为之前的研究中我们还没有探讨过这个问题(这个问题应该属于神经网络架构设计,然而我们的学习实际上还没有到这一步):
在这个特定代码中,FNN (6442) 和 CNN (6422) 的参数数量几乎相同——并不违背“CNN 通常参数更少”的原则,而是因为这里的两个网络在“规模”上根本不是“同等”的。
我们从几个不同角度来剖析这个问题:
1.不同的超参
- FNN 使用了
n_hidden = 8。 - CNN 使用了
n_features = 6。
这两个数字(8 和 6)不是可比的。它们代表了不同类型的“宽度”:
n_hidden = 8:表示全连接网络中隐藏层的神经元数量。这是一个非常小的值。n_features = 6:表示卷积层中特征图的数量。这也是一个很小的值。
问题在于:n_hidden=8 实在是太小了! 一个只有 8 个神经元的全连接网络容量极低,所以它的参数自然也很少。
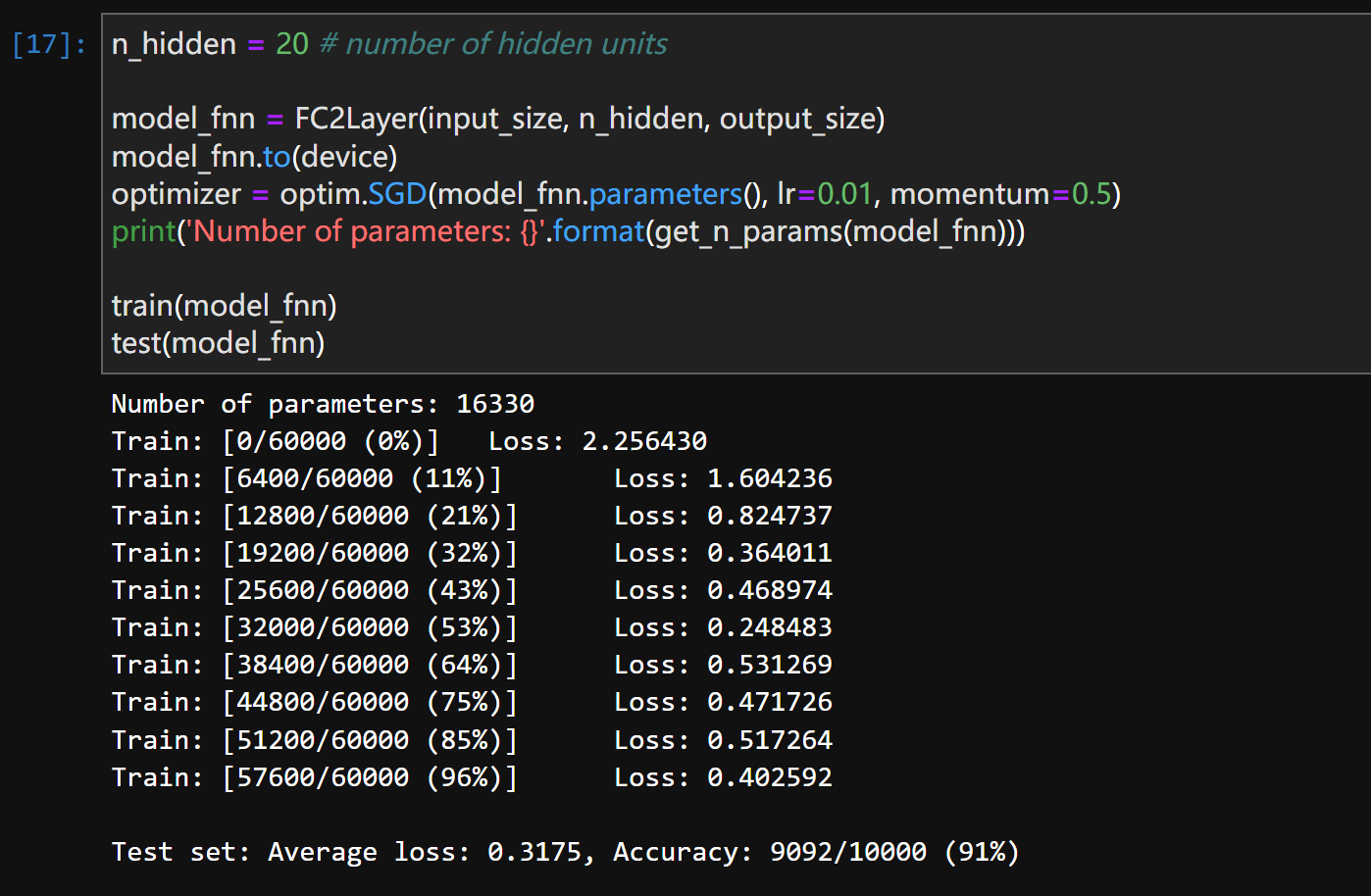
这同时也导致了FNN在这个问题上的较差表现(虽然这并不是根本原因,但提高参数量确实能强化FNN在这个问题上的表现),我们重新调试一下超参:
n_hidden = 20:
n_hidden = 40:
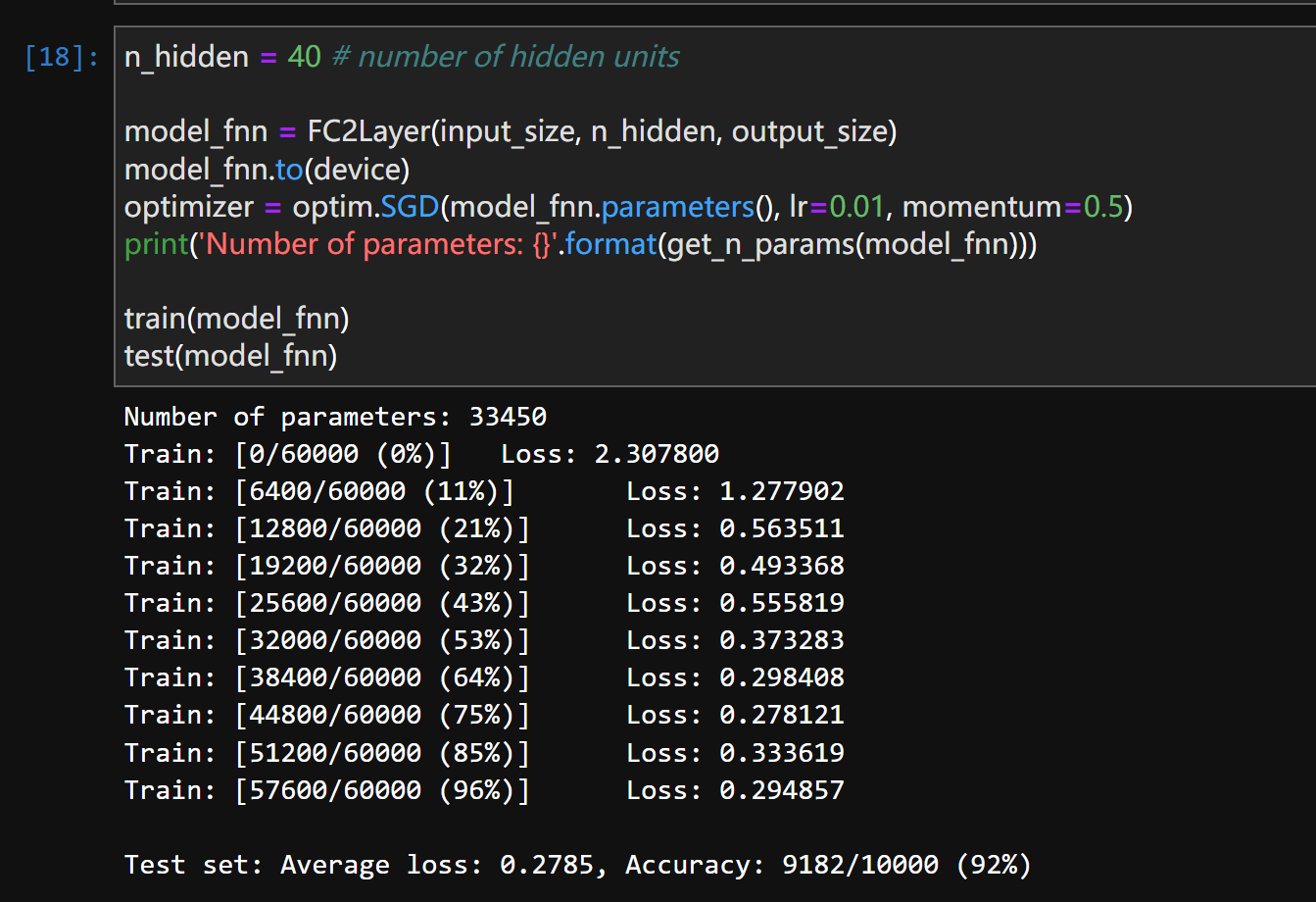
可以发现虽然参数量在增大(6442 ~ 16330 ~ 33450),但最后整个网络其实已经逐渐趋于稳定了,参数量翻了一倍的情况下Average loss,和Accuracy的变化已经不是很大,可以认为在这个问题上无法再通过人为调参来优化网络结果。
值得一提的是,CNN在n_features = 6 时的效果已经远远超过了同参数量的FNN。
2.参数计算详解
我们来手动计算一下这两个模型的参数,这在以后不是必要的工作,但在目前我觉得还是有必要掌握这项基本技能。
FNN (n_hidden = 8):
结构:784 -> 8 -> 8 -> 10
- 第一层 (
784 -> 8):784 * 8 + 8 = 6272 + 8 = 6280(权重 + 偏置) - 第二层 (
8 -> 8):8 * 8 + 8 = 64 + 8 = 72 - 第三层 (
8 -> 10):8 * 10 + 10 = 80 + 10 = 90 - 总计:
6280 + 72 + 90 = 6442
CNN (n_features = 6)
结构:
-
Conv2d(1, 6, 5)→MaxPool→Conv2d(6, 6, 5)→MaxPool→Flatten→Linear(6*4*4, 50)→Linear(50, 10) -
第一个卷积层 (
Conv2d(1, 6, 5)):- 卷积核大小 5×5,输入通道 1,输出通道 6。
- 参数:
(5 * 5 * 1 + 1) * 6 = (25 + 1) * 6 = 26 * 6 = 156(每个卷积核有 25 个权重和 1 个偏置,共 6 个核)
-
第二个卷积层 (
Conv2d(6, 6, 5)):- 卷积核大小 5×5,输入通道 6,输出通道 6。
- 参数:
(5 * 5 * 6 + 1) * 6 = (150 + 1) * 6 = 151 * 6 = 906
-
第一个全连接层 (
fc1: 6*4*4 -> 50):- 展平后大小:
6 * 4 * 4 = 96(因为 28→24→12→10→5→4,两次池化后为 4×4) - 参数:
96 * 50 + 50 = 4800 + 50 = 4850
- 展平后大小:
-
第二个全连接层 (
fc2: 50 -> 10):- 参数:
50 * 10 + 10 = 500 + 10 = 510
- 参数:
-
总计:
156 + 906 + 4850 + 510 = 6422
经过计算我们可以发现:
FNN 的瓶颈:FNN 的第一层 (784 -> 8) 就有 6280 个参数,虽然n_hidden=8 很小,后续层的参数非常少(仅 162 个),但总参数还是被“拖累”到 6442。
CNN 的“大”全连接层:CNN 的卷积层本身参数不多(共 1062),但它连接了一个非常大的全连接层 96 -> 50,这 alone 就贡献了 4850 个参数(请原谅笔者的中英文混编语言),这占了 CNN 的绝大部分参数。**
修改分析:这个 CNN 的参数主要消耗在最后的全连接层,而不是卷积层。这其实违背了 CNN 减少参数的初衷。一个更高效的 CNN 应该用全局平均池化(Global Average Pooling)或更小的全连接层来减少参数。
但仅做练习实验的话,我觉得这也无可厚非,甚至分析CNN的参数优势本来就不是本节课的学习内容。
分析到这里其实这个问题就差不多了,但我们为了给读者加深一下印象,我们不妨再设想一个更公平的网络对比:
- FNN:
784 -> 128 -> 128 -> 10(n_hidden=128)- 参数:
(784*128+128) + (128*128+128) + (128*10+10) ≈ 100K + 16K + 1K = ~117K
- 参数:
- CNN:
Conv(1,32,3) -> Pool -> Conv(32,64,3) -> Pool -> Linear(64*6*6, 128) -> Linear(128, 10)- 参数:
~2K (conv) + ~25K (fc) = ~27K
- 参数:
现在差距就非常明显了:FNN ~117K vs CNN ~27K。CNN 利用局部连接和权重共享的优势完全体现出来。
后面的代码我随意讲一下,实验中单独用来一个代码块来给我们试验 torch.randperm 函数的效果,如下:

代码我们就不看了,他大致做了一件这样的事情,前面十张图是打乱顺序前的图片,后面十张是打乱顺序后的图片,可以发现打乱顺序后人类自己其实也分不出来这张图是什么数字,(bushi)
但有意思的是,我们并非完全随机地打乱数字(虽然你只看代码可能会这样想),我们是先生成一个随机整数排列,然后用这个随机整数排列来对图像的像素点做一个一一映射,所以每一幅映射后的图像,实际上都有着一套完全相同的映射规则。(这也是之后FNN表现不衰减的原因)。
后面的实验大致内容就是我们把训练集和测试集都按这个固定的映射打乱,然后用和之前完全一样的FNN,CNN来测试,观察实验结果:
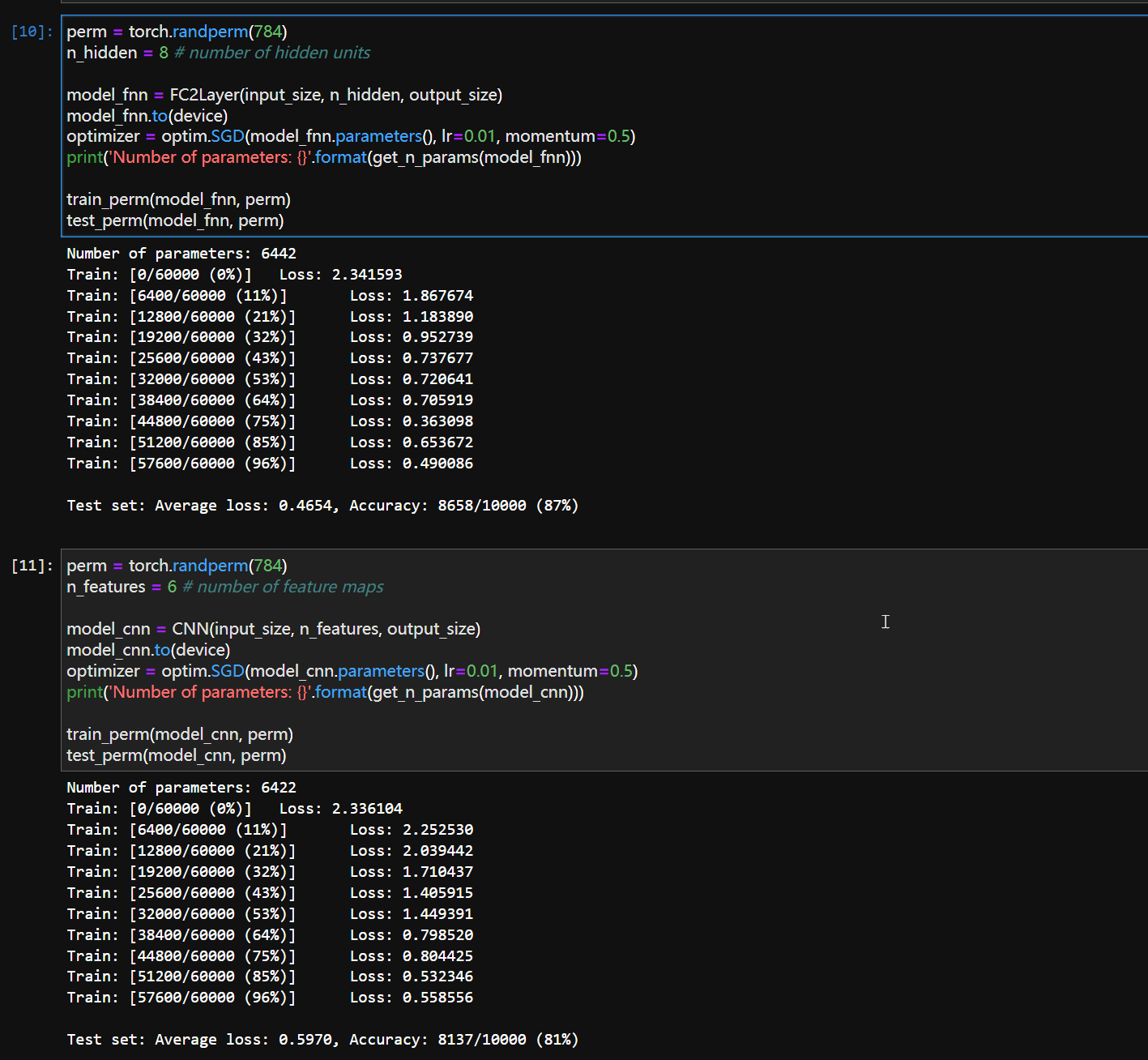
可以发现CNN的效果减弱了很多,甚至弱于FNN,这样的实验同时验证了两件事:
- 验证 FNN 对空间位置不敏感:即使像素被打乱,FNN 仍能利用全局像素分布进行分类。
- 验证 CNN 对空间结构高度依赖:一旦空间结构被破坏,CNN 的性能会严重退化。
这里的所谓“空间位置”,“空间结构”,值得都是图像中每个像素点并不孤立,他们和邻近像素点具有很强的相关性。
这个实验深刻地说明了:CNN 的强大性能来自于它对图像空间局部性的建模能力,而 FNN 则更像一个“全局模式匹配器”。这也是为什么 CNN 成为计算机视觉主流架构的根本原因之一。
实验4:使用LeNet对CIFAR10数据分类
遇到的问题
1.下载的数据集是在加拿大的服务器下载的,160mb的数据,下载速度只有几kb,索性先从本地下好,然后上传到jupyter中,网址如下:
cifar-10-python.tar.gz
顺便附一下解压命令
!tar -xzf cifar-10-python.tar.gz
只是要记得放在data目录的下一级。
2.代码有点老了,还在用python2的.next(),会报AttributeError,改为next()即可。
代码分析
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 注意下面代码中:训练的 shuffle 是 True,测试的 shuffle 是 false
# 训练时可以打乱顺序增加多样性,测试是没有必要
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=8,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
深度学习中大名鼎鼎的transforms这就来了(bushi)。名字确实很像。
torchvision.transforms是数据预处理工作库,对输入数据(主要是图像)
进行各种变换和增强,在这里他有两步:
transforms.ToTensor()- 将 PIL 图像或
[0, 255]范围的 numpy 数组转换为 PyTorch 张量 - 将图像数据从
[0, 255]缩放到[0.0, 1.0]范围 - 调整维度顺序为
(C, H, W)(通道,高度,宽度)
- 将 PIL 图像或
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))- 对每个通道进行标准化处理
- 第一个元组
(0.5, 0.5, 0.5)是均值(mean) - 第二个元组
(0.5, 0.5, 0.5)是标准差(std) - 计算公式:
normalized = (input - mean) / std
这种标准化常用于处理 RGB 图像,三个值分别对应 R、G、B 三个通道,将数据分布调整到均值为 0、标准差为 1 附近,有助于神经网络训练的稳定性和收敛速度。
最终输出的是形状为 (3, H, W) 的标准化张量,值范围在 [-1, 1] 之间。
当然他确实大名鼎鼎,是PyTorch生态的核心组件,深度学习入门必学课,数据预处理的标准做法,ResNet不知道大家还有印象没有,在他的模型中也提供了推荐的transforms参数。
but Transformer是一种神经网络架构(现在相当火)和torchvision.transforms关系并不大。
trainset = torchvision.datasets.CIFAR10(
root=‘./data’, # 数据保存路径
train=True, # 加载训练集
download=False, # 是否自动下载(否,我们本地下好已经传上去了)
transform=transform # 应用前面定义的预处理
)
trainloader = torch.utils.data.DataLoader(
trainset,
batch_size=64, # 每次训练取 64 张图像
shuffle=True, # 每轮训练前打乱顺序
num_workers=2 # 用 2 个子进程并行读取数据,速度加快
)
testset = torchvision.datasets.CIFAR10(
root=‘./data’,
train=False, # 使用测试集(10000 张)
download=False,
transform=transform
)
testloader = torch.utils.data.DataLoader(
testset,
batch_size=8, # 每次测试取 8 张图像(可小一些)
shuffle=False, # 测试时不打乱顺序(不影响结果)
num_workers=2
)
超参差不多了,下面开始进入正题。
def imshow(img):
plt.figure(figsize=(8,8))
img = img / 2 + 0.5 # 转换到 [0,1] 之间(有点意思的反归一化)
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 得到一组图像
images, labels = next(iter(trainloader))
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示第一行图像的标签
for j in range(8):
print(classes[labels[j]])
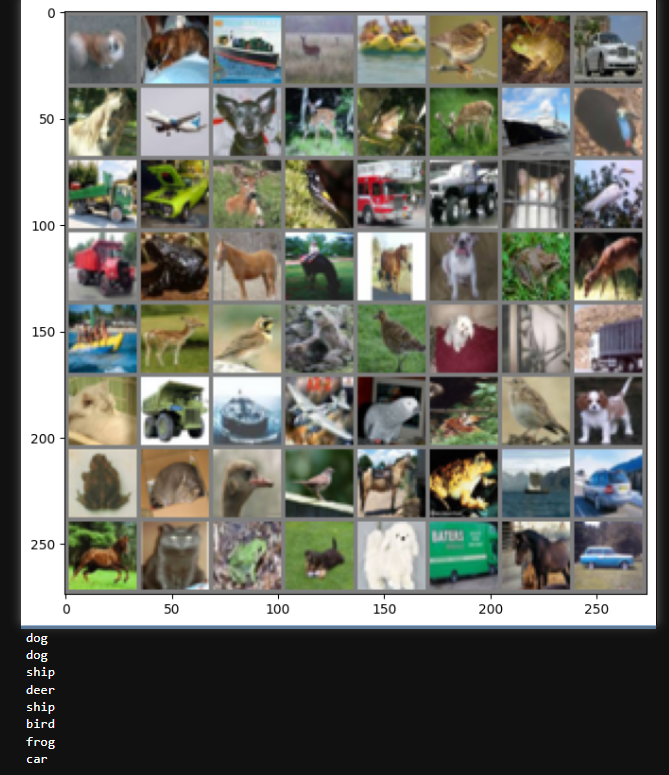
没什么好说的,相当于抽了一部分训练集给我们看。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
class Net(nn.Module):
继承 torch.nn.Module,这是所有神经网络模块的基类,我们重写 __init__ 和 forward 两个函数即可。
重写__init__函数(定义每层网络的具体内容):
- 定义第一个卷积层:输入通道数为 3(RGB 图像),输出通道数为 6,卷积核大小为 5x5。
- 定义最大池化层:窗口大小为 2x2,步长为 2。
- 定义第二个卷积层:输入通道数为 6(来自上一层的输出),输出通道数为 16,卷积核大小为 5x5。
- 定义第一个全连接层:输入维度为 16* 5 *5(即第二层卷积后的特征图展平后的大小),输出维度为 120。
- 定义第二个全连接层:输入维度为 120,输出维度为 84。
- 定义第三个全连接层(输出层):输入维度为 84,输出维度为 10(对应 CIFAR-10 数据集的 10 个类别)。
然后是forward(前向传播方法)重写:
- 对输入
x应用第一个卷积层conv1,然后通过 ReLU 激活函数F.relu,最后应用最大池化层pool。 - 类似地,对上一步的结果应用第二个卷积层
conv2,再经过 ReLU 激活和最大池化。 - 将多维的特征图展平成一维向量,以便输入到全连接层中。
- 对展平后的特征应用第一个全连接层
fc1,并通过 ReLU 激活。 - 对上一步的结果应用第二个全连接层
fc2,并通过 ReLU 激活。 - 最后应用输出层
fc3,得到最终的分类结果。(这里没有用激活函数,因为后续CrossEntropyLoss()内部会用)
后面的应用网络,交叉熵损失函数,Adam优化器不再赘述。
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
Epoch: 1 Minibatch: 1 loss: 2.308
Epoch: 1 Minibatch: 101 loss: 2.036
Epoch: 1 Minibatch: 201 loss: 1.700
Epoch: 1 Minibatch: 301 loss: 1.922
…
Epoch: 10 Minibatch: 501 loss: 0.942
Epoch: 10 Minibatch: 601 loss: 0.896
Epoch: 10 Minibatch: 701 loss: 0.945
Finished Training
训练十次,
“前向→损失→反向→更新”
# 得到一组图像
images, labels = next(iter(testloader))
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示图像的标签
for j in range(8):
print(classes[labels[j]])

outputs = net(images.to(device))
_, predicted = torch.max(outputs, 1)
# 展示预测的结果
for j in range(8):
print(classes[predicted[j]])
cat
car
car
plane
frog
frog
car
frog
可以发现预测结果还算可以(除了ship变成car)
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
Accuracy of the network on the 10000 test images: 64 %
准确率只有64%,还有很大优化空间,代码中的CNN其实挺老的,在 CIFAR-10 数据集上,现代卷积神经网络(CNN)和相关架构的准确率已经达到了非常高的水平,SOTA模型准确率普遍在 97% 以上,甚至接近或超过 99%。
实验5:使用VGG对CIFAR10分类
遇到的问题
第二个代码块会出现报错,但是问题不大,
第五行改为 self.features = self._make_layers(self.cfg),
第六行改为 self.classifier = nn.Linear(512, 10)。
其中第一个报错在VGG被使用时才会出现。
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
self.features = self._make_layers(cfg)
self.classifier = nn.Linear(2048, 10)
代码分析

跑了一下代码,结果和老师的差不多,但我对VGG了解不多,CNN也不是很会,综合考虑时间原因,这部分代码分析我决定浅尝辄止。
流程是固定的,数据准备(transform 与 dataloader),定义 VGG 网络结构,定义损失函数与优化器,训练循环(forward + backward + update),我们这里重点看一下VGG的网络结构实现,其他部分如果有有意思的东西我们就提一下。
VGG本身是CNN的变体,其最大特点是全部使用 3×3 的小卷积核,并通过堆叠多个卷积层来增加网络深度。这种设计在保持感受野的同时减少了参数量,并增强了模型的非线性表达能力。
这里实现的 VGG 简化版本包含多个卷积层和池化层,总共约 14 层(包括卷积和全连接层),虽然比原始的 VGG16 或 VGG19 稍浅,但保留了 VGG 的核心结构思想,可以看到,效果也很不错。
二、问题总结
2.1 dataloader 里面 shuffle 取不同值有什么区别?
shuffle=True:在每个 epoch 开始时,打乱数据顺序。训练时通常设为True,避免模型学习到数据的顺序依赖,提高泛化能力;shuffle=False:保持数据原始顺序。测试/验证时通常设为False。保证每次测试结果一致,便于评估和调试;
2.2 transform 里,取了不同值,这个有什么区别?
transforms.Normalize(mean, std) 是对图像进行标准化,公式为:
x
′
=
x
−
mean
std
x' = \frac{x - \text{mean}}{\text{std}}
x′=stdx−mean
-
不同的
(mean, std)值会影响输入数据的分布:-
如果
mean=0.5, std=0.5→ 将像素值从[0,1]映射到[-1,1]
x ′ = x − 0.5 0.5 = 2 x − 1 x' = \frac{x - 0.5}{0.5} = 2x - 1 x′=0.5x−0.5=2x−1
这有助于加速训练(数据居中、方差接近 1)。 -
如果使用 ImageNet 的均值
(0.485, 0.456, 0.406)和标准差(0.229, 0.224, 0.225),更适合迁移学习。
-
在本例中,使用
(0.5, 0.5, 0.5)是一种简单通用的归一化方式,适用于大多数情况。
2.3 epoch 和 batch 的区别?
| 概念 | 含义 | 示例 |
|---|---|---|
| Batch(批次) | 一次前向/反向传播所用的数据量 | batch_size=64 表示每次处理 64 张图片 |
| Epoch(轮次) | 整个训练集被完整遍历一次 | CIFAR-10 有 50000 张图,batch_size=64 → 每个 epoch 约需 782 次迭代 |
训练流程:
for epoch in range(10): for batch in dataloader: # 每次取一个 batch train_step(batch)
2.4 1x1的卷积和 FC 有什么区别?主要起什么作⽤?
| 特性 | 1×1 卷积 | 全连接层(FC) |
|---|---|---|
| 输入形式 | 保持空间结构(H×W×C) | 展平为向量(D,) |
| 参数共享 | 权重在空间位置上共享 | 每个输出独立 |
| 感受野 | 局部(仅当前像素) | 全局(所有输入) |
| 主要作用 | 通道变换、降维、非线性 | 分类、特征融合 |
1×1 卷积的作用:
- 改变通道数(如 Inception 模块中用于降维);
- 引入非线性(配合 ReLU);
- 替代部分 FC 层以保留空间信息(如 Network in Network)。
区别举例:
Conv2d(in_c, out_c, 1)对每个 H×W 位置做相同的线性变换;Linear(D_in, D_out)对整个向量做变换,不区分空间位置。
2.5 residual leanring 为什么能够提升准确率?
残差学习(ResNet 核心思想)通过引入跳跃连接(skip connection) 解决深层网络中的梯度消失和退化问题。
公式:
y = F ( x ) + x y = F(x) + x y=F(x)+x
其中 $ F(x) $ 是残差函数。
优势:
- 缓解梯度消失:梯度可以直接通过跳跃连接回传;
- 更容易优化:即使 $ F(x) \approx 0 $,网络也能保持恒等映射;
- 支持更深网络:可以训练上百层甚至上千层的网络;
- 提升表达能力:学习的是“残差”,比直接学习原始映射更有效。
实验表明,没有残差结构的深层网络性能反而不如浅层网络,而 ResNet 能持续受益于深度增加。
2.6 代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
| 特性 | 本代码中的 Net | 原始 LeNet(LeNet-5) |
|---|---|---|
| 输入尺寸 | 32×32×3(彩色) | 32×32×1(灰度) |
| 卷积核大小 | 5×5 | 5×5 |
| 池化方式 | Max Pooling(现代常用) | Average Pooling(原始) |
| 激活函数 | ReLU(现代) | Sigmoid / Tanh(原始) |
| 层数 | 更深一些(2卷积+3全连接) | 较浅(2卷积+2全连接) |
| BatchNorm | 无 | 无(当时未提出) |
| 优化器 | Adam(自适应学习率) | SGD(手动调参) |
总结:
当前网络是 LeNet 的现代简化版,保留了“卷积→池化→全连接”的基本结构,但使用了更先进的组件(ReLU、MaxPool、Adam),适合彩色图像任务。
2.7 代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
当 feature map 尺寸变化时(如 stride=2 或 pooling),跳跃连接无法直接相加(维度不匹配)。解决方法:
方法一:调整跳跃路径
-
使用
1×1卷积 + 步长调整跳跃路径的通道数和空间尺寸:shortcut = self.conv1x1(x) # 改变通道数 shortcut = F.avg_pool2d(shortcut, 2) # 下采样 out = F.relu(self.conv_layer(x) + shortcut)
方法二:填充或插值
- 对主路径输出进行上采样,或对跳跃路径进行零填充。
在 ResNet 中,当尺寸变化时,通常使用
1×1卷积 + stride 来匹配维度。
2.8 有什么方法可以进⼀步提升准确率?
数据层面:
- 数据增强:随机裁剪、旋转、颜色抖动、Mixup、Cutout;
- 使用预训练模型 + 微调(如 ResNet-18 on ImageNet);
模型层面:
- 使用更先进架构:ResNet、DenseNet、EfficientNet;
- 添加 BatchNorm、Dropout 防止过拟合;
- 使用 SE 模块等注意力机制;
训练技巧:
- 学习率调度(如 Cosine Annealing、ReduceLROnPlateau);
- 使用更好的优化器(如 AdamW);
- 标签平滑(Label Smoothing);
- 多模型集成(Ensemble);
其他:
- 增大 batch size 或训练更多 epoch;
- 使用更大的模型或更深的网络;
- 调整超参数(学习率、权重衰减等)。

















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









