






🚀 从“直觉反应”到“自主思考”:LangChain 开发范式的三次跃迁
“I think AI agentic workflows will drive massive AI progress this year… perhaps even more than the next generation of foundation models.” > — Andrew Ng (吴恩达)
在大模型应用落地的过程中,我们正经历着一场从简单的 API 调用到构建复杂智能系统的演变。基于 LangChain 的开发实践,我们将这个过程划分为三个核心阶段:面向 LLM、面向 Chain 以及 面向 Agent。
本文将结合生产环境的实际案例与架构图,深度剖析这三种开发范式的本质区别与适用场景。
💡 第一阶段:面向 LLM 开发 (Model I/O)
—— "直觉反应"模式
这是大模型开发的最早期阶段,也是最基础的模式。
1.1 核心理念:零样本的“一次性交付”
在这个阶段,我们主要使用 LangChain 的 Model I/O 模块。工作流非常线性:
User Input -> Prompt -> LLM -> Output
吴恩达教授曾用一个非常形象的比喻来描述这种模式的局限性:
“这就像要求一个人在高考时写作文,必须从头到尾一气呵成,直接用钢笔写在答题卡上,不允许使用退格键,不允许打草稿,还要保证高质量。”
虽然现在的 LLM 能力很强,但在这种“无回溯”的高压模式下,一旦中间某个逻辑推理出错,整个结果就会崩塌。
1.2 生产案例:简易翻译助手
- 场景:构建一个中英互译工具。
- 实现:直接将用户文本填入 Prompt 模板,调用 GPT-3.5/4。
- 痛点:如果你让它“翻译并重写一段关于 RAG 架构的技术文档,要求逻辑通顺”,它可能会在翻译过程中丢失部分技术细节,因为它没有机会“回读”原文进行校对。
🔗 第二阶段:面向 Chain 开发 (Chains)
—— "流水线"模式
为了解决复杂任务,我们将多个步骤串联起来,形成了 Chain(链)。
2.1 核心理念:硬编码的“SOP”
Chain 的本质是:人类负责规划,AI 负责执行。
在这个阶段,开发者充当了“大脑”。我们预判了任务的所有分支,并用代码(比如 RouterChain 或 SequentialChain)将它们固定下来。
- 优点:稳定、可控、逻辑清晰。
- 缺点:僵化。如果有 100 种边缘情况,你需要写 100 个
if-else分支。AI 就像一列火车,只能沿着你铺好的铁轨跑,一旦脱轨(遇到未知的用户意图)就会报错。
2.2 生产案例:智能客服路由系统
- 场景:某电商平台的售后机器人。
- 硬编码逻辑:
- Step 1 (分类):调用 LLM 判断用户意图。
- Step 2 (路由):
- 如果是“退款”,进入
RefundChain(调用退款 API)。 - 如果是“投诉”,进入
ComplaintChain(记录工单)。 - 如果是“咨询”,进入
QAChain(查询知识库)。
- 如果是“退款”,进入
- 生产痛点:如果用户问:“我买的鞋子大了一码,既想换货又想投诉客服态度”,这种跨意图的复杂需求,传统的 Chain 很难灵活拆解处理,往往只能回复“对不起我没听懂”。
🤖 第三阶段:面向 Agent 开发 (Agents)
—— "自主思考"模式
这是目前最前沿的落地架构,也是从“自动化”向“自主化”的质变。
3.1 核心理念:循环迭代的“打草稿”
Agent 的本质是:AI 既负责规划,也负责执行。
Agent 引入了工具(Tools)、规划(Planning)和记忆(Memory)。它不再是一条直线,而是一个循环(Loop)。这就像我们在写文章前,先列大纲(规划),发现资料不够去查百度(调用工具),写完初稿后自己读一遍(反思/观察),发现不通顺再修改(迭代),最后交稿。
3.2 核心架构深度解析
让我们结合下面这张 LangChain Agent 运行架构图来拆解它的“身体构造”:
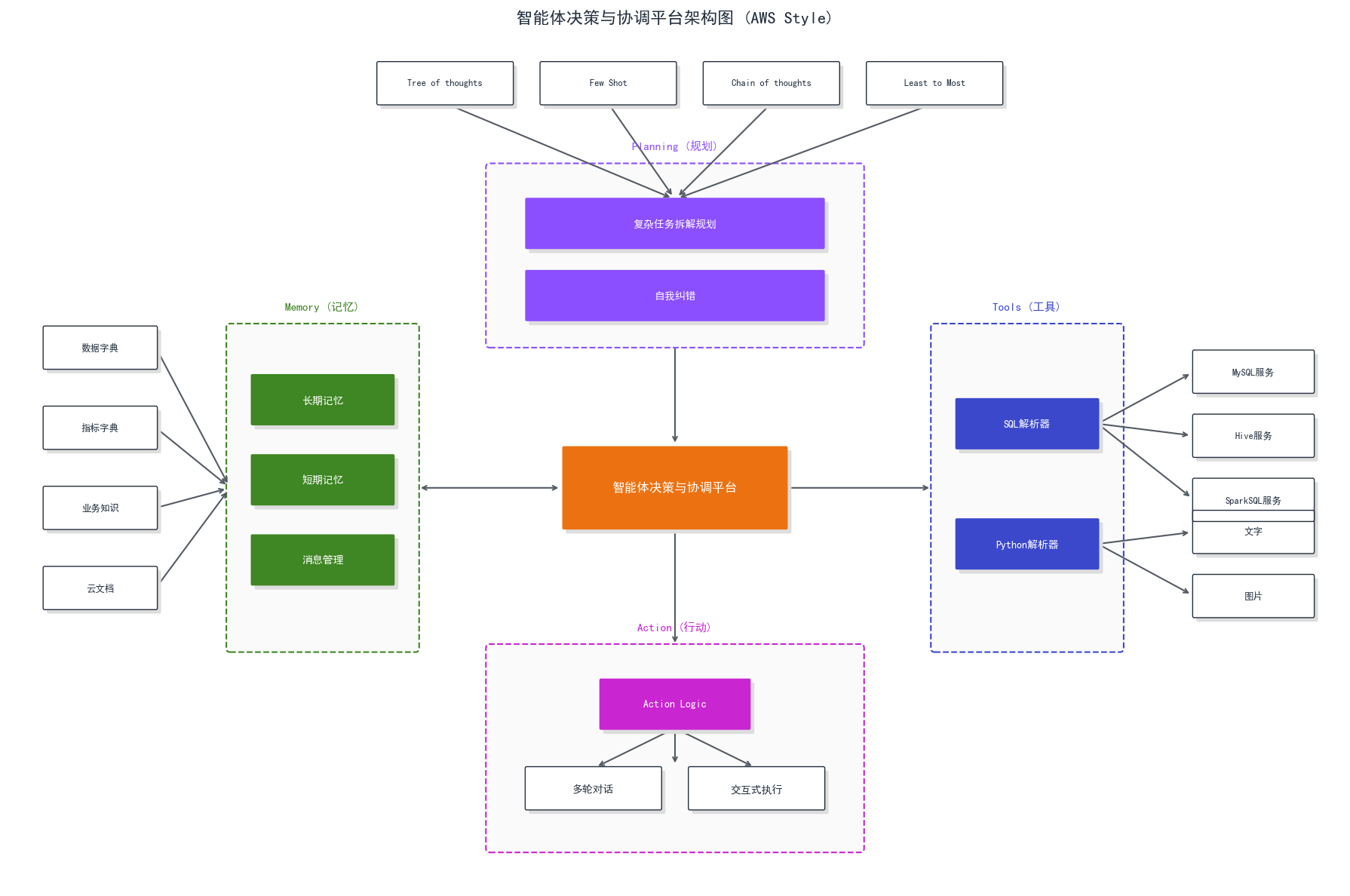
(图解:LangChain Agent 的核心运行机制)
- 大脑 (LLM + Prompt):
- 图中的橙色部分。这是决策中心。Prompt 赋予了它“人设”,告诉它:“你是一个全能助手,你可以使用计算器、搜索引擎等工具。遇到问题请先思考(Thought),再行动(Action)。”
- 四肢 (Toolkits):
- 图中的右侧
Toolkits。Agent 与外部世界交互的唯一接口。 - 关键点:每个 Tool 都必须有清晰的 Description(描述)。Agent 不是靠函数名,而是靠阅读这些描述来决定“我现在该用哪个工具”。
- 图中的右侧
- 感知与记忆 (Message & History):
- 图中的左侧。Agent 需要知道之前的步骤做过什么(Short-term memory),避免重复执行相同的错误操作。
- 心脏 (AgentExecutor):
- 图顶部。它是一个运行时环境,维护着一个
While循环: 思考->选择工具->执行工具->观察结果->带着结果再次思考… ->完成。
- 图顶部。它是一个运行时环境,维护着一个
3.3 生产案例:深度行业研报生成器 (iQuery Agent)
- 场景:用户指令“帮我分析 2024 年 AI 行业的融资趋势,并生成图表”。
- Agent 的自主执行流 (ReAct 模式):
- Round 1:
- 思考:我需要数据。
- 行动:调用
Google Search搜索 “2024 AI funding trends”。
- Round 2:
- 观察:搜到的数据是文本,很乱。
- 思考:我需要把文本转成结构化数据,并画图。
- 行动:调用
Python Code Interpreter,写一段 Python 代码清洗数据并用 Matplotlib 画图。
- Round 3:
- 观察:代码报错了,提示缺少库。
- 思考:啊,我需要修改代码,换一个库。
- 行动:重新生成 Python 代码并执行。
- Round 4:
- 观察:图表生成成功。
- 行动:结合图表和搜索到的文本,撰写最终报告并回复用户。
- Round 1:
对比 Chain 模式:在 Chain 模式下,你根本无法预判 AI 第一次写代码会报错,也没法预设“报错后重试”的逻辑。只有 Agent 的自主循环才能处理这种动态的异常。
⚠️ 生产级挑战与最佳实践
在实际将 Agent 部署到生产环境时,我们总结了以下常见问题:
| 挑战 | 现象描述 | 解决方案 (Best Practice) |
|---|---|---|
| 死循环 (Infinite Loops) | Agent 在某个逻辑死胡同里打转,反复搜索同一个词,耗尽 Token。 | 1. 设置 max_iterations(最大迭代次数)。2. 在 Prompt 中加入 System Message:“如果连续 3 次搜索无果,请直接告知用户无法回答”。 |
| 幻觉调用 (Hallucination) | AI 捏造了一个不存在的工具参数,或者给“计算器”传了一段文字。 | 1. Poka-yoke(防错设计):优化工具的 Docstring,给 AI 提供 Few-shot 示例。 2. 使用 OpenAI 的 Function Calling 强制约束输出格式。 |
| 延迟过高 (Latency) | 思考->行动->观察 的链条太长,用户等待时间久。 | 1. 并行调用:如果是互不依赖的搜索任务,让 Agent 并行执行。 2. 流式输出:展示中间步骤(如“我正在搜索…”,“我正在计算…”),降低用户的心理等待时长。 |
📝 总结
从 面向 LLM 到 面向 Chain,再到 面向 Agent,本质上是我们对 AI 信任度的提升:
- LLM 时代:我们把 AI 当作一支笔。
- Chain 时代:我们把 AI 当作流水线上的工人。
- Agent 时代:我们把 AI 当作合作伙伴,只给目标,不问过程。
随着 LangGraph 等新一代编排工具的出现,未来的 Agent 将具备更强的状态管理能力和多智能体协作能力,真正实现从“辅助工具”到“智能生产力”的跨越。

















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









