






深度解析:基于 RAG 与 LLM 的智能推荐系统架构设计
在传统的推荐系统中,我们通常依赖协同过滤(Collaborative Filtering)或双塔模型(Two-Tower Models)。然而,随着大语言模型(LLM)的兴起,检索增强生成(RAG) 为推荐领域带来了全新的范式——利用 LLM 强大的语义理解能力进行特征工程和动态用户画像生成。
本文将基于一套生产级的 RAG 智能推荐架构图,深入拆解其从数据入库到在线推理的全流程,并结合实际生产案例探讨其中的设计精髓与潜在挑战。
一、 架构总览
该架构主要分为两大部分:
- 离线数据处理流水线(Offline Pipeline):图示上半部分。负责将非结构化文档(PDF)转化为结构化数据,并通过 LLM 进行特征增强,最终存入向量库。
- 在线推理流水线(Online Inference):图示下半部分。基于用户对话历史(Chat History)的长度进行路由,动态生成用户画像(User Profile),并结合向量检索进行个性化推荐。
二、 流程图详细拆解与工具栈
我们将严格按照架构图的流向,将系统拆解为五个核心模块进行详细说明。
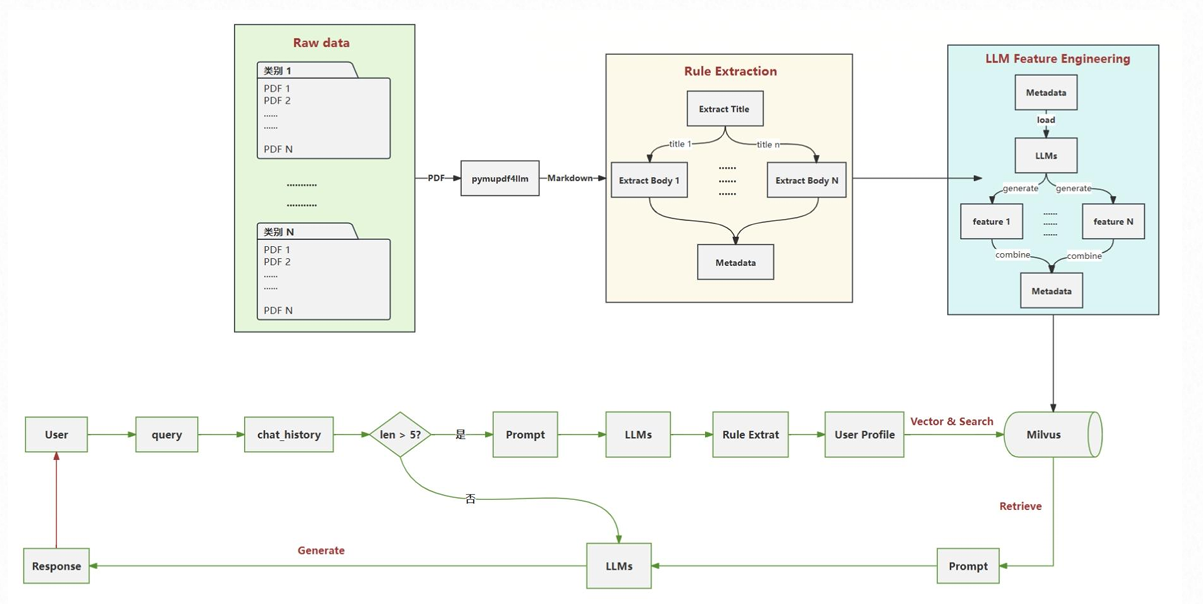
1. 数据解析层 (Raw Data →\rightarrow→ Markdown)
这是知识库构建的基石。图示左上角展示了从 Raw data (PDF) 到 Markdown 的转换过程。
-
流程说明:
- Raw Data: 包含各类非结构化 PDF 文档(如研报、合同、产品手册)。
- 转换 (pymupdf4llm): 系统没有使用传统的 OCR 或纯文本提取,而是使用了
pymupdf4llm。这是一个关键细节,因为它能保留文档的 版面信息(Layout)。 - Markdown: 转换的目标格式。Markdown 的标题(#)、列表(-)和表格结构天然适合 LLM 理解,是 RAG 中最佳的中间格式。
-
🧰 常用工具栈:
- 核心工具:
pymupdf4llm(轻量、保留结构),PyMuPDF. - 替代/增强:
Unstructured.io(处理更复杂的异构数据),LlamaParse(擅长处理复杂表格),MinerU(国产开源高质量解析).
- 核心工具:
-
📝 生产案例:
- 金融研报分析:解析时必须保留“表格”结构,否则“2023年营收”和“2022年营收”的数字会混在一起,导致检索错误。
2. 规则提取层 (Rule Extraction)
图示中部的黄色区域。将 Markdown 文本转化为具有层级关系的结构化数据。
-
流程说明:
- Extract Title & Body: 基于 Markdown 的语法(如
##标记),将文档切分为独立的语义块(Chunks)。 - Metadata 提取: 初步提取文档自带的元数据(如文件名、页码、创建时间)。
- 结构化映射: 建立
Title->Body的层级索引,确保检索到 Body 时能回溯到 Title,防止断章取义。
- Extract Title & Body: 基于 Markdown 的语法(如
-
🧰 常用工具栈:
- 编排工具:
LangChain(RecursiveCharacterTextSplitter),LlamaIndex(NodeParser). - 正则/规则: Python
re库 (用于定制化的 Title 匹配).
- 编排工具:
-
📝 生产案例:
- 法律条款检索:通过规则提取,将“第五条 赔偿责任”作为 Title,其具体的条款内容作为 Body。检索时命中条款内容,模型能准确知道这是属于“赔偿责任”部分的。
3. LLM 特征工程层 (LLM Feature Engineering)
图示右上角的蓝色区域。这是本架构的灵魂所在——利用 LLM 生产数据,而不仅是消费数据。
-
流程说明:
- Load -> LLMs: 加载清洗后的 Chunk,喂给 LLM。
- Generate Features: 让 LLM 为每个 Chunk 生成额外的特征。例如:
- 摘要 (Summary):用一句话概括这段话。
- QA 对 (Hypothetical Questions):这段话能回答什么问题?
- 标签 (Tags):提取实体(人名、地名、产品名)。
- Combine: 将
Original Text+LLM Generated Features+Metadata融合,形成一个富文本块(Rich Document)。
-
🧰 常用工具栈:
- 模型:
GPT-4o-mini,Claude 3.5 Haiku,Qwen2.5-7B(高性价比模型适合做此类批量任务). - 框架:
LlamaIndex(Metadata Extractor 模块).
- 模型:
-
📝 生产案例:
- 电商推荐:原始文档只有“iPhone 15 参数”,LLM 补充特征:“适合送礼”、“摄影爱好者推荐”、“高单价商品”。这些特征极大地提升了语义检索的命中率。
4. 动态画像与路由层 (User Flow & Profiling)
图示下半部分的绿色流程。系统根据用户交互深度,智能选择处理路径。
-
流程说明:
- 路由判断 (len > 5?):
- No (短路径): 用户刚开始对话,信息量少。直接进入生成流程或进行基础检索。这避免了在没有足够上下文时强行生成画像产生的“幻觉”。
- Yes (长路径): 用户交互丰富。进入 Prompt -> LLMs -> Rule Extract -> User Profile 流程。
- User Profile 生成: 系统读取最近 N 轮对话,利用 LLM 总结用户的显性需求(“我要买电脑”)和隐性偏好(“看重便携性,对价格不敏感”)。
- 路由判断 (len > 5?):
-
🧰 常用工具栈:
- 记忆存储:
Redis,Memcached(存储 chat_history). - 推理模型: 需要推理能力较强的模型,如
GPT-4,Claude 3.5 Sonnet。 - Prompt 管理:
LangSmith(调试 Prompt 效果).
- 记忆存储:
-
📝 生产案例:
- 智能导购:用户问了5轮关于“登山鞋”的问题。系统生成 Profile:“用户计划去高海拔地区,关注防水性能,预算2000元”。
5. 向量检索与生成层 (Vector Search & Response)
图示右下角。物理存储与最终输出。
-
流程说明:
- Vector & Search: 将
User Profile(如果是长路径)或Query(如果是短路径)转化为向量。 - Milvus: 高性能向量数据库,存储之前离线处理好的富文本向量。
- Retrieve -> Prompt -> LLMs -> Response: 取出最相似的 Top-K 文档,拼接 Prompt,生成最终回复。
- Vector & Search: 将
-
🧰 常用工具栈:
- 向量数据库:
Milvus(适合大规模生产环境),Qdrant,Weaviate,Elasticsearch(混合检索). - Embedding 模型:
BGE-M3(支持多语言、长文本),OpenAI text-embedding-3. - 重排序 (Rerank):
BGE-Reranker,Cohere Rerank(检索后精排,提升准确率).
- 向量数据库:
三、 核心代码示例:LLM 特征工程
为了让您更好地理解右上角 LLM Feature Engineering 模块,以下是一个使用 LLM 自动生成“文档摘要”作为元数据的伪代码:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
import json
# 定义 LLM,通常使用便宜且快速的模型
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 定义特征提取的 Prompt
feature_prompt = PromptTemplate.from_template("""
阅读以下文档片段:
"{text_chunk}"
请提取以下 JSON 格式的特征:
1. summary: 一句话摘要
2. keywords: 3-5个关键词
3. audience: 适合的目标人群
""")
def generate_features(chunk):
# 调用 LLM 生成特征
response = llm.invoke(feature_prompt.format(text_chunk=chunk))
features = json.loads(response.content)
# 将特征合并回元数据
# 这一步对应图中 "combine -> Metadata"
return {
"page_content": chunk,
"metadata": features
}
# 模拟处理一个 Chunk
doc_chunk = "本理财产品风险等级为R2,主要投资于国债、央行票据..."
enriched_doc = generate_features(doc_chunk)
print(f"原始文本: {enriched_doc['page_content'][:10]}...")
print(f"LLM 增强特征: {enriched_doc['metadata']}")
# 输出示例: {'summary': '低风险固定收益类理财', 'keywords': ['R2', '国债'], 'audience': '稳健型投资者'}
四、 经典生产问题与应对
尽管该架构设计精妙,但在落地时常会遇到以下挑战:
1. 延迟 (Latency) 之痛
- 问题: 图中的 “Yes” 分支包含了两轮 LLM 调用(一次生成 Profile,一次生成最终 Response)。LLM 生成 Profile 可能需要 2-3 秒,这对于实时推荐是不可接受的。
- 解决方案:
- 异步更新 (Async Profiling): 不要每次 Query 都实时生成 Profile。可以在用户交互的空闲期(或每隔 N 条消息)后台异步更新 Profile。
- 流式输出 (Streaming): 即使 Profile 还在生成,先给用户返回部分通用回复。
2. “僵尸” 文档与更新
- 问题: 推荐系统的内容(如商品价格、库存)是动态变化的,而 PDF 处理流程较慢。
- 解决方案: 架构中的
Metadata模块必须包含时间戳。在 Milvus 检索时,利用Scalar Filtering(标量过滤)过滤掉过期的文档,或者在 Prompt 中注入 “当前时间”,让 LLM 能够识别过期信息。
3. 冷启动与上下文丢失
- 问题: 图中
len <= 5时可能因为信息过少导致推荐不准。 - 解决方案: 引入 混合检索 (Hybrid Search)。在 User Profile 尚未生成时,利用关键词检索(BM25)弥补向量检索在短文本上的不足;同时利用热门推荐列表(非个性化)进行兜底。
五、 总结
这套架构图展示了一个成熟的 RAG 推荐系统雏形。它没有止步于简单的 “文本切片+检索”,而是引入了 结构化数据清洗 (Markdown) 和 动态用户侧写 (LLM Profiling) 这两个提升效果的关键抓手。
对于开发者而言,最值得借鉴的是:不要直接把脏数据喂给向量数据库,也不要指望只靠原始 Query 就能搜到精准结果。 在两端都加上 LLM 进行"预处理"(数据侧)和"意图增强"(用户侧),是提升 RAG 系统生产力的必经之路。

















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









