






企业级大模型推理网关设计:混合部署与高可靠通信机制详解
在构建商业级知识库(RAG)系统时,最基础也最核心的功能模块便是**“智能对话”**。
乍看之下,智能对话似乎很简单:用户发一个问题,后台调用一下 GPT 的 API,然后返回答案。但在企业级生产环境中,我们需要面对更复杂的需求:
- 多模型支持:既要支持在线的 GPT-4,又要支持私有化部署的 ChatGLM、Qwen、Llama。
- 统一接口:前端不应关心后端调用的是哪个模型,需要一套统一的 API 标准。
- 数据留痕:所有的提问和回答必须持久化存储,用于审计和后续优化。
- 流式体验:必须支持打字机效果(Streaming),而非等待生成完一次性返回。
本文将基于商业级知识库的架构设计,详解如何构建一个高可扩展的智能对话系统。
01. 核心架构图解
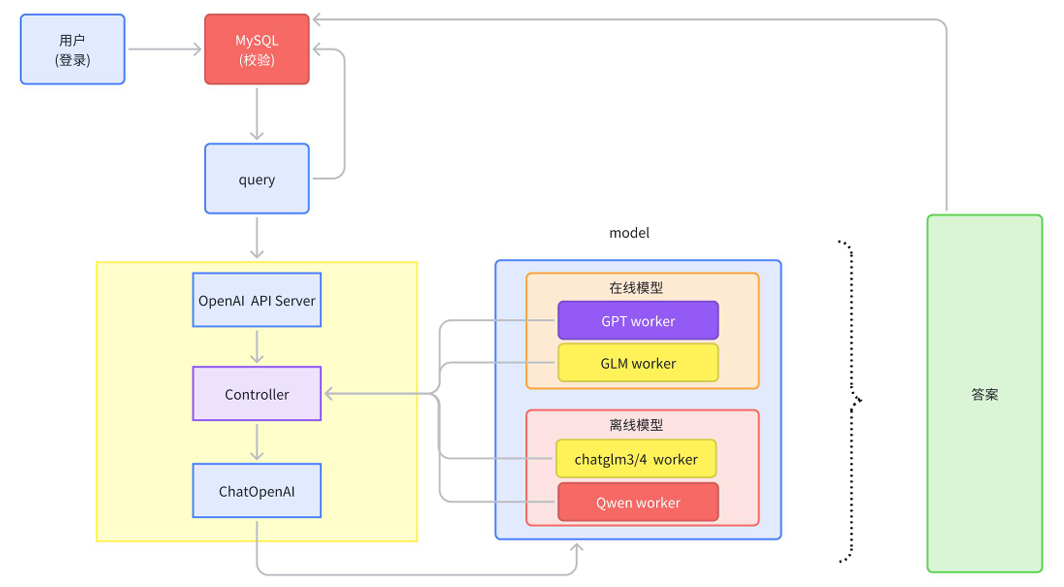
如上图所示,我们的智能对话模块并没有采用简单的“直连模型”方式,而是设计了一套类 Controller-Worker 的主从架构。
核心组件定义:
- User & Web APP:用户交互前端,负责流式渲染。
- MySQL:核心业务数据库,负责用户鉴权和会话记录存储。
- OpenAI API Server (统一网关):系统的统一入口,对外暴露标准接口(如 8000 端口)。
- Controller (控制中心):负责管理所有模型的注册、心跳和调度,充当服务发现的角色。
- Model Workers (模型执行单元):实际运行模型的节点,分别对应在线 API 和离线本地模型。
02. 核心决策:为什么采用“混合部署”(在线+离线)?
在企业级架构中,单一的模型部署方式往往行不通。我们坚持同时部署在线商业模型(如 OpenAI/Claude)和离线开源模型(如 Qwen/Llama/GLM),主要基于以下四大维度的考量:
| 维度 | 在线模型 (Online API) | 离线模型 (Offline Local) | 混合部署的价值 (架构收益) |
|---|---|---|---|
| 数据安全 | 低。数据需传出内网,存在合规风险。 | 高。数据不出域,物理隔离。 | 敏感数据走离线,公开数据走在线。 |
| 推理成本 | 按 Token 计费。成本随用量线性增长。 | 固定硬件投入。成本仅为电费。 | 闲聊走离线(省钱),复杂推理走在线(保效果)。 |
| 可用性 | 依赖网络。API 可能限流或宕机。 | 本地可控。断网也能用。 | 在线挂掉时,自动降级到离线模型兜底。 |
基于此的路由策略设计:
- 策略 A(敏感路由):Prompt 含“薪资/合同” -> 强制路由至本地 ChatGLM3-6B。
- 策略 B(降本路由):普通员工闲聊 -> 路由至本地 Qwen-14B。
- 策略 C(能力路由):代码生成/复杂分析 -> 路由至 OpenAI GPT-4。
03. 全链路时序图 (Sequence Diagram)
为了更清晰地展示数据流转,我们梳理了从用户提问到流式回答的完整时序:
04. 关键通信机制与协议设计
1. 统一 API 网关:流式响应 (Streaming) 的实现
在生产环境中,等待 30 秒一次性返回答案是不可接受的。我们需要实现 SSE (Server-Sent Events)。
- 痛点:不同的后端模型(ChatGLM, Qwen, Llama)输出流的格式各不相同。
- 方案:在 API Server 层进行协议清洗。
- 处理:API Server 调用后端 Worker 的
generate_stream接口。 - 输出:API Server 将 Worker 返回的原始 Token 封装成标准的 OpenAI Chunk 格式。
- 效果:前端直接使用现成的 OpenAI 客户端库即可接收流式消息,无需为每个模型写解析逻辑。
- 处理:API Server 调用后端 Worker 的
2. Controller-Worker 通信协议
为了实现高扩展性,我们定义了一套基于 HTTP 的轻量级注册协议。
- 心跳包 (Heartbeat):Worker 每 20 秒向 Controller 汇报一次状态(包含模型名称、地址、负载情况)。
- 调度逻辑:Controller 根据 Worker 汇报的标签(如
tags: ["offline", "secure"]),将 API Server 的请求路由到最合适的 Worker 节点。
05. 核心难点突破:异步回调存储机制 (Callback Mechanism)
这是整个架构中最容易被忽视,但对数据一致性最关键的设计。
1. 为什么要这么设计?(痛点场景)
场景假设:
用户让 AI 写一份 5000 字的周报。
- 正常情况:AI 生成了 2 分钟,前端屏幕上字一个个蹦出来,最后生成完毕。
- 异常情况:生成到第 1 分钟(写了一半)时,用户的WiFi 断了,或者浏览器崩溃了,或者中间层的 API Gateway 超时断开了。
如果是传统的同步写入逻辑(网关层收到完整结果后再写库):
用户的连接断了 -> 网关层报错 -> 数据还没来得及写库 -> 这次生成彻底丢失。
后果:用户重连后,历史记录里只有问题,没有答案,白等了 1 分钟。
2. 我们的方案:Worker 端的“独立回调”
我们将“写库”这个动作,下放给最底层的打工者(Model Worker),而不是中间商(API Gateway)。
具体执行流程(举例说明):
-
Step 1:占位(Ticket)
用户提问:“请帮我写周报”。
API Gateway 收到请求后,立刻在数据库生成一条记录:
{id: "msg_888", question: "写周报", answer: NULL, status: "PROCESSING"}。
此时,API Gateway 拿到了一张“票据”,ID 是 msg_888。 -
Step 2:委托(Delegate)
API Gateway 找到空闲的 Worker(比如 Qwen-72B),把任务发给它,并嘱咐道:“请回答这个问题,另外,这张票据(record_id: msg_888)你拿着,一会完事了你自己去更新。”
-
Step 3:独立执行(Execution)
Worker 开始推理。它一边通过网络给 API Gateway 吐字(为了让前端展示),一边自己在内存里把生成的字拼成一个完整的字符串。- 此时,即使用户断网了,API Gateway 报错了,Worker 依然在服务器后台默默地继续生成,直到完成。
-
Step 4:完结回写(Callback)
Worker 生成结束。它拿着手里完整的字符串(比如 5000 字的周报),直接向数据库服务发起一个更新请求:UPDATE chat_messages SET answer = "周报内容...", status = "SUCCESS" WHERE id = "msg_888"
3. 方案价值总结
通过这种**“任务分发 + 携带 ID + 异步回写”**的机制,我们实现了:
- 断点续传般的体验:即使前端崩溃,用户刷新页面后,依然能看到 AI 在后台完整生成的周报,因为数据是由后端 Worker 保证写入的。
- 解耦与容错:中间的 API Gateway 变得非常轻量,它只负责转发,不需要缓存巨大的长文本,也不用担心超时问题。
架构总结
这套“鉴权-网关-调度-执行”的分层架构,特别是“混合部署”与“异步回调”的设计,完美平衡了企业对于成本、安全与稳定性的三角约束。
- 对于开发者:只需要维护一套 Worker 模板,就能接入所有新出的开源模型。
- 对于业务方:既能用上最强的 GPT-4,又能保证核心财务数据的绝对安全,且不用担心长文本生成过程中的数据丢失问题。
这是构建商业级 RAG 平台不可或缺的基石。

















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









