






目录
一、激活函数:
激活函数是用来通过非线性变换以加入非线性因素的,因为线性模型的表达能力不够。
常见的几种激活函数包括:
1、sigmoid
-
该函数在LSTM模型的三个门(忘记门、输入门、输出门)中有使用,分别控制记住t-1时刻记忆的比例、记住t时刻记忆的比例、t时刻输出的比例;
-
该函数的输出范围为(0,1),以(0, 0.5)为对称中心; 当输入趋于负无穷时,输出趋近于0,当输入趋于正无穷时,输出趋近于1;
-
公式:
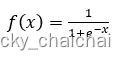
-
函数图:可见Sigmoid函数存在梯度消失(Gradient Vanishing)和不以0对称的问题,注意该函数很容易出现梯度消失。
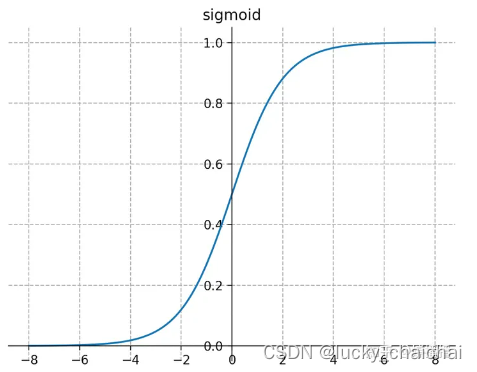
-
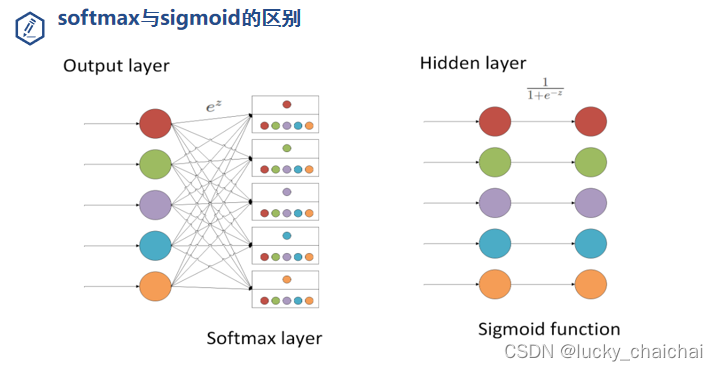
与softmax的区别:softmax一般作为神经网络的某一层,处理一组值;sigmoid则只是对每一个输出值进行非线性化。???
2、softmax
- 《attention is all you need》一文提出的attention计算过程中QK点乘后为归一化权重,有使用该函数。
- 其本质上是一种归一化函数,可以将长度为d的一组任意的实数值转化为在[0, 1]之间一组值(可以称为概率值),长度还为d。
- 如果该组实数其中一个数很小或为负,softmax将其变为小概率,如果很大,则将其变为大概率,但它将始终保持在0到1之间,且这组实数转化之后的所有值之和为1。
- 常被应用于分类任务(非多分类)的最后一层,zi为第i个节点的输出值,D为输出节点的个数,即分类的类别个数。公式:
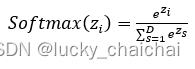
- 函数图:
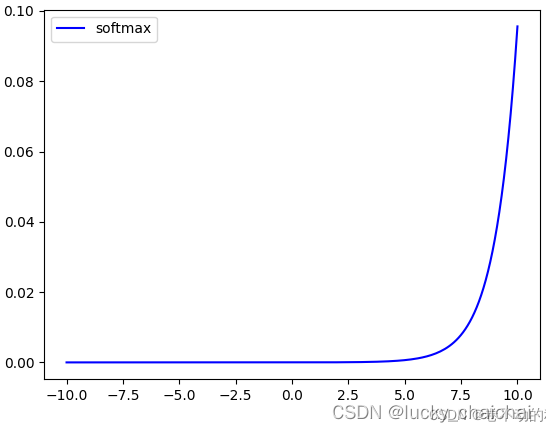
3、tanh
- 该函数在LSTM模型结构中有使用。
- 公式:
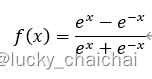
- 函数图像:存在梯度消失问题,tanh的导数取值范围为(0,1],虽然取值范围比sigmoid导数更广一些,可以缓解梯度消失,但仍然无法避免随着网络层数增多梯度连乘导致的梯度消失问题。
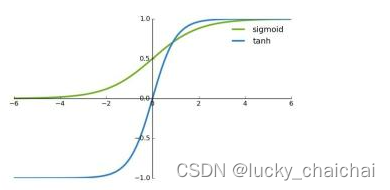
4、ReLU
- 公式:
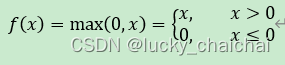
- 函数图像:可见当输入为正时,可以缓解梯度消失问题,但是容易出现梯度爆炸。
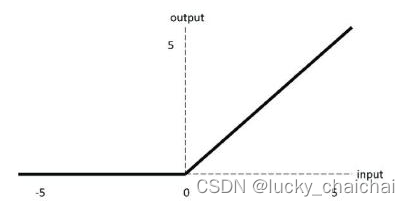
5、ReLU的拓展函数系列
下述激活函数主要是对ReLU函数负半轴的输出进行调整,使其不为0,从而使得输出为负值的神经元永久性dead。
(1)Leaky ReLU
- 函数公式:
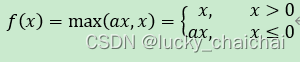
(2)ELU
- 函数公式:
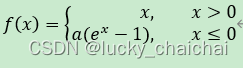
(3)SELU
- 函数公式:即在ELU的基础上引入一个缩放系数λ ;
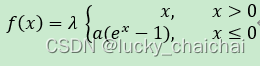
(4)PReLU
- 函数公式:
鉴于Leaky ReLU函数中引入了参数a,存在依赖人工调整的缺陷,因此,PReLU(Parametric ReLU)采用把a当成神经元的一个参数的思路,通过网络学习得到。
二、损失函数
估量模型的预测值f(x)与真实值y的不一致程度,损失函数值越小,一般代表模型的鲁棒性越好。
1、分类任务中的loss
(1)0-1 loss
- 直接比较预测值和真实值是否相等;
- 公式:
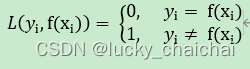
(2)交叉熵loss(cross-entropy loss)
- 公式:
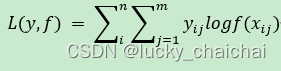
其中,n为样本数,m为类别数,yij为第 i 个样本属于类别 j 的标签,属于则为0,不属于则为1;f(xij)是样本 i 预测为 j 分类的概率。 - 可见,loss的大小完全取决于分类为正确标签那一类的概率,当所有的样本都分类正确时,loss=0。
(3)softmax cross-entropy loss(softmax loss)
- 交叉熵loss的一个特例,只不过是将交叉熵loss中的f(xij)的表现形式换成softmax概率的形式。
(4)Hinge loss
- 公式:
L(y, f(x)) = max(0, 1-yf(x)) - 如果分类正确,loss=0;
- 一般用来解SVM问题中的间距最大化问题。
(5)Exponential loss
- 指数形式的loss,特点是梯度比较大;
- 主要用户Adaboost集成学习算法;
- 公式:
L(y, f(x)) = e-βyf(x)
(6)logistic loss
- 公式:
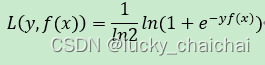
- 取了Exponential loss的对数形式,梯度相对变化比较平缓。
2、回归任务中的loss
(1)L1 loss
- 即最小绝对值偏差(LAD),或最小绝对值误差(LAE);
- 公式:
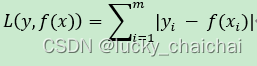
(2)L2 loss
- 即最小平方误差(LSE);
- 公式:
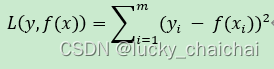
以上(1)(2)与MSE、MAE损失函数是一个 1/n 的区别。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









