







目录
一、pyhanlp
【基于java的,安装使用前必须先安装java环境】
1、安装:pip install pyhanlp
【安装过程中会自动安装jpype1,该模块仅支持到python3.7,所以python3.7以上的安装老是报错。】
2、使用:
1)分词
import pyhanlp
print([i.word for i in pyhanlp.HanLP.segment('我们都是中国人,坚持一个中国原则。')])

二、stanfordnlp
【官方GitHub介绍:https://stanfordnlp.github.io/stanfordnlp/training.html】
1、安装:pip 安装
pip install stanfordnlp --proxy 111.666.88.688:808
2、简单使用
import stanfordnlp
三、pyltp
【学习手札:https://blog.youkuaiyun.com/MebiuW/article/details/52496920 】
【基于C++的】
四、openNRE
GitHub:https://github.com/thunlp/OpenNRE#datasets
清华大学自然语言处理与社会人文计算实验室(THUNLP)推出的一款开源的神经网络关系抽取工具包,包括了多款常用的关系抽取模型。
使用wiki80数据集,包含80种关系。(也可以自己训练)
但是都是英文数据集,使用也都是基于英文的……
1、安装:我安装到windows上了
cmd中下载git相关安装文件:
git clone https://github.com/thunlp/OpenNRE.git
安装requirements.txt中的模块(括号中是我安装的模块版本)
torch==1.6.0 (1.9.0)
transformers==3.4.0 (4.21.3)
pytest==5.3.2
scikit-learn==0.22.1 (0.23.2)
scipy==1.4.1 (1.4.1)
nltk>=3.6.4 (3.6.2)
安装openNRE
python setup.py develop
2、使用
【注意】
1)windows在导入包的时候会报错:TypeError: expected str, bytes or os.PathLike object, not NoneType
原因:opennre中的pretrain.py中的第13行在windows运行出错(os.getenv(‘HOME’)获取用户主文件地址,windows没有home地址)。
改为:
# default_root_path = os.path.join(os.getenv('HOME'), '.opennre') # Linux
default_root_path = os.path.join(str(Path.home()), 'opennre') # cqf: windows
2)windows在opennre.get_model(‘wiki80_cnn_softmax’)获取模型时报错:wget不是内部执行命令
原因:wget 是一个Linux环境下用于从万维网上提取文件的工具,windows使用时需要单独安装。
安装:①在网站 https://eternallybored.org/misc/wget/ 上下载windows 上适用的安装包(最新版就可);
②下载完成后解压:比如我下载的是 wget-1.21.3-win64.zip ,解压到 D:\software\wget-1.21.3-win64;
③添加环境变量:比如我的
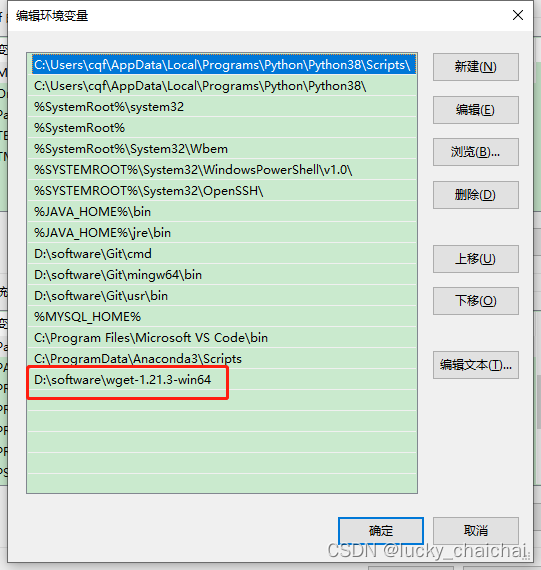
导入模块、加载模型、预测
>>> import opennre
>>> model = opennre.get_model('wiki80_cnn_softmax') # 模型还包括:wiki80_bert_softmax、wiki80_bertentity_softmax、tacred_bert_softmax、tacred_bertentity_softmax
>>> model.infer({
'text': 'Huang Xiaoming starred in the TV series "the emperor of Han Dynasty", in which he played Emperor Wu of Han Dynasty.', 'h': {
'pos':(0,13)}, 't': {
'pos':(41,66)}})
('notable work', 0.96822190284729)
五、基于TensorFlow 2自定义NER模型(构建、训练与保存模型范例)
NER实质:对目标句子序列进行特征向量表示,然后输入模型,预测句子中每个词对应所有 class 的概率,概率最高的即为其标注结果。
环境要求:(keras4bert环境要求后面单独说明)
keras_bert.__version__ = 0.88.0 # 要求keras >= 2.4.3
keras.__version__ = 2.4.3
tf.__version__ = 2.5.0
tfa.__version__ = 0.16.1
transformers.__version__ = 4.9.1
超参:
# 超参
config_path='data/chinese_L-12_H-768_A-12/bert_config.json'
check_point_path='data/chinese_L-12_H-768_A-12/bert_model.ckpt'
seq_len=200
layer_nums=4 # keras_bert加载BERT时参数output_layer_num的值,BERT模型每个encoder的MultiHeadSelfAttentio层数
training=False
trainable=False
num_label=4
drop_rate=0.3
is_training=True
hidden_size=600
TransBERT_MODEL_NAME='data/bert-base-uncased'
1、BiLSTM+CRF模型
理解说明:
CRF作用:①训练过程中作为损失函数,计算loss;②预测过程中,用于解码,获取得分最高的句子标记结果。
CRF的解码函数:
tfa.text.crf_decode()获取CRF解码结果,即最高分数的句子标记结果,返回结果包括:
① decode_tags: A [batch_size, max_seq_len] matrix, with dtype tf.int32. Contains the highest scoring tag indices.
② best_score: A [batch_size] vector, containing the score of decode_tags.
代码算法图:

1、模型构建
import tensorflow as tf
import tensorflow_addons as tfa # 需单独安装
# 基于tf.keras.layers.Layer类定义一个自己的CRF层
class CRF(tf.keras.layers.Layer):
def __init__(self, label_num) -> None:
super().__init__()
self.trans_params = tf.Variable(
tf.random.uniform(shape=(label_num, label_num)), name="transition")
def call(self, inputs, labels, seq_lens):
log_likelihood, self.trans_params = tfa.text.crf_log_likelihood(
inputs, # tensor:[batch_size, max_seq_len, num_tags]
labels, # tensor:[batch_size, max_seq_len]
seq_lens, # seq_lens为各个句子的真实长度(不包括padding的部分,本模型训练也将不存在于vocab中的部分排除)
transition_params=self.trans_params)
loss = tf.reduce_mean(-log_likelihood)
return loss
class BiLSTM_CRF_model(tf.keras.Model):
def __init__(self, embedding_dim, vocab_size, hidden_size, label_num) -> None:
super().__init__()
self.embeding_layer=tf.keras.layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=None, #Length of input sequences,如果该层后面连接flatten并dense则必须指定input_length。
embeddings_initializer='uniform')
self.bilstm_layer=tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(hidden_size, return_sequences=True),
merge_mode='concat')
self.dense = tf.keras.layers.Dense(label_num)
self.crf_layer=CRF(label_num)
def call(self, input, labels=None, externalEmbed_file=None, training=True):
# tf.math.not_equal()比较x、y相等情况,返回bool类型的tensor,shape同x或y
# tf.cast()强制将给定数据转换为指定数据类型
seq_lens=tf.math.reduce_sum(tf.cast(tf.math.not_equal(input, 0), dtype=tf.int32), axis=-1) # 计算各个橘子的真实长度
if externalEmbed_file:
x=tf.nn.embedding_lookup(externalEmbed_file, input)
else:
x=self.embeding_layer(input)
x=self.bilstm_layer(x)
logits=self.dense(x) # 得到CRF的输入[batch_size, max_seq_len, num_tags]
if training:
labels = tf.convert_to_tensor(labels, dtype=tf.int32)
loss=self.crf_layer(logits, labels, seq_lens)
return loss, logits, seq_lens
else:
return logits, seq_lens
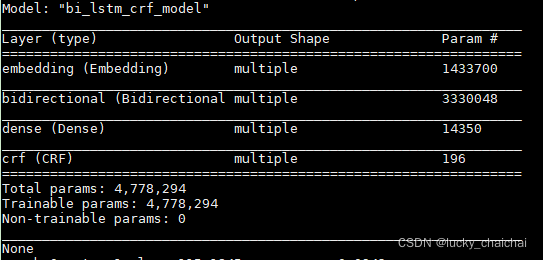
继承tf.keras.Model类构建的模型结构:
2、模型训练与保存:
def get_acc_one_step(logits, text_lens, labels_batch, model):
'''
【这个计算方式不是很好( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









