







 本文介绍gensim库中Word2Vec、Doc2Vec的使用方法,包括模型训练、词向量获取及相似度计算等,并探讨了TF-IDF模型的应用。此外,还概述了几种常用的位置编码方式,如正余弦位置编码和旋转位置编码。
本文介绍gensim库中Word2Vec、Doc2Vec的使用方法,包括模型训练、词向量获取及相似度计算等,并探讨了TF-IDF模型的应用。此外,还概述了几种常用的位置编码方式,如正余弦位置编码和旋转位置编码。
目录
一、基于gensim(版本:3.8.3)的Word2vector
【进行token2id,方便后续利用word2vector进行embedding】
1、W2V模型训练
import pprint
import gensim
from gensim.models.word2vec import Word2Vec
from gensim.corpora.dictionary import Dictionary
sentense='按我的理解,优化过程的第一步其实就是求梯度。这个过程就是根据输入的损失函数,提取其中的变量,进行梯度下降,使整个损失函数达到最小值。'
sentense_words=[[w for w in jieba.cut(sentense) if w not in [',','。','的']]] # 若不分词,直接将句子作为sentense_words的元素,输入到Word2Vec得到的是字向量。
w2v_model=Word2Vec(sentense_words,
size=25, # 词向量维度
min_count=1, # 词频阈值
window=5,
workers=6, # Use these many worker threads to train the model
sg=1, # Default 0, 1 for skip-gram; otherwise CBOW.
hs=1, # Default 0(使用w2v_model.syn1时必须为1), If 1, hierarchical softmax(Huffman Softmax) will be used for model training. If 0, and negative is non-zero, negative sampling will be used.
iter=10) # 参数还有很多,包括negative=5,表明使用负采样,并指定负采样使用的“噪音词数”
# 另外,可以基于gensim的词向量模型生成LDA的输入corpus:[[(词索引, 词频),...],]
from gensim import corpora
dictionary = corpora.Dictionary(sentences_cutted_list) # 将documents中的所有词进行索引编码,循环dictionary.items()可以打印出每个词的索引及词,参数必须是list[list]
corpus = [dictionary.doc2bow(text) for text in sentences_cutted_list] # [[(词索引, 词频),...],]
2、W2V模型使用:获取词、词向量、词之间词向量比较等
# 获取词典
wv_vocab = w2v_model.wv.vocab
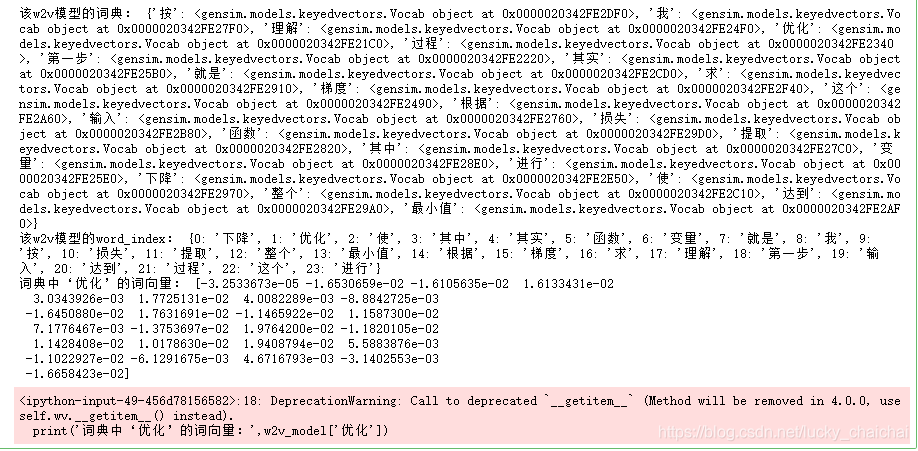
print('该w2v模型的词典:', wv_vocab)
# 获取所有词
wv_word1 = w2v_model.wv.vocab.keys() # 结果:dict_keys(['按', '我', '理解', '优化', '过程', '第一步', '其实', '就是', '求', '梯度', '这个', '根据', '输入', '损失', '函数'])
wv_word12 = w2v_model.wv.index2word # 结果:['过程', '就是', '按', '我', '理解', '优化', '第一步', '其实', '求', '梯度', '这个', '根据', '输入', '损失', '函数']
# 生成{word: index}
dictionary=Dictionary()
dictionary.doc2bow(w2v_model.wv.vocab.keys(), allow_update=True) # 对所给的词表生成word-index对照
print('该w2v模型的word_index:',{k:v for k,v in dictionary.items()})
# 获取某个词的词向量(改词必须包含在模型词典中)
print('词典中‘优化’的词向量:',w2v_model['优化'])
# 获取词向量的大矩阵,第i行表示vocab中下标为i的词
vec = w2v_model.wv.syn0 # vec为array类型,gensim4.0.0之后使用 w2v_model.wv.vectors
上述结果:
3、W2V的保存和加载
模型保存:
w2v_model.save(file_W2V_model) # 保存完整模型,可以加载后进行再训练
w2v_model.wv.save_word2vec_format(file_W2V_model_vector, binary=False) # 保存词及其对应的词向量
(注:保存词及其向量时,文件第一行为:词数 向量维度,一般文件格式为TXT或bin)
加载保存的w2v模型:
两种保存方式分别对应的加载方式:


(注:第二种方法model = gensim.models.KeyedVectors.load_word2vec_format(file_name),可以使用model.vocab,获取词与词不知道的啥,如下:

4、判断模型中是否包含某个词,并获取该词的词向量:
对于load方法加载的模型self.w2v(save保存的):
# 4.0版本之前的gensim
emb=[]
if word in self.w2v:
emb.append(self.w2v[word])
# 4.0版本之后的gensim(4.0之前版本也可以使用这个方法)
if word in self.w2v.wv:
emb.append(self.w2v.wv[word])
对于KeyedVectors.load_word2vec_format()方法加载的模型self.w2v(wv.save_word2vec_format保存的):
# 4.0版本之前的gensim
if word in self.w2v.vocab:
emb.append(self.w2v[word])
4、TF-IDF模型
def tfidf_embedding_byGens(self, content_cutted):
'''
基于gensim训练TF模型, 并得到训练语料在当前TF模型下的tf值
return:
tfidf_model: TF model
dictionary:
corpus_idf: 训练语料在当前TF模型下的tf向量(<gensim.interfaces.TransformedCorpus object at 0x0000012BA918A4C0>),
当content_cutted是单个文本时,like: [(51, 0.20519567041703082), (61, 0.10259783520851541), (64, 0.10259783520851541), (68, 0.10259783520851541),
(70, 0.10259783520851541), (71, 0.10259783520851541), (74, 0.30779350562554625)]
'''
# 基于分好词的文本集,生成词典
dictionary = corpora.Dictionary(content_cutted)
# 通过doc2bow稀疏向量生成语料库
corpus = [dictionary.doc2bow(item) for item in content_cutted]
# 基于语料库和TF算法,得到TF模型
tfidf_model = models.TfidfModel(corpus)
# 通过得到的TF模型,得到语料的tf向量
corpus_idf = tfidf_model[corpus]
return tfidf_model, dictionary, corpus_idf
doc2bow功能:Convert document into the bag-of-words (BoW) format = list of (token_id, token_count) tuples.
corpus = [dictionary.doc2bow(item) for item in contents_cutted] # item为: list of str
#corpus,可作为models.TfidfModel的corpus:结果[[((67, 1), (68, 1), (69, 1), (70, 1), (71, 1), (72, 2), (73, 1), (74, 3), (75, 1), (76, 3)], [(0, 6), (5, 1), (11, 6), (13, 3), (14, 2), (20, 3), (33, 1), (36, 1), (37, 1), (39, 4)]
5、相似度计算
通过TF模型得到的tf向量可以直接输入相似度模块,计算两个向量(集)(corpus_idf、vec_aim)的相似度:
from gensim import corpora, models, similarities
num_features = len(dictionary.token2id.keys())
index = similarities.Similarity(
output_prefix = None,
corpus = corpus_idf,
num_features = num_features
)
sim = index[vec_aim] # vec_aim为与corpus_idf形式一样的向量
二、Glove
1、下载安装:https://github.com/stanfordnlp/GloVe
下载GitHub上整个文件:
2、linux训练词向量(参考:https://blog.youkuaiyun.com/Totoro1745/article/details/82286483
【是基于C语言环境的,所以必须保证有gcc】
1)在当前路径下运行:make
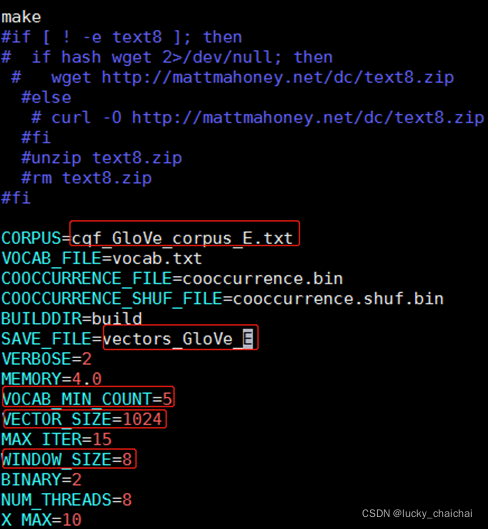
2)修改demo.sh的内容
demo.sh文件:
3)开始训练
运行demo.sh文件:sh demo.sh
4)训练完成后,使用python中gensim模块调用,然后跟gensim的word2vec模型一样使用:

(注:将glove词向量文件转化为word2vec文件:)

三、基于gensim的句向量:Doc2Vec
doc2vec英文原文
训练doc2vec的两种方式:
PV-DM:每一句话用唯一的向量来表示,用矩阵D的某一列来代表。每一个词也用唯一的向量来表示,用矩阵W的某一列来表示。每次从一句话中滑动采样固定长度(window)的词,取其中一个词作预测词,其他的作为输入词。输入词对应的词向量Word Vector和本句话对应的句子向量Paragraph vector作为输入层的输入,将本句话的向量和本次采样的词向量相加求平均或者累加构成一个新的向量X,进而使用这个向量X预测此次窗口内的预测词。
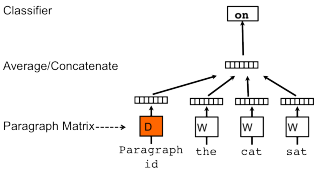
PV-DBOW:句子向量Paragraph vector作为输入(刚开始的时候进行初始化),在每次迭代的时候,从文本中采样得到一个窗口,再从这个窗口中随机采样一个单词作为预测任务,让模型去预测。
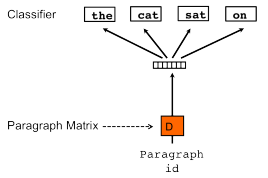
from gensim.models.doc2vec import Doc2Vec,TaggedDocument
tagged_data = [TaggedDocument(words=_d, tags=[str(i)]) for i, _d in enumerate(content_cutted)]
d2v_model=Doc2Vec(documents= tagged_data,
dm=1, # If `dm=1`(Default), 'distributed memory' (PV-DM) is used; Otherwise, `distributed bag of words` (PV-DBOW) is employed.
vector_size=125, # Default 100.
window=5,
min_count=3
)
# 获取tag是8的句向量
print(d2v_model.docvecs['8']) # array类型,效果同d2v_model[8]==d2v_model.docvecs[8]
# 获取tag=1的句子与其他句子的相似度
print(d2v_model.docvecs.most_similar('1')) # 计算tag=‘1’的句子与其他所有句子的cosin相似度[('5', 0.9994447231292725), ('8', 0.9993512630462646)]
# 获取tag=0和tag=1两个句子的相似度
print(d2v_model.docvecs.similarity('0','1')) # 0.9992348
保存和加载(方式同word2vec):下面两种方式效果一样
# 方式一
self.d2v_model.save('data/word2vector_model.model')
self.d2v_model.save_word2vec_format('data/word2vector.txt')
# 方式二
Doc2Vec.save(self.d2v_model, model_file)
Doc2Vec.save_word2vec_format(self.d2v_model, vec_file)
四、基于Langchain的一些开源词向量模型的操作
1、常见的一些开源词向量模型:
- 可以从modelscope或者hunggingface下载;
- 模型文件pytorch_model.bin、model.safetensors等;如:

embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh", # 向量维度312,如果是本地文件可以使用绝对文件路径,如E:/CQF/work_yanxue/AI_yanxue/LLM/models/embedding_model/ernie-3.0-nano-zh
"ernie-base": "nghuyong/ernie-3.0-base-zh", # 向量维度768,E:/CQF/work_yanxue/AI_yanxue/LLM/models/embedding_model/ernie-3.0-base-zh
"text2vec-base": "shibing624/text2vec-base-chinese", # 向量维度768,E:/CQF/work_yanxue/AI_yanxue/LLM/models/embedding_model/text2vec-base-chinese
"text2vec": "GanymedeNil/text2vec-large-chinese", # 向量维度1024,E:/CQF/work_yanxue/AI_yanxue/LLM/models/embedding_model/text2vec-large-chinese
"text2vec-paraphrase": "shibing624/text2vec-base-chinese-paraphrase",
"text2vec-sentence": "shibing624/text2vec-base-chinese-sentence",
"text2vec-multilingual": "shibing624/text2vec-base-multilingual",
"text2vec-bge-large-chinese": "shibing624/text2vec-bge-large-chinese",
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base", # 向量维度768,E:/CQF/work_yanxue/AI_yanxue/LLM/models/embedding_model/m3e-base
"m3e-large": "moka-ai/m3e-large",
"bge-small-zh": "BAAI/bge-small-zh",
"bge-base-zh": "BAAI/bge-base-zh",
"bge-large-zh": "BAAI/bge-large-zh", # 向量维度1024,E:/CQF/work_yanxue/AI_yanxue/LLM/models/embedding_model/bge-large-zh
"bge-large-zh-noinstruct": "BAAI/bge-large-zh-noinstruct",
"piccolo-base-zh": "sensenova/piccolo-base-zh",
"piccolo-large-zh": "sensenova/piccolo-large-zh",
"text-embedding-ada-002": os.environ.get("OPENAI_API_KEY"),
"e5-base": "multilingual-e5-base" # 向量维度768,E:/CQF/work_yanxue/AI_yanxue/LLM/models/embedding_model/multilingual-e5-base
}
2、基于langchain的调用方式:
Huggingface方式的调用,如果本地没有模型文件,会自动取huggingface下载。
from langchain.embeddings import \
HuggingFaceBgeEmbeddings # 需要langchain==0.0.266, transformers>=4.31.0, torch~=2.0.0, sentence-transformers
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.embeddings.openai import OpenAIEmbeddings
# make HuggingFaceEmbeddings hashable
def _embeddings_hash(self):
if isinstance(self, HuggingFaceEmbeddings):
return hash(self.model_name)
elif isinstance(self, HuggingFaceBgeEmbeddings):
return hash(self.model_name)
elif isinstance(self, OpenAIEmbeddings):
return hash(self.model)
HuggingFaceEmbeddings.__hash__ = _embeddings_hash
OpenAIEmbeddings.__hash__ = _embeddings_hash
HuggingFaceBgeEmbeddings.__hash__ = _embeddings_hash
def load_embeddings(model: str, device: str):
if model == "text-embedding-ada-002": # openai text-embedding-ada-002
embeddings = OpenAIEmbeddings(openai_api_key=embedding_model_dict[model], chunk_size=CHUNK_SIZE)
elif 'bge-' in model:
embeddings = HuggingFaceBgeEmbeddings(model_name=embedding_model_dict[model],
model_kwargs={'device': device},
query_instruction="为这个句子生成表示以用于检索相关文章:")
if model == "bge-large-zh-noinstruct": # bge large -noinstruct embedding
embeddings.query_instruction = ""
else:
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[model], model_kwargs={'device': device})
return embeddings
if __name__ == '__main__':
sentence1 = "作为北京大学的研究生,如果违反了基本学术规范会有哪些后果?"
sentence2 = "我喜欢小动物。"
sentence3 = "我今天心情很差。"
embeddings = load_embeddings('bge-large-zh', 'cpu')
embedding1 = embeddings.embed_query(sentence1)
# print(len(embedding1))
print(embedding1)
五、基于sentence_transformers的词嵌入
- 模型可以从modelscope或者huggingface下载;
- 模型文件pytorch_model.bin、model.safetensors等,示例与四部分一样;
from sentence_transformers import SentenceTransformer
model_dir = 'E:\\CQF\\work_yanxue\\AI_yanxue\\LLM\\models\\vector_model\\AI-ModelScope\\m3e-base'
def embedding(sentences):
'''
sentences: 多个句子组成的list
'''
model = SentenceTransformer(model_dir)
#Sentences are encoded by calling model.encode(),return numpy.array
embeddings = model.encode(sentences)
# print(embeddings.shape)
#Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
return embeddings
六、常用的一些位置编码(position_embedding)
1、可学习的位置编码方式
随机对位置编码进行初始化,然后与word embedding(word_emb)等向量结合,跟随模型训练一起学习。
pos_emd = random()
emb = word_emb + pos_emb 或 emb = concat(word_emb, pos_emb )
2、正余弦位置编码
即Sinusoidal位置编码,《attention is all you need》的transformer中提到的一种绝对位置编码方式:
PE(pos, 2i) = sin(pos / 100002i = dmodel)
PE(pos, 2i+1) = cos(pos / 100002i = dmodel)
其中,pos为position,i为dimension,dmodel同模型的word_emb维度,方便后续与word_emb计算。
3、相对位置编码
-
传统transformer中的self-attention计算如下:
- 输入序列是:x = (x1, …, xi, …, xn),其中xi∈Rdx
- 计算得到的输出序列为:z = (z1, …, zi, …, zn),其中zi∈Rdz
- 参数矩阵WQ、WK、WV ∈ Rdx×dz
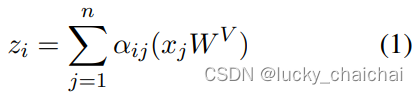 ,
,
其中的aij如下:
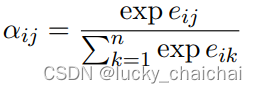 ,
,
其中的eij如下(也就是softmax的计算方式):
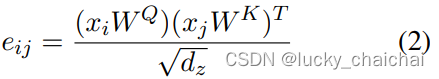
-
优化后,在self-attention计算过程中加入xi、xj之间的相对位置信息:
- 即公式(3)替换(1),(4)替换(2);
- 下述公式中aijK,aijV ∈Rda,是表示xi、xj相对位置的可学习向量(可训练的相对位置编码),计算方式下面有详细描述;
- 注意:计算相对位置编码时,前提假设是,一定距离之外的准确相对位置信息是无用的,所以将最大相对位置长度设置为k,最终需要训练的相对位置编码矩阵shape=(2k+1, da)
- dz = da;
- 最初来源自《Self-Attention with Relative Position Representations》。
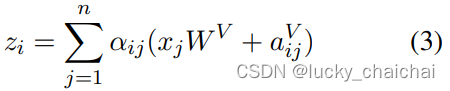
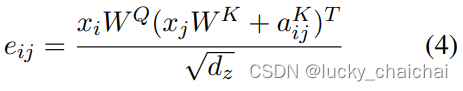 ,
,
其中aijK,aijV ∈Rda,计算方式:
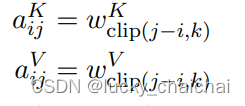 ,
,
其中,clip(x, k)为:
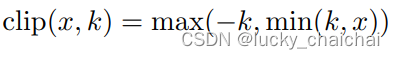 ,
,
也就是aijK,aijV都是从 位置编码的Embeding向量矩阵(即下面的wK、wV,shape=(2k+1, da)) 中去lookup,
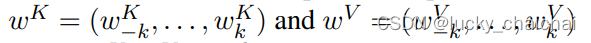
- lookup的具体方式如下(以wK为例,wV与其lookup方式相同):
关键的两点:
①计算zi时,中心词即为第i个词,其位置编码对应wK向量矩阵中的W0K,其他词相对于它的位置编码则根据相对位置得到;
②如果其他词的位置超过了中心词的左右距离k,那么其右边超过k的全部置为k索引的向量,左边超过k的全部置为-k索引的向量;
具体编码方式如下:
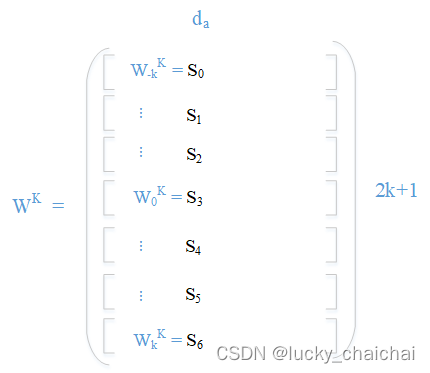
设要处理的文本序列为“我的人生听我的”,k=3,则 可学习的、位置编码的Embeding向量矩阵如下:
其中黑色Si为向量矩阵wK按照正常索引的子向量(为方便理解 按索引 进行lookup),
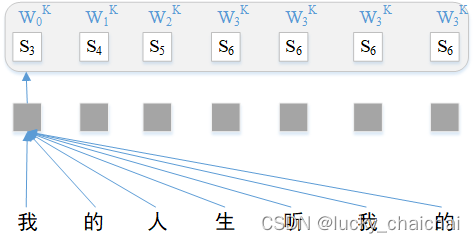
①当计算z1时,此时中心词为第一个字“我”,其位置编码为W0K,按照索引获取也就是S3,最终lookup得到该文本序列的相对位置编码a1jK(j∈[1, 7])如下:
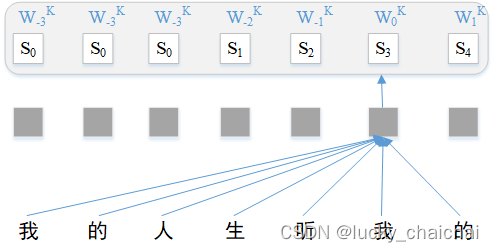
②当计算z6时,此时中心词为第六个字“我”,其位置编码为W0K,按照索引获取也就是S3,最终lookup得到该文本序列的相对位置编码a6jK(j∈[1, 7])如下:
4、XLNET式位置编码
- 源自Transformer-XL的论文《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》
- 该方法也是在attention结构中加入了位置编码,只不过仅在Attention矩阵计算中(QKT)上加入位置编码,不加到V上了,且位置编码使用的是“正余弦位置编码”。
- 另外,T5式、DeBERTa式也都是在attention结构中加入位置编码,且仅在ttention矩阵计算中(QKT)上加入,在此不做详细介绍,分别可参考原文:《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》、《DeBERTa: Decoding-enhanced BERT with Disentangled Attention》
5、旋转位置编码(Rotary Position Embedding,RoPE)
- 苏神的杰作,用他的话说“这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。”。
公式太多了,不容易理解,没仔细看…… - LLaMa的基础模型架构中的transformer使用的位置编码即为该编码方式;
详细推理过程参考Transformer升级之路:2、博采众长的旋转式位置编码
其他:关于位置编码,更为详细的分类介绍见苏神的《领研究人员绞尽脑汁的Transformer位置编码》。


















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









