




在信息爆炸的时代,排序精选类算法无处不在,它决定了我们看到什么、先看到什么。从搜索引擎的搜索结果、社交媒体的朋友圈动态,到电商平台的商品列表,甚至是短视频的热门榜单,背后都有排序精选类算法的身影。它们通过对海量信息的组织和筛选,帮助用户高效获取所需内容。
然而,随着《互联网信息服务算法推荐管理规定》的深入实施,对这类具有广泛影响力的算法进行合规备案已成为企业的必要责任。截至2025年7月份,全国总共有57个排序精选类算法备案通过,本文将结合备案系统的实际界面,为您提供一份详细、易懂的“排序精选类算法备案”操作指南,助您一步步完成备案,确保业务在合规轨道上稳健运行。
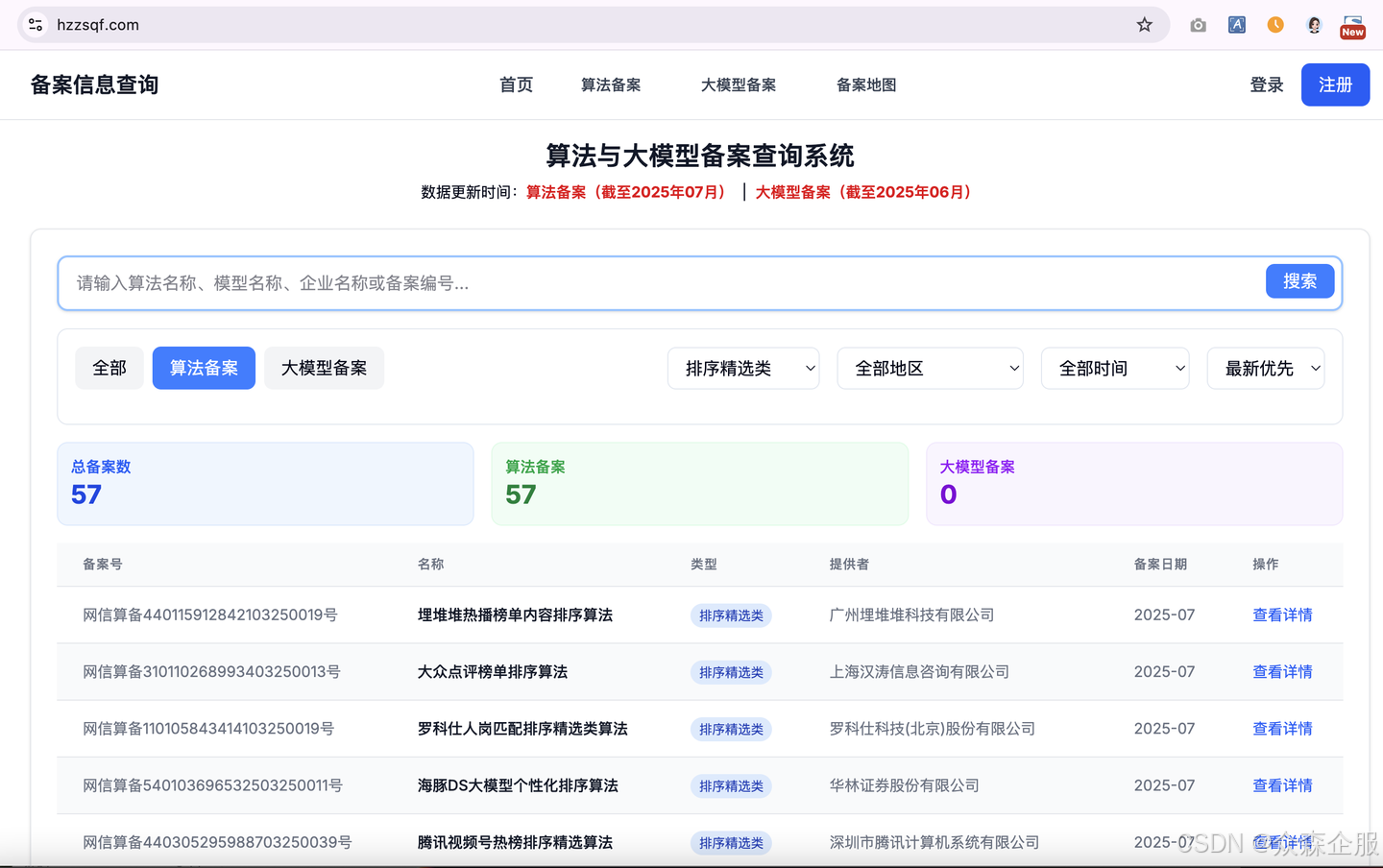
第一步:理解排序精选类算法的核心概念
在开始备案前,我们首先要明确什么是“排序精选类”算法。
什么是“排序精选类算法”?
根据相关规定,“排序精选类算法”是指以客观因素或主观因素为依据,设置、调整网络信息内容排列顺序的算法。
排序精选核心特征:
- 内容排序与筛选:核心功能是对信息内容进行排列、筛选和呈现。
- 依据多样:可能基于客观因素(如发布时间、用户互动数据、权威性)或主观因素(如算法策略设定的权重、用户偏好)。
- 影响信息获取:直接决定用户看到信息的先后顺序和呈现方式。
排序精选典型应用场景:
这类算法广泛应用于各种需要对信息进行组织和呈现的平台:
- 搜索引擎:搜索结果的排序。
- 社交媒体:好友动态、热门话题、趋势榜单的排序。
- 新闻资讯平台:新闻列表、头条推荐的排序。
- 电商平台:商品列表的排序(如按销量、价格、综合等)。
- 短视频平台:热门视频、推荐视频的排序。
第二步:排序精选算法备案流程概述与系统填报详解
排序精选类算法备案的整体流程与其他算法备案类似,通常包括主体备案、算法部分备案和产品备案部分三个阶段。
办理流程:
- 主体备案:提交企业基本信息,审核周期约5-7个工作日。
- 算法部分备案:提交算法详细信息,审核周期约10-20个工作日。
- 产品及功能信息备案:与算法部分同步进行,提交算法对应的产品信息(如APP、小程序、网页端等)。
- 公示与下发备案号:网信办每两个月左右会公示一批备案通过的名单,并下发备案号。
接下来,我们结合备案系统中的关键填写模块,手把手教您如何操作。
2.1 填写算法基础属性信息
这是备案的第一步,您需要对算法类型进行选择和概括性描述。
- 算法类型:从下拉菜单中选择“排序精选类”。
- 算法名称:填写您的算法具体名称,例如“众森企服排序精选算法”。
- 上线时间:选择您的算法投入实际使用的时间。
- 版本号:填写算法当前的版本号。
- 应用领域:填写您的算法主要应用的行业领域,如“新闻资讯”、“社交媒体”、“电子商务”等。
- 安全自评估报告:下载系统提供的模板,按照要求填写并上传。这份报告是备案的核心材料之一,需要详细说明算法在安全性、合规性方面的自我评估结果。
- 拟公示内容:上传您在产品中向用户公示的算法规则文本。这体现了算法的透明度。
2.2 填写算法详细属性信息
此部分是对算法具体运行机制的深入描述。
- 算法简介:用200字以内简洁明了地对算法进行描述,具体描述内容包括算法使用了哪些数据、算法作用的对象、算法的目的意图(或优化目标)、算法结果的展现形式、算法应用的主要互联网产品。
- 使用场景:从系统提供的选项中选择或填写您的算法应用的具体场景,例如:资讯、新闻、商品、音视频等。
- 输入数据信息:此部分需要您说明算法处理的数据类型。
- 客观数据:选择或填写算法基于的客观数据,如:内容发布时间、点击量、互动量、转发量、点赞量、评论量等。
- 外部环境数据:填写算法可能参考的外部环境数据,如:实时热点、事件相关性、时事新闻等。
- 其他输入数据:填写其他您认为重要的输入数据。
数据统计口径:选择或填写您的数据统计方式,确保数据的准确性和一致性。- 输出结果展示方式:选择或填写算法最终的输出结果如何呈现给用户,例如:列表排序、热门榜单、精选推荐等。
2.3 算法模型填写
此模块需要您对算法模型的构建、数据来源和运行逻辑进行描述。
- 训练数据来源
:- 开源数据集 & 来源:如果您使用了开源数据集,需填写数据集名称和具体来源。
- 自建数据集 & 来源:如果您有自己的数据集,需填写数据集名称和具体来源。
- 合作数据集 & 来源:如果您与第三方合作获取数据,需填写数据集名称和具体来源。
- 训练数据是否包括境外数据:根据实际情况选择“是”或“否”。如果涉及境外数据,需特别注意跨境数据传输的合规要求。
- 训练数据产生方式:选择训练数据的产生方式,如随机抽样、人工选取等。
排序模型类型:选择您使用的排序模型类型,如线性、非线性、深度等。- 模型计算时间窗口:输入模型进行计算的时间周期。
- 模型参数计算方式:选择模型参数的计算方式。
- 算法排序依据:选择或填写算法进行排序的具体依据。这可能是最能体现排序精选类算法核心竞争力的部分,需要清晰说明。
- 算法更新频率:选择您的算法更新的频率,如实时、每日、每周、每月等。
2.4 算法策略填写
此部分关注算法的运行策略和干预机制。
- 是否对排序精选内容分级分类管理:选择“是”或“否”。建议选择“是”,并说明如何对内容进行分级分类,以便于精细化管理和风险控制。
- 对排序精选内容的审核机制:选择或填写您如何对排序精选内容进行审核。这包括人工审核、机器审核、敏感词过滤等。
- 排序精选内容的
人工干预机制:选择或填写您如何对排序精选内容进行人工干预。例如:- 是否设立人工运营团队对榜单、推荐内容进行人工调整。
- 用户是否可以通过举报、投诉等方式反馈不当排序结果,并有专人处理。
2.5 算法风险与防范机制
这是备案中最为关键且容易被驳回的部分,体现了您对算法合规和风险防范的重视。系统界面通常会要求您选择或填写具体的保障机制。
- 内容生态保障机制:选择或填写您如何保障内容生态健康。这包括对排序内容的审核机制,确保不传播违法违规信息,以及对未成年人的内容保护。
- 是否具备打击刷榜行为的发现机制:对于榜单或排序功能,刷榜是常见问题。需要说明您是否有技术或管理手段发现并打击刷榜、虚假点赞、虚假评论等行为。
- 是否控制榜单中涉嫌不实信息占比:选择“是”或“否”。这是对信息真实性的重要考量,建议选择“是”并说明相关控制机制。
2.6 产品及功能信息备案(第三步)
完成前两步算法信息的填写后,备案系统会引导您进入“产品及功能信息”备案环节。这一步需要您录入依托该排序精选算法运行的产品信息。
- 产品类型:选择您的产品形式,如APP、小程序、网页端等。
- 产品名称:填写产品的具体名称,如“XX新闻APP”、“XX短视频小程序”。
- 访问地址:算法产品的服务地址。
- 状态及产品的服务对象:算法产品的运行状态及主要服务对象群体等。
排序精选类算法备案是企业在数字时代合规运营的重要保障。它不仅是遵守法律法规的要求,更是维护平台生态健康、提升用户体验、赢得用户信任的关键。
在提交备案前,强烈建议您对照本文及备案系统要求,逐项核查信息完整性和准确性。对于涉及复杂技术细节的部分,可与您的技术团队密切沟通,确保描述真实、准确。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











