




在海量信息的互联网世界里,检索和过滤算法是我们获取所需内容的关键“导航员”。无论是在搜索引擎中输入关键词查找资料,还是在电商平台中筛选商品,抑或是在内容平台中过滤不感兴趣的信息,都离不开检索过滤类算法的强大支持。它们帮助用户快速、精准地找到信息,屏蔽无效或干扰内容。
然而,随着《互联网信息服务算法推荐管理规定》的深入实施,对这类广泛应用且至关重要的算法进行合规备案已成为企业必须完成的任务。截至2025年7月份,全国总共有194个检索过滤类算法备案通过,本文将结合备案系统的实际界面,为您提供一份详细、易懂的“检索过滤类算法备案”操作指南,助您一步步完成备案,确保业务在合规轨道上稳健运行。
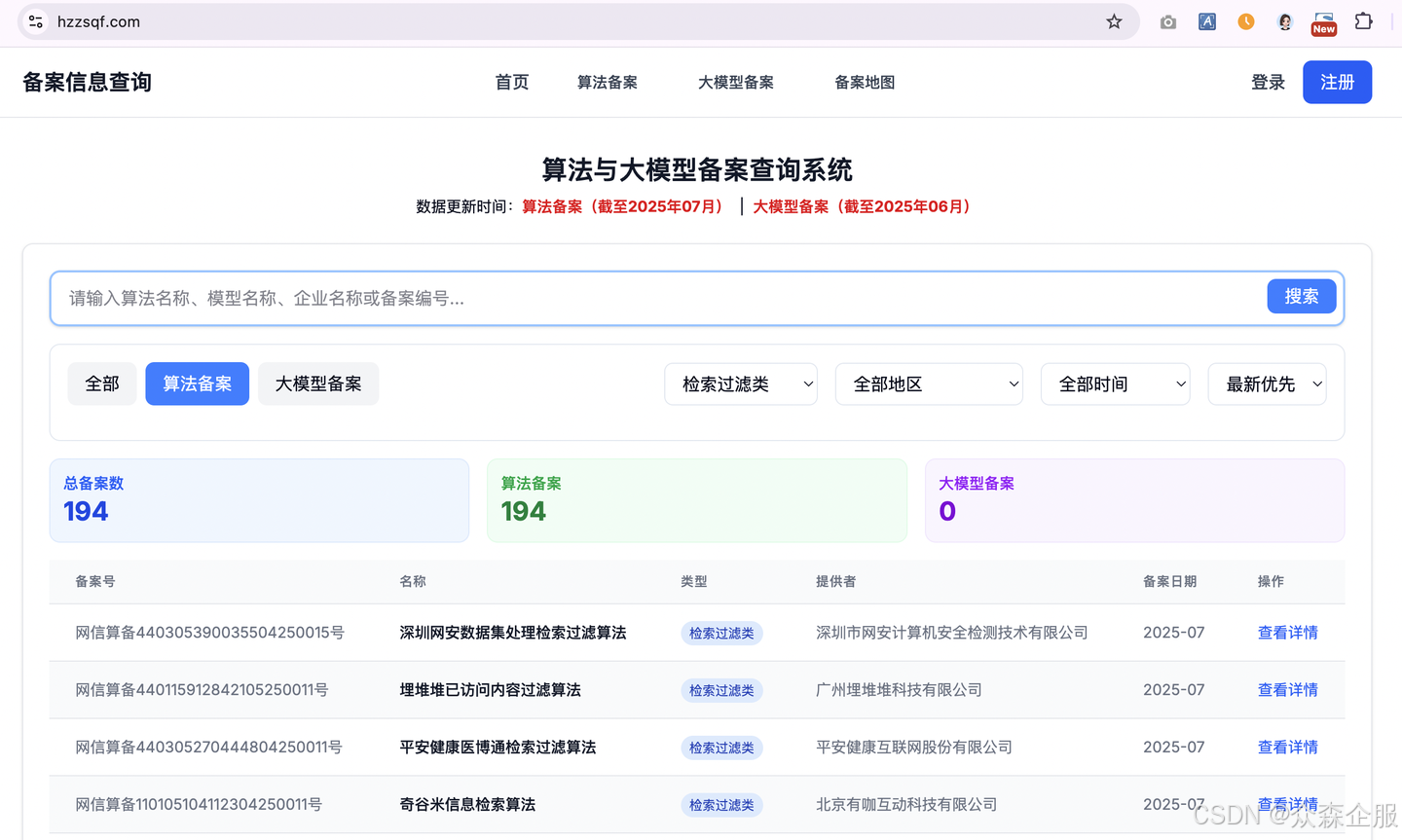
第一步:理解检索过滤类算法的核心概念
在开始备案前,我们首先需要明确您的产品或服务是否属于“检索过滤类”算法备案的范畴。
什么是“检索过滤类算法”?
根据相关规定,“检索过滤类算法”包括检索算法和过滤算法。
- 检索算法:是指按照输入条件或检索需求匹配相应网络信息内容的算法。
- 过滤算法:是指按照给定条件识别并筛选相应网络信息内容的算法。
检索过滤类算法核心特征:
- 信息查找与匹配:检索部分侧重于根据用户输入的关键词或条件,从海量信息中找出匹配项。
- 信息筛选与排除:过滤部分侧重于根据预设规则或用户自定义条件,对信息进行筛选、排除或分类。
- 提升信息获取效率:旨在帮助用户快速、精准地定位或排除信息。
检索过滤类算法典型应用场景:
这类算法广泛应用于各种需要用户主动查找和筛选信息的平台:
- 搜索引擎:根据关键词返回相关网页、图片、视频等。
- 电商平台:商品搜索、按价格/品牌/销量/评价等筛选商品。
- 新闻/内容平台:站内搜索、关键词订阅、内容屏蔽(如屏蔽某些作者、话题)。
- 社交媒体:搜索用户、群组,或过滤掉特定类型的信息。
- 应用商店:搜索应用、按类别筛选。
第二步:备案流程概述与系统填报详解
检索过滤类算法备案的整体流程与其他算法备案类似,通常包括主体备案、算法部分备案和产品备案部分三个阶段。
办理流程:
- 主体备案:提交企业基本信息,审核周期约5-7个工作日。
- 算法部分备案:提交算法详细信息,审核周期约10-20个工作日。
- 产品及功能信息备案:与算法部分同步进行,提交算法对应的产品信息(如APP、小程序、网页端等)。
- 公示与下发备案号:网信办每两个月左右会公示一批备案通过的名单,并下发备案号。
接下来,我们结合备案系统中的关键填写模块,手把手教您如何操作。
2.1 填写算法基础属性信息
这是备案的第一步,您需要对算法类型进行选择和概括性描述。
- 算法类型:从下拉菜单中选择“检索过滤类”。
- 所属算法子类型:根据您的具体功能,选择“信息检索”或“内容过滤”。
- 算法名称:填写您的算法具体名称,例如“众森企服信息检索算法”。
- 上线时间:选择您的算法投入实际使用的时间。
- 版本号:填写算法当前的版本号。
- 应用领域:填写您的算法主要应用的行业领域,如“搜索引擎”、“电子商务”、“新闻媒体”等。
- 安全自评估报告:下载系统提供的模板,按照要求填写并上传。这份报告是备案的核心材料之一,需要详细说明算法在安全性、合规性方面的自我评估结果。
- 拟公示内容:上传您在产品中向用户公示的算法规则文本。这体现了算法的透明度。
2.2 填写算法详细属性信息
此部分是对算法具体运行机制的深入描述。
- 算法简介:用200字以内简洁明了地对算法进行描述,具体描述内容包括算法使用了哪些数据、算法作用的对象、算法的目的意图(或优化目标)、算法结果的展现形式、算法应用的主要互联网产品。
- 使用场景:从系统提供的选项中选择或填写您的算法应用的具体场景,例如:网站站内搜索、电商商品筛选、新闻资讯类搜索等。
- 算法数据:
- 输入数据类型:选择或填写算法主要接受的用户输入数据类型,例如:关键词、筛选条件、用户历史搜索记录等。
- 输入数据模态:填写这些输入数据的具体模态。
- 算法数据模态:填写经算法处理后的数据的具体模态。
- 检索信息来源:填写您的检索内容来自哪里,例如:自有数据库、第三方内容聚合平台、用户生成内容等。
- 是否存储用户检索历史数据:根据实际情况选择“是”或“否”。如果存储,需要说明其目的和隐私保护措施。
2.3 算法模型填写
此模块需要您对算法模型的构建、数据来源和运行逻辑进行描述。
- 训练数据来源:
- 开源数据集 & 来源:如果您使用了开源数据集,需填写数据集名称和具体来源。
- 自建数据集 & 来源:如果您有自己的数据集,需填写数据集名称和具体来源。
- 合作数据集 & 来源:如果您与第三方合作获取数据,需填写数据集名称和具体来源。
- 训练数据是否包括境外数据:根据实际情况选择“是”或“否”。如果涉及境外数据,需特别注意跨境数据传输的合规要求。
- 训练数据产生方式:选择训练数据的产生方式,如收集、标注、生成等。
- 是否提供个性化检索:选择“是”或“否”。如果您的检索结果会根据用户个性化特征(如历史行为、偏好)进行调整,则选择“是”。
- 是否对检索内容(物料)进行建模(内容标签):通常选择“是”,因为算法需要对内容进行标签化才能进行有效检索和过滤。
- 结果排序依据:填写算法进行排序或推荐的依据维度,例如:相关性、时效性、权威性、热度、用户互动量等。
- 索引更新频率:选择您的检索索引更新的频率,以确保搜索结果的实时性和准确性。
2.4 算法策略填写
此部分关注算法的运行策略和风险控制。
- 算法中间结果与检索历史数据是否与第三方共享:根据实际情况选择“是”或“否”。如果共享,需确保符合数据共享和隐私保护的法律法规。
- 检索结果干预机制:选择或填写您如何对检索结果进行干预。例如:
- 是否有人工审核团队对搜索结果进行审查和调整。
- 是否有机制应对恶意刷榜、关键词劫持等行为。
- 网页快照更新频率:选择您的算法快照的更新频率,如实时、每日、每周、每月等。
- 是否嵌入第三方检索:选择“是”或“否”。如果您的产品使用了第三方的检索服务,需说明其合规性。
2.5 算法风险与防范机制
这是备案中最为关键且容易被驳回的部分,体现了您对算法合规和风险防范的重视。系统界面通常会要求您选择或填写具体的保障机制。
- 内容生态保障机制:选择或填写您如何保障内容生态健康。这包括对检索和过滤结果的合法合规性审查,防止出现违法违规信息。
- 用户权益保障机制:选择或填写您如何保障用户权益。这包括:
- 透明可解释性:向用户说明检索和过滤的依据。
- 用户控制权:提供用户自定义过滤规则的选项,或提供便捷的拒绝、反馈渠道。
- 避免歧视偏见:确保检索过滤算法不会因用户特征或内容来源而产生歧视。
- 检索优化行为:选择或填写您的检索优化行为。这可能包括关键词优化、索引优化等,但需避免不正当竞争。
- 是否对所有检索优化行为均具有过滤机制:选择“是”或“否”。这是为了确保所有优化行为都在合规框架内,防止通过非正常手段干扰检索结果。
2.6 产品及功能信息备案(第三步)
完成前两步算法信息的填写后,备案系统会引导您进入“产品及功能信息”备案环节。这一步需要您录入依托该检索过滤算法运行的产品信息。
- 产品类型:选择您的产品形式,如APP、小程序、网页端等。
- 产品名称:填写产品的具体名称,如“XX搜索引擎APP”、“XX电商小程序”。
- 访问地址:算法产品的服务地址。
- 状态及产品的服务对象:算法产品的运行状态及主要服务对象群体等。
总结与建议
检索过滤类算法备案是企业在数字时代合规运营的重要保障。它不仅是遵守法律法规的要求,更是维护平台信息秩序、提升用户体验、赢得用户信任的关键。
在提交备案前,强烈建议您对照本文及备案系统要求,逐项核查信息完整性和准确性。对于涉及复杂技术细节的部分,可与您的技术团队密切沟通,确保描述真实、准确。


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











