多元时间序列预测对于各种应用都至关重要,例如金融投资、能源管理、天气预报和交通优化。然而,准确的预测具有挑战性,主要有两个因素。首先,现实世界的时间序列通常表现出由随时间变化的分布变化引起的异质时间模式。其次,渠道之间的相关性复杂且相互交织,很难准确灵活地模拟渠道之间的相互作用。在本研究中,我们通过提出一个名为 DUET 的通用框架来解决这些挑战,该框架在时间和通道维度上引入了双重聚类,以增强多元时间序列预测。首先,我们设计了一个时间聚类模块 (TCM),将时间序列聚类为细粒度分布,以处理异构时间模式。对于不同的分布簇,我们设计了各种模式提取器来捕获它们的内在时间模式,从而对异质性进行建模。其次,我们引入了一种新颖的通道软聚类策略,并设计了一个通道聚类模块 (CCM),该模块通过度量学习捕获频域中通道之间的关系,并应用稀疏化来减轻噪声通道的不利影响。最后,DUET 结合了 TCM 和 CCM,将时间和通道维度融为一体。对来自 10 个应用领域的 25 个真实世界数据集进行了广泛的实验,证明了 DUET 的最先进的性能。
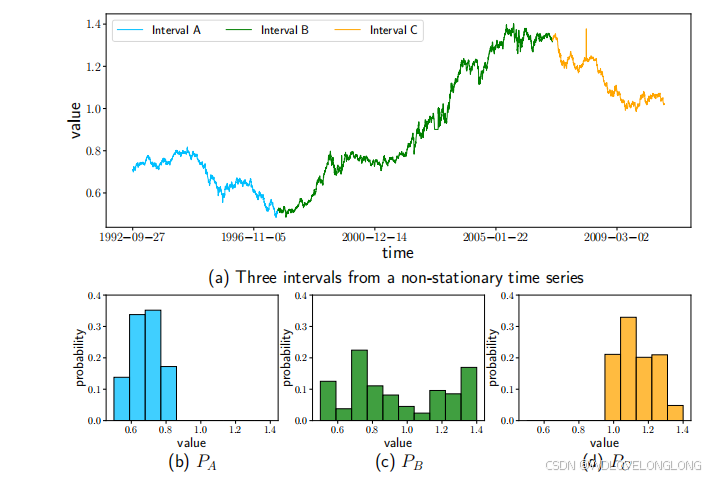
Figure 1: A Non-stationary time series with three intervals A,
B, and C, exhibiting varying value distributions (
𝑃
𝐴
≠
𝑃
𝐵
≠
𝑃
𝐶
) and temporal patterns.
图 1:具有三个间隔 A、B 和 C 的非平稳时间序列,表现出不同的值分布(𝑃𝐴 ≠ 𝑃𝐵 ≠ 𝑃𝐶)和时间模式。
1 Introduction
Multivariate time series is a type of time series that organizes timestamps chronologically and involves multiple channels (a.k.a., variables) at each timestamp [21
,
22
,
28
,
58
,
61
,
63
]. In recent years, multivariate time series analysis has seen remarkable progress, with key tasks such as anomaly detection [24
,
42
,
44
,
62
,
72
,
78
], classification [6
,
80
], and imputation [
17
,
64
–
66
], among others [
23
, 27,
79
,
81
], gaining attention. Among these, multivariate time series forecasting (MTSF) [9
,
26
,
69
,
83
,
84
,
88
,
90
] stands out as a critical and widely studied task. It has been extensively applied in diverse domains, including economics [29
,
56
], traffic [
11
,
31
,
73
,
74
,
76
,
77
], energy [19
,
59
,
67
], and AIOps [
5
,
8
,
36
,
39
,
52
], highlighting its importance and impact. Building an MTSF method typically involves modeling correlations on the temporal and channel dimensions. However, real-world time series often exhibit heterogeneous temporal patterns caused by the shifting of distribution over time, a phenomenon called
Temporal Distribution Shift
(
TDS
) [
4
,
15
]. Additionally, the correlation among multiple channels is complex and intertwined [55
]. Therefore, developing a method that can effectively extract heterogeneous temporal patterns and channel dependencies is essential yet challenging. Specifically, achieving these goals is hindered by two major challenges.
1 简介
多元时间序列是一种按时间顺序组织时间戳并在每个时间戳涉及多个通道(又称变量)的时间序列 [21、22、28、58、61、63]。近年来,多元时间序列分析取得了显著进展,异常检测 [24、42、44、62、72、78]、分类 [6、80] 和归纳 [17、64–66] 等关键任务 [23、27、79、81] 引起了人们的关注。其中,多元时间序列预测 (MTSF) [9、26、69、83、84、88、90] 是一项关键且得到广泛研究的任务。它已广泛应用于经济学[29, 56]、交通[11, 31, 73, 74, 76, 77]、能源[19, 59, 67]和AIOps [5, 8, 36, 39, 52]等不同领域,其重要性和影响力可见一斑。构建MTSF方法通常涉及在时间和通道维度上对相关性进行建模。然而,现实世界的时间序列往往表现出由分布随时间的变化引起的异构时间模式,这种现象称为时间分布偏移(TDS)[4, 15]。此外,多个通道之间的相关性复杂且相互交织[55]。因此,开发一种能够有效提取异构时间模式和通道依赖性的方法至关重要,但同时也极具挑战性。具体而言,实现这些目标面临两大挑战。
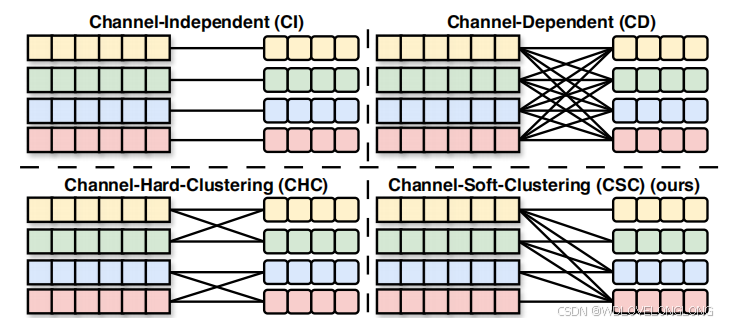
Figure 2: Channel strategies. Different colors represent dif
ferent channels, with squares representing features before
processing with various channel strategies, and squares with
rounded corners representing features after processing.
图 2:通道策略。不同颜色代表不同的通道,方块代表使用各种通道策略处理之前的特征,圆角方块代表处理之后的特征。
First, heterogeneous temporal patterns caused by TDS are
difficult to model.
In real applications, time series that describe unstable systems are easily influenced by external factors [50, 82]. Such non-stationarity of time series implies the data distribution changes over time, a phenomenon called TDS [4
,
15
,
16
]. TDS causes time series to have different temporal patterns, formally known as heterogeneity of temporal patterns [15
,
16
,
47
,
48
]. For example, Figure 1(a) illustrates a time series in economics, which shows the changes with the international circumstances. We can observe that the three intervals A, B, and C follow different temporal distributions, as evidenced by the value histograms shown in Figures 1(b), 1(c), and 1(d). This shift in distribution also comes with varying temporal patterns. As shown in Figure 1(a), the blue interval A shows a descending trend, the green interval B shows an increasing trend, and the yellow interval C shows a steeper descending trend. It is crucial to incorporate these patterns considering their common presence in time series. However, recent studies [37
,
45
,
68
,
75
]
primarily address heterogeneous temporal patterns in an implicit manner, which ultimately undermines prediction accuracy.
Second, complex channel interrelations are difficult to
model flexibly.
For an MTSF task, it is crucial to model the correlations among different channels, as the predictive accuracy for a particular channel can often be enhanced by leveraging information from other related channels. For example, in weather forecasting,
temperature predictions can be improved by incorporating data on humidity, wind speed, and pressure, as these factors are interrelated and provide a more comprehensive view of weather conditions. Researchers have explored various strategies to manage multiple channels, including 1) treating each channel independently [45
, 51] (
Channel-Independent
,
CI
), 2) assuming each channel correlates with all other channels [87
] (
Channel-Dependent
,
CD
), and 3) grouping channels into clusters [43
] (
Channel-Hard-Clustering
,
CHC
). Figure 2 illustrates these three strategies. CI imposes the constraint of using the same model across different channels. While it offers robustness [51
], it overlooks potential interactions among channels and can be limited in generalizability and capacity for unseen channels [20
,
55
]. CD, on the other hand, considers all channels simultaneously and generates joint representations for decoding [87], but may be susceptible to noise from irrelevant channels, reducing the model’s robustness. CHC partitions multivariate time series into disjoint clusters through hard clustering, applying CD modeling
methods within each cluster and CI methods among clusters [
43
]. However, this approach only considers relationships within the same cluster, limiting flexibility and versatility. In conclusion, there is yet an approach to model the complex interactions among channels precisely and flexibly.
首先,TDS 造成的异质时间模式难以建模。在实际应用中,描述不稳定系统的时间序列很容易受到外部因素的影响 [50, 82]。时间序列的这种非平稳性意味着数据分布会随时间而变化,这种现象称为 TDS [4, 15, 16]。TDS 导致时间序列具有不同的时间模式,正式称为时间模式的异质性 [15, 16, 47, 48]。例如,图 1(a) 显示了经济学中的时间序列,它显示了国际形势的变化。我们可以观察到三个区间 A、B 和 C 遵循不同的时间分布,如图 1(b)、1(c) 和 1(d) 所示的值直方图所示。这种分布的变化也伴随着不同的时间模式。如图 1(a) 所示,蓝色区间 A 显示下降趋势,绿色区间 B 显示上升趋势,黄色区间 C 显示更陡峭的下降趋势。考虑到这些模式在时间序列中的普遍存在,将它们结合起来至关重要。然而,最近的研究[37、45、68、75]主要以隐式方式处理异构时间模式,这最终会损害预测准确性。其次,复杂的通道相互关系难以灵活建模。对于 MTSF 任务,对不同通道之间的相关性进行建模至关重要,因为特定通道的预测准确性通常可以通过利用其他相关通道的信息来提高。例如,在天气预报中,可以通过结合湿度、风速和压力数据来改进温度预测,因为这些因素是相互关联的,可以提供更全面的天气状况视图。研究人员已经探索了管理多通道的各种策略,包括1)独立处理每个通道[45,51](通道独立,CI),2)假设每个通道与所有其他通道相关[87](通道依赖,CD),以及3)将通道分组为聚类[43](通道硬聚类,CHC)。图2说明了这三种策略。CI施加了在不同通道上使用相同模型的约束。虽然它提供了稳健性[51],但它忽略了通道间的潜在相互作用,并且对于看不见的通道在通用性和容量方面可能受到限制[20,55]。另一方面,CD同时考虑所有通道并生成用于解码的联合表示[87],但可能容易受到来自不相关通道的噪声的影响,从而降低了模型的稳健性。CHC通过硬聚类将多元时间序列划分为不相交的聚类,在每个聚类内应用CD建模方法,在聚类之间应用CI方法[43]。但该方法仅考虑同一簇内的关系,灵活性和通用性有限。总之,目前还没有一种方法可以精确灵活地对渠道间复杂的相互作用进行建模。
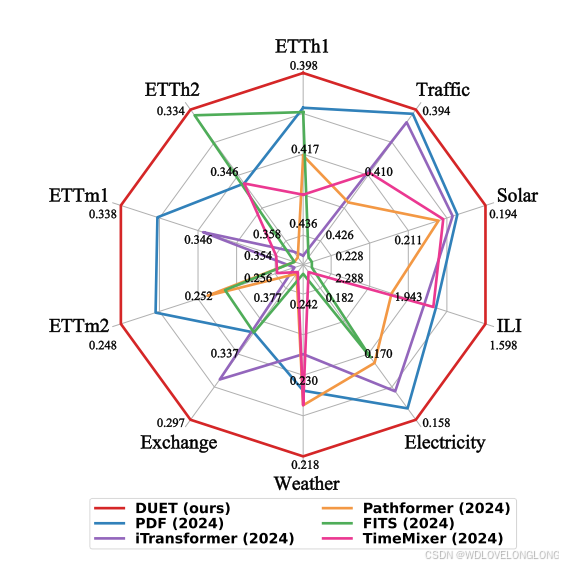
Figure 3: Performance of DUET. Results (MSE) are averaged
from all forecasting horizons. DUET outperforms strong
baselines in 10 commonly used datasets.
图 3:DUET 的性能。结果 (MSE) 是所有预测范围的平均值。DUET 在 10 个常用数据集中的表现优于强基线。
In this study, we address the above two challenges by proposing a general framework, DUET
, which introduces
DU
al clustering on
the temporal and channel dimensions to Enhance multivariate Time
series forecasting
. First, to model heterogeneous temporal patterns caused by TDS, we design a Temporal Clustering Module
(TCM). This module clusters time series into fine-grained distributions, allowing us to use various pattern extractors to capture their intrinsic
temporal patterns, thereby modeling the heterogeneity of temporal patterns. This method effectively handles both stationary and nonstationary data, demonstrating strong generality. Second, to flexibly model relationships among channels, we propose a Channel Clus
tering Module
(CCM). Using a channel-soft-clustering strategy, this module captures relationships among channels in the frequency domain through metric learning and applies sparsification. This
approach enables each channel to focus on those beneficial for downstream prediction tasks, while mitigating the impact of noisy or irrelevant channels, thereby achieving effective channel soft clustering. Finally, the Fusion Module
(FM), based on a masked attention mechanism, efficiently combines the temporal features extracted by the TCM with the channel mask matrix generated by the CCM. Experimental results show that the proposed DUET achieves state-of-the-art performance on real-world forecasting datasets—see Figure 3.
在本研究中,我们通过提出一个通用框架 DUET 来解决上述两个挑战,该框架在时间和通道维度上引入了双重聚类以增强多变量时间序列预测。首先,为了对由 TDS 引起的异构时间模式进行建模,我们设计了一个时间聚类模块 (TCM)。该模块将时间序列聚类为细粒度分布,使我们能够使用各种模式提取器来捕获其内在的时间模式,从而对时间模式的异质性进行建模。该方法有效地处理了平稳和非平稳数据,表现出很强的通用性。其次,为了灵活地对通道之间的关系进行建模,我们提出了一个通道聚类模块 (CCM)。使用通道软聚类策略,该模块通过度量学习在频域中捕获通道之间的关系并应用稀疏化。这种方法使每个通道能够专注于对下游预测任务有益的通道,同时减轻噪声或不相关通道的影响,从而实现有效的通道软聚类。最后,基于掩蔽注意力机制的融合模块 (FM) 有效地将 TCM 提取的时间特征与 CCM 生成的通道掩码矩阵相结合。实验结果表明,所提出的 DUET 在现实世界的预测数据集上实现了最佳性能 - 见图 3。
Our contributions are summarized as follows.
•
To address MTSF, we propose a general framework called DUET. It learns an accurate and adaptive forecasting model through dual clustering on both temporal and channel dimensions.
•
We design the TCM that clusters time series into fine-grained distributions. Various pattern extractors are then designed for different distribution clusters to capture their unique temporal
patterns, modeling the heterogeneity of temporal patterns.
•
We design the CCM that flexibly captures the relationships among channels in the frequency domain through metric learning and applies sparsification.
•
We conduct extensive experiments on 25 datasets. The results show that DUET outperforms state-of-the-art baselines. Additionally, all datasets and code are avaliable at https://github.com/
decisionintelligence/DUET
我们的贡献总结如下。
• 为了解决 MTSF,我们提出了一个名为 DUET 的通用框架。它通过在时间和通道维度上的双重聚类来学习准确且自适应的预测模型。
• 我们设计了 TCM,将时间序列聚类为细粒度分布。然后为不同的分布集群设计各种模式提取器以捕获其独特的时间模式,对时间模式的异质性进行建模。
• 我们设计了 CCM,它通过度量学习灵活地捕获频域中通道之间的关系并应用稀疏化。
• 我们对 25 个数据集进行了广泛的实验。结果表明,DUET 的表现优于最先进的基线。此外,所有数据集和代码均可在 https://github.com/decisionintelligence/DUET 上找到
2 Related Works
2.1 Temporal Distribution Shift in MTSF
Time series forecasting suffers from Temporal Distribution Shift (TDS), as the distribution of real-world series changes over time [1
, 13,
40
]. In recent years, various methods have been proposed to address this issue. Some works tackle TDS from a normalization
perspective
. DAIN [
53
] adaptively normalizes the series with nonlinear neural networks. RevIN [32
] utilizes instance normalization on input and output sequences by normalizing the input sequences and then denormalizing the model output sequences. Dish-TS [16
] identifies intra- and inter-space distribution shifts in time series and mitigates these issues by learning distribution coefficients. Nonstationary Transformer [46
] presents de-stationary attention that incorporates non-stationary factors in self-attention, significantly improving transformer-based models. Some works address TDS from a distribution perspective
. DDG-DA [
34
] predicts evolving data distribution in a domain adaptation fashion. AdaRNN [15
] proposes an adaptive RNN to alleviate the impact of non-stationary factors by characterizing and matching distributions. Other works address TDS from a time-varying model parameters perspec
tive
. Triformer [
10
] proposes a light-weight approach to enable variable-specific model parameters, making it possible to capture distinct temporal patterns from different variables. ST-WA [11
] use distinct sets of model parameters for different time period. Despite the effectiveness of existing methods, our work explicitly models heterogeneous temporal patterns separately under different distributions, which can further improve the performance.
2 相关作品
2.1 MTSF 中的时间分布偏移
时间序列预测受到时间分布偏移 (TDS) 的影响,因为现实世界序列的分布会随时间而变化 [1, 13, 40]。近年来,已经提出了各种方法来解决此问题。一些作品从规范化的角度解决 TDS。DAIN [53] 使用非线性神经网络自适应地对序列进行规范化。RevIN [32] 通过对输入序列进行规范化,然后对模型输出序列进行非规范化,对输入和输出序列进行实例规范化。Dish-TS [16] 识别时间序列中的空间内和空间间分布偏移,并通过学习分布系数来缓解这些问题。非平稳 Transformer [46] 提出了非平稳注意力,将非平稳因素纳入自注意力,显著改善了基于 Transformer 的模型。一些作品从分布的角度解决 TDS。DDG-DA [34] 以领域自适应的方式预测不断变化的数据分布。 AdaRNN [15] 提出了一种自适应 RNN,通过表征和匹配分布来减轻非平稳因素的影响。其他研究从随时间变化的模型参数角度解决了 TDS 问题。Triformer [10] 提出了一种轻量级方法来启用特定于变量的模型参数,从而可以从不同变量中捕获不同的时间模式。ST-WA [11] 对不同的时间段使用不同的模型参数集。尽管现有方法很有效,但我们的工作明确地在不同分布下分别对异构时间模式进行建模,这可以进一步提高性能。
2.2 Channel Strategies in MTSF
It is essential to consider the correlations among channels in MTSF. Most existing methods adopt either a Channel-Independent
(
CI
) or
Channel-Dependent
(
CD
) strategy to utilize the spectrum of information in channels. CI strategy approaches [12
,
37
,
51
,
75
] share the same weights across all channels and make forecasts independently. Conversely, CD strategy approaches [7
,
10
,
25
,
41
,
45
,
87
] consider all channels simultaneously and generates joint representations for decoding. The CI strategy is characterized by low model capacity but high robustness, whereas the CD strategy exhibits the opposite characteristics. DGCformer [43
] proposes relatively
balanced channel strategies called
Channel-Hard-Clustering
(
CHC
), trying to mitigate this polarization effect and improve predictive capabilities. Specifically, DGCformer designs a graph clustering module to assign channels with significant similarities into the same cluster, utilizing the CD strategy inside each cluster and the CI strategy across them. This approach adopts the CHC strategy, focusing solely on channel correlations within the same cluster. As a result, this method suffers from the limitations of rigidly adhering to channel-similarity rules defined by human experience. Different from the above methods, we adopt a Channel-Soft-Clustering (CSC) strategy and devise a fully adaptive sparsity module to dynamically build group for each channel, which is a more comprehensive design covering the CHC strategy.
2.2 MTSF 中的通道策略
在 MTSF 中,考虑通道之间的相关性至关重要。大多数现有方法采用通道独立 (CI) 或通道相关 (CD) 策略来利用通道中的信息频谱。 CI 策略方法 [12、37、51、75] 在所有通道上共享相同的权重并独立进行预测。相反,CD 策略方法 [7、10、25、41、45、87] 同时考虑所有通道并生成用于解码的联合表示。 CI 策略的特点是模型容量低但鲁棒性高,而 CD 策略则表现出相反的特征。 DGCformer [43] 提出了相对平衡的通道策略,称为通道硬聚类 (CHC),试图减轻这种极化效应并提高预测能力。具体而言,DGCformer 设计了一个图形聚类模块,将具有显着相似性的通道分配到同一个聚类中,利用每个聚类内的 CD 策略和它们之间的 CI 策略。该方法采用 CHC 策略,仅关注同一簇内的通道相关性。因此,该方法存在严格遵守人类经验定义的通道相似性规则的局限性。与上述方法不同,我们采用通道软聚类 (CSC) 策略,并设计了一个完全自适应的稀疏性模块来动态构建每个通道的组,这是一种涵盖 CHC 策略的更全面的设计。
3 Preliminaries
3.1 Definitions
Definition 3.1 (Time series).
A time series
𝑋
∈
R
𝑁
×
𝑇
is a timeoriented sequence of N-dimensional time points, where 𝑇
is the number of timestamps, and 𝑁
is the number of channels. If
𝑁
=
1, a time series is called univariate, and multivariate if 𝑁
>
1. For convenience, we separate dimensions with commas. Specifically, we denote 𝑋
𝑖,𝑗
∈
R
as the
𝑖
-th channel at the
𝑗
-th timestamp,
𝑋
𝑛,
:
∈
R
𝑇
as the time series of
𝑛
-th channel, where
𝑛
=
1
,
· · ·
, 𝑁
. We also introduce some definitions used in our methodology:
Definition 3.2 (Temporal Distribution Shift [
15
]).
Given a time series X ∈
R
𝑁
×
𝐿
, by sliding the window, we get a set of time series with the length of 𝑇
, denoted as
D
=
{X
𝑛,𝑖
:
𝑖
+
𝑇
|
𝑛
∈ [
1
, 𝑁
]
&
𝑖
∈ [1
, 𝐿
−
𝑇
]}
, where each
X
𝑛,𝑖
:
𝑖
+
𝑇
equals to such
𝑋
𝑛,
:
. Then, temporal distribution shift is referred to the case that D
can be clustered
into
𝐾
sets, i.e.,
D
=
Ð
𝑖 𝐾
=
1
D
𝑖
, where each
D
𝑖
denotes the set with data distribution 𝑃
D
𝑖
(
𝑥
)
, where
𝑃
D
𝑖 (𝑥
)
≠
𝑃
D
𝑗
(
𝑥
)
,
∀
𝑖
≠
𝑗
and 1 ≤
𝑖, 𝑗
≤
𝑘
.
Definition 3.3 (Frequency Metric Space).
The Frequency Metric Space is defined by the frequency space and the distance metric. The frequency space consists of functions from 𝐿
2
space represented by infinite fourier basis, of which the coordinates are calculated by Fourier Transform. And the metric is used to measure the distances among functions in the frequency space. For discrete univariate time series with length 𝑇
, we use rFFT [
3
] to represent them under
𝑇
2
fourier basis and design proper metric to measure the distances.
3 准备工作
3.1 定义
定义 3.1(时间序列)。时间序列 𝑋 ∈ R 𝑁 ×𝑇 是 N 维时间点的时间序列,其中 𝑇 是时间戳的数量,𝑁 是通道的数量。如果 𝑁 = 1,则时间序列称为单变量,如果 𝑁 > 1,则称为多变量。为方便起见,我们用逗号分隔维度。具体来说,我们将 𝑋𝑖,𝑗 ∈ R 表示为第 𝑗 个时间戳的第 𝑖 个通道,𝑋𝑛,: ∈ R 𝑇 表示为第 𝑛 个通道的时间序列,其中 𝑛 = 1, · · · , 𝑁。我们还介绍了我们方法论中使用的一些定义:定义 3.2(时间分布偏移 [15])。给定时间序列 X ∈ R 𝑁 ×𝐿 ,通过滑动窗口,我们得到一组长度为 𝑇 的时间序列,表示为 D = {X𝑛,𝑖:𝑖+𝑇 |𝑛 ∈ [1, 𝑁]&𝑖 ∈ [1, 𝐿 −𝑇 ]},其中每个 X𝑛,𝑖:𝑖+𝑇 等于这样的 𝑋𝑛,: 。然后,时间分布偏移指的是 D 可以聚类为 𝐾 集合的情况,即 D = Ð 𝑖 𝐾 =1 D𝑖 ,其中每个 D𝑖 表示具有数据分布 𝑃D𝑖 (𝑥) 的集合,其中 𝑃D𝑖 (𝑥) ≠ 𝑃D𝑗 (𝑥),∀𝑖 ≠ 𝑗 且 1 ≤ 𝑖,𝑗 ≤ 𝑘。定义 3.3(频率度量空间)。频率度量空间由频率空间和距离度量定义。频率空间由来自 𝐿 2 空间的函数组成,这些函数由无限傅里叶基表示,其坐标由傅里叶变换计算。度量用于度量频率空间中函数之间的距离。对于长度为𝑇的离散单变量时间序列,我们使用rFFT [3]在𝑇2傅里叶基下表示它们,并设计适当的度量来衡量距离。
3.2 Problem Statement
Multivariate Time Series Forecasting
aims to predict the next
𝐹 future timestamps, formulated as𝑌
=
⟨
𝑋
:
,𝑇
+
1
,
· · ·
, 𝑋
:
,𝑇
+
𝐹
⟩ ∈
R
𝑁
×
𝐹 based on the historical time series 𝑋
=
⟨
𝑋
:
,
1
,
· · ·
, 𝑋
:
,𝑇
⟩ ∈
R
𝑁
×
𝑇 with 𝑁
channels and
𝑇
timestamps.
3.2 问题陈述
多元时间序列预测旨在基于具有 𝑁 个通道和 𝑇 个时间戳的历史时间序列 𝑋 = ⟨𝑋:,𝑇 +1, · · · , 𝑋:,𝑇 +𝐹 ⟩ ∈ R 𝑁 ×𝐹,预测下一个 𝐹 个未来时间戳,公式为𝑌 = ⟨𝑋:,𝑇 +1, · · · , 𝑋:,𝑇 +𝐹 ⟩ ∈ R 𝑁 ×𝐹。
4 Methodology
4.1 Structure Overview
Figure 4 shows the architecture of DUET, which adopts a dual clustering on both temporal and channel dimensions, simultaneously mining intrinsic temporal patterns and dynamic channel correlations. Specifically, we first use the Instance Norm [32
] to unify the distribution of training and testing data. Then, the Temporal Clustering Module (TCM) utilizes a specially designed Distribution Router (Figure 5a) to capture the potential latent distributions of each time series 𝑋
𝑛,
:
∈
R
𝑇
in a channel-independent way, and then clusters time series with similar latent distributions by assigning them to the same group of Linear-based Pattern Extractors (Figure 5b). In this way, we can mitigate the issue that single structure cannot fully extract temporal features due to heterogeneity of temporal patterns, even with millions of parameters. Meanwhile, the
Channel Clustering Module (CCM) captures the correlations among channels in the frequency space in a channel soft clustering way. By leveraging an adaptive metric learning technique and applying sparsification, the CCM outputs a learned channel-mask matrix, so each channel can focus on those beneficial for downstream prediction and isolate the adverse effects of irrelevant channels in a sparse connection way. Finally, the Fusion Module (FM), based on a masked attention mechanism (Figure 5d), effectively combines the temporal features extracted by the TCM and the channel-mask matrix generated by the CCM. A linear predictor is then used to
forecast the future values at the end of our framework.
4 方法论
4.1 结构概述
图 4 显示了 DUET 的架构,它在时间和通道维度上采用双重聚类,同时挖掘内在时间模式和动态通道相关性。具体来说,我们首先使用实例范数 [32] 来统一训练和测试数据的分布。然后,时间聚类模块 (TCM) 利用专门设计的分发路由器(图 5a)以独立于通道的方式捕获每个时间序列 𝑋𝑛,: ∈ R 𝑇 的潜在潜在分布,然后通过将具有相似潜在分布的时间序列分配给同一组基于线性的模式提取器来对其进行聚类(图 5b)。通过这种方式,我们可以缓解由于时间模式的异质性,即使有数百万个参数,单一结构也无法完全提取时间特征的问题。同时,
通道聚类模块 (CCM) 以通道软聚类的方式捕获频率空间中通道之间的相关性。通过利用自适应度量学习技术并应用稀疏化,CCM 输出学习到的通道掩码矩阵,因此每个通道都可以专注于对下游预测有益的通道,并以稀疏连接的方式隔离不相关通道的不利影响。最后,基于掩蔽注意力机制的融合模块 (FM)(图 5d)有效地结合了 TCM 提取的时间特征和 CCM 生成的通道掩码矩阵。然后使用线性预测器来预测我们框架末端的未来值。
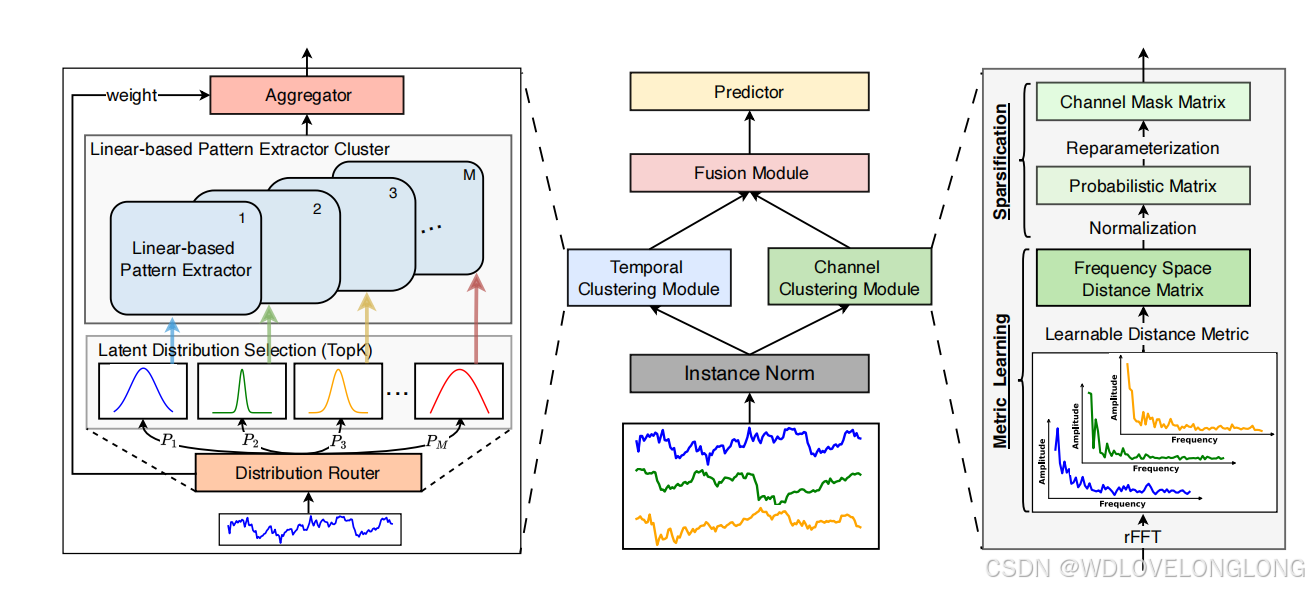
Figure 4: The architecture of DUET. Temporal Clustering Module clusters time series into fine-grained distribution. For different
distribution clusters, various pattern extractors are designed to capture their intrinsic temporal patterns. Channel Clustering
Module flexibly captures the relationships among channels in the frequency domain space through Metric Learning and applies
Sparsification. Fusion Module combines the temporal features and the channel mask matrix.
图 4:DUET 的架构。时间聚类模块将时间序列聚类为细粒度分布。针对不同的分布聚类,设计了各种模式提取器来捕获其内在的时间模式。通道聚类模块通过度量学习灵活地捕获频域空间中通道之间的关系并应用稀疏化。融合模块将时间特征与通道掩码矩阵相结合。
According to the above-mentioned description, the process of
DUET can be formulated as follows:
根据上述描述,DUET 的流程可以表述如下:
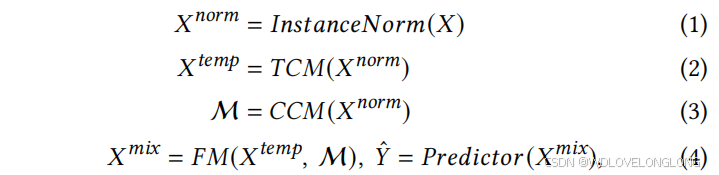
where
𝑋
temp
, 𝑋
mix
∈
R
𝑁
×
𝑑
,
M ∈
R
𝑁
×
𝑁
. Steps 2 and 3 can be computed simultaneously for higher efficiency. Below, we will introduce the details of each module in our framework.
其中 𝑋 temp, 𝑋mix ∈ R 𝑁 ×𝑁 ,M ∈ R 𝑁 ×𝑁 。步骤 2 和 3 可以同时计算以提高效率。下面,我们将介绍我们框架中每个模块的细节。
4.2 Temporal Clustering Module (TCM)
To model heterogeneous temporal patterns caused by TDS, we design a Linear-based Pattern Extractor Cluster, where each Linearbased Pattern Extractor extracts temporal features for time series that has the same latent distribution. We adopt a linear model as the basic structure because it has been proven to efficiently extract temporal information [37, 38, 68, 75, 86], which also helps to keep the cluster lightweight. Moreover, we design a simple yet effective
Distribution Router—see Figure 5a, which can extract the potential latent distributions of the current time series and determine the corresponding Linear-based Pattern Extractor. Both the routing and extracting processes are conducted in a channel-independent way, focusing on clustering univariate time series 𝑋
𝑛,
:
∈
R
𝑇
based on their distributions and fully extracting their temporal patterns.
Distribution Router:
Inspired by VAE [
33
], we first design two fully connected layer-based encoders to adaptively capture 𝑀
candidate latent distributions for each time series 𝑋
𝑛,
:
∈
R
𝑇
(see Figure 5a), where 𝑀
denotes the size of the Linear-based Pattern Extractor Cluster. Empirically, we assume each time series follows a latent normal distribution and the process can be formulated as follows.
4.2 时间聚类模块 (TCM) 为了对 TDS 引起的异构时间模式进行建模,我们设计了一个基于线性的模式提取器集群,其中每个基于线性的模式提取器提取具有相同潜在分布的时间序列的时间特征。我们采用线性模型作为基本结构,因为它已被证明可以有效地提取时间信息 [37, 38, 68, 75, 86],这也有助于保持集群轻量级。此外,我们设计了一个简单而有效的分发路由器 - 见图 5a,它可以提取当前时间序列的潜在潜在分布并确定相应的基于线性的模式提取器。路由和提取过程均以独立于通道的方式进行,重点是根据单变量时间序列 𝑋𝑛,: ∈ R 𝑇 的分布对其进行聚类并充分提取其时间模式。分发路由器:受 VAE [33] 的启发,我们首先设计两个完全连接的基于层的编码器,以自适应地捕获每个时间序列 𝑋𝑛 的 𝑀 个候选潜在分布:∈R𝑇(见图 5a),其中 𝑀 表示基于线性的模式提取器群集的大小。根据经验,我们假设每个时间序列都遵循潜在正态分布,并且该过程可以表述如下。
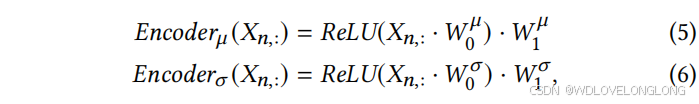
where
𝑊
𝜇 0
,𝑊
0
𝜎
∈
R
𝑇
×
𝑑
0
,
𝑊
1
𝜇
,𝑊
1
𝜎
∈
R
𝑑
0
×
𝑀
. Then, we utilize the Noisy Gating technique [57
] to choose
𝑘
most possible distributions which 𝑋
𝑛,
:
potentially belongs to and calculate the corresponding weights. We can observe that the reparameterization trick used
to measure normal distributions shares similarities with the noise addition technique in Noisy Gating, so we elegantly combine them in a unified form:
其中 𝑊 𝜇 0 ,𝑊0 𝜎 ∈ R 𝑇 ×𝑑0 , 𝑊1 𝜇 ,𝑊1 𝜎 ∈ R 𝑑0×𝑀 。然后,我们利用噪声门控技术 [57] 选择 𝑋𝑛,: 可能属于的 𝑘 个最可能分布并计算相应的权重。我们可以观察到,用于测量正态分布的重新参数化技巧与噪声门控中的噪声添加技术有相似之处,因此我们将它们优雅地组合成统一的形式:
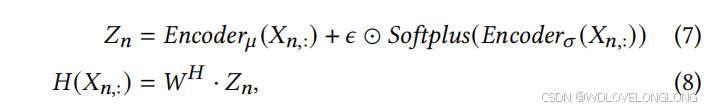
where
𝐻
(
𝑋
𝑛,
:
)
, 𝜖
∈
R
𝑀
, 𝜖
𝑖
∼ N (
0
,
1
)
,
𝑊
𝐻
∈
R
𝑀
×
𝑀
. The introduction of 𝜖
not only facilitates resampling from a normal distribution but also stabilizes the training process of Noisy Gating. The activation function Softplus
helps keep the variance to be positive.
𝐻
(
𝑋
𝑛,
:
) denotes the projected weights of distributions. We demonstrate the
其中 𝐻(𝑋𝑛,:),𝜖 ∈ R 𝑀,𝜖𝑖 ∼ N (0, 1),𝑊 𝐻 ∈ R 𝑀×𝑀。𝜖 的引入不仅有助于从正态分布中重新采样,还可以稳定 Noisy Gating 的训练过程。激活函数 Softplus 有助于保持方差为正。𝐻(𝑋𝑛,:) 表示分布的投影权重。我们展示了
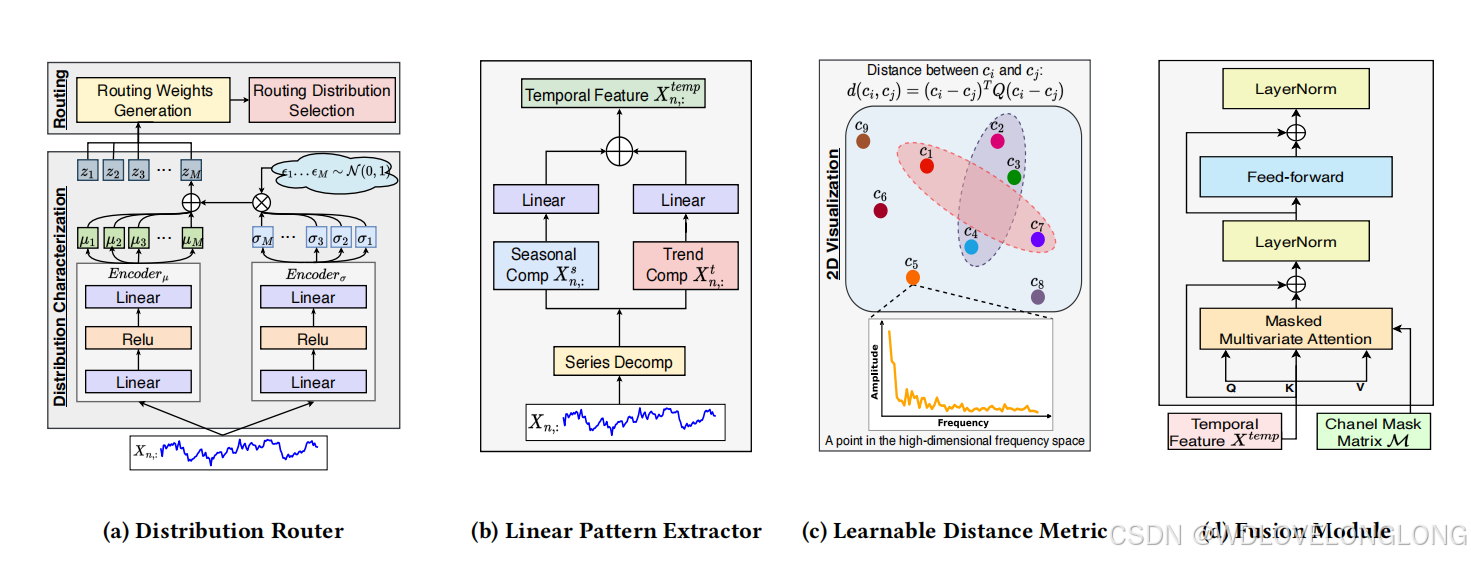
Figure 5: (a) The structure of the Distribution Router, which consists of Distribution Characterization and Routing. (b) The
structure of the Linear-based Pattern Extractor, which decomposes the series into seasonal and trend parts, separately extracts
temporal features with linear models and reads them. (c) The Learnable Distance Metric is to capture the relationships among
channels. (d) The Fusion Module is to combine the temporal features and the channel mask matrix.
图 5:(a) 分布路由器的结构,由分布特性和路由组成。(b) 基于线性的模式提取器的结构,它将序列分解为季节和趋势部分,分别用线性模型提取时间特征并读取它们。(c) 可学习距离度量用于捕获通道之间的关系。(d) 融合模块用于结合时间特征和通道掩码矩阵。
computational equivalence to the original Noisy Gating [
57
] in Appendix A.2. Subsequently, we select 𝑘
(
𝑘
≤
𝑀
) most possible latent distributions and calculate the weights:
与附录 A.2 中的原始噪声门控 [57] 具有计算等价性。随后,我们选择 𝑘 (𝑘 ≤ 𝑀) 个最可能的潜在分布并计算权重:
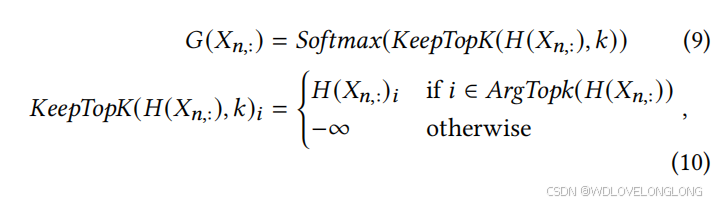
where
𝐺
(
𝑋
𝑛,
:
) ∈
R
𝑘
denotes the probabilities of each candidate distributions. From the perspective of clustering, univariate time series 𝑋
𝑛,
:
∈
R
𝑇
, 𝑛
=
1
,
· · ·
, 𝑁
belonging to the same
𝑘
most possible latent distributions tend to be processed by the same group of
𝑘
Linear-based Pattern Extractors.
其中 𝐺(𝑋𝑛,:) ∈ R 𝑘 表示每个候选分布的概率。从聚类的角度来看,属于同一 𝑘 最可能潜在分布的单变量时间序列 𝑋𝑛,: ∈ R 𝑇 , 𝑛 = 1, · · · , 𝑁 倾向于由同一组基于 𝑘 线性的模式提取器进行处理。
where
𝐺
(
𝑋
𝑛,
:
) ∈
R
𝑘
denotes the probabilities of each candidate distributions. From the perspective of clustering, univariate time 𝑋
𝑛,
:
∈
R
𝑇
, 𝑛
=
1
,
· · ·
, 𝑁
belonging to the same
𝑘
most possible latent distributions tend to be processed by the same group of
𝑘
Linear-based Pattern Extractors.
Linear-based Pattern Extractor:
The above-mentioned distribution router determines the latent distributions. Then, 𝑋
𝑛,
:
is passed to corresponding 𝑘
selected Linear-based Pattern Extractors for temporal feature extraction. For the 𝑖
-th Linear-based Pattern Extractor—see Figure 5b, we first use the moving average technique
to decompose
𝑋
𝑛,
:
into seasonal and trend parts [
71
,
86
], then separately extract features and finally fuse them to better capture the patterns of time series from the same distribution:
其中 𝐺(𝑋𝑛,:) ∈ R 𝑘 表示每个候选分布的概率。从聚类的角度来看,属于同一 𝑘 最可能潜在分布的单变量时间 𝑋𝑛,: ∈ R 𝑇 ,𝑛 = 1,· · · ,𝑁 倾向于由同一组𝑘 基于线性的模式提取器处理。基于线性的模式提取器:上述分布路由器确定潜在分布。然后,𝑋𝑛,: 被传递给相应的 𝑘 选定的基于线性的模式提取器进行时间特征提取。对于第 𝑖 个基于线性的模式提取器(见图 5b),我们首先使用移动平均技术将 𝑋𝑛 分解为季节性和趋势部分 [71, 86],然后分别提取特征并最终融合它们,以更好地捕捉来自同一分布的时间序列的模式:
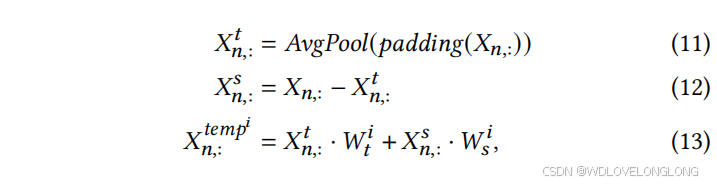
where
𝑋
𝑛, 𝑡
:
, 𝑋
𝑛, 𝑠
:
∈
R
𝑇
are the decomposed trend and seasonal parts,
𝑊
𝑖
𝑡
,𝑊
𝑠 𝑖
∈
R
𝑇
×
𝑑
are the learnable parameters in linear transformations. 𝑋
temp
𝑖
𝑛,: ∈ R
𝑑
is the temporal feature generated by the
𝑖
-th extractor, where 𝑑
is the hidden dimension.
其中 𝑋𝑛, 𝑡 : , 𝑋𝑛, 𝑠 : ∈ R 𝑇 是分解后的趋势和季节性部分,𝑊 𝑖 𝑡 ,𝑊𝑠 𝑖 ∈ R 𝑇 ×𝑑 是线性变换中可学习的参数。𝑋 temp𝑖 𝑛,: ∈ R 𝑑 是第 𝑖 个提取器生成的时间特征,其中 𝑑 是隐藏维度。
Aggregator: After the selected 𝑘 Linear-based Pattern Extractors output the corresponding features, the Aggregator gathers the temporal features based on the previously calculated weighted gates:
聚合器:在选定的基于 𝑘 线性的模式提取器输出相应的特征后,聚合器根据之前计算的加权门收集时间特征:
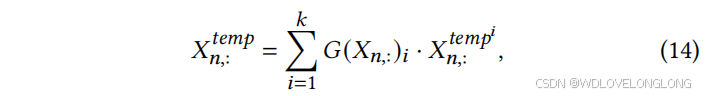
where
𝐺
(
𝑋
𝑛,
:
)
𝑖
represents the weights of the
𝑖
-th Linear-based Pattern Extractor, and 𝑋
𝑛,
temp
:
∈
R
𝑑
represents the temporal patterns of𝑋
𝑛,
:
extracted by the Linear-based Pattern Extractor Cluster. After obtaining temporal features of each 𝑋
𝑛,
:
(
𝑛
=
1
,
· · ·
, 𝑁
) in a channelindependent way, they are finally gathered into 𝑋
temp
∈
R
𝑁
×
𝑑
.
其中 𝐺(𝑋𝑛,:)𝑖 表示第 𝑖 个线性模式提取器的权重,𝑋𝑛, temp : ∈ R 𝑑 表示线性模式提取器聚类提取出的𝑋𝑛,: 的时间模式。在以通道无关的方式获得每个 𝑋𝑛,: (𝑛 = 1, · · · , 𝑁) 的时间特征后,最终将它们聚集到 𝑋 temp ∈ R 𝑁 ×𝑑 中。
4.3 Channel Clustering Module (CCM)
To mitigate the adverse effects caused by improper consideration of cross-channel relationships during prediction, we devise an efficient metric learning method to softly cluster channels in the frequency space, and generate a corresponding learned channel-mask matrix to achieve sparse connections.
4.3 通道聚类模块(CCM)
为了减轻预测过程中对跨通道关系考虑不当造成的不利影响,我们设计了一种有效的度量学习方法,在频率空间中对通道进行软聚类,并生成相应的学习通道掩码矩阵以实现稀疏连接。
Learnable Distance Metric
. To fully utilize the cross-channel enhancement in prediction, we manage to leverage more useful information by modeling the correlations among channels in the
perspective of frequency metric space. Theoretically, the “frequency space” describes functions under the fourier basis, and their coordinates come from Fourier Transform by computing integrals in 𝐿
2 space (see Appendix A.3). Specifically, given a discrete time series at the 𝑛
-th channel,
𝑋
𝑛,
:
∈
R
𝑇
, we first use real Fast Fourier Transform (rFFT [3
]) to project it into a finite
𝑇
2
-dimension frequency space with the same 𝑇
2
Fourier basis (in complex form). Then, we need to find a proper distance metric that precisely evaluates channel relations in the frequency space.
可学习的距离度量。为了充分利用跨通道增强的预测能力,我们设法通过从频率度量空间的角度对通道之间的相关性进行建模来利用更多有用的信息。理论上,“频率空间”描述傅里叶基下的函数,它们的坐标来自通过计算𝐿2空间中的积分进行的傅里叶变换(参见附录A.3)。具体而言,给定第𝑛个通道的离散时间序列𝑋𝑛,:∈R𝑇,我们首先使用实数快速傅里叶变换(rFFT [3])将其投影到具有相同𝑇2傅里叶基(复数形式)的有限𝑇2维频率空间中。然后,我们需要找到一个合适的距离度量来精确评估频率空间中的通道关系。
We propose such a distance metric that precisely evaluates channel relations in the frequency space and make each channel obtain maximum neighbour gain in the prediction task. Specifically, we take the norm (or amplitude) to obtain 𝑋𝑛,
chan
:
∈
R
𝑇 2 and adopt a
learnable Mahalanobis distance metric [18] to adaptively discover the interrelationships among channels:
我们提出了这样一种距离度量,它可以精确评估频率空间中的通道关系,并使每个通道在预测任务中获得最大的邻域增益。具体来说,我们取范数(或幅度)得到𝑋𝑛,chan:∈R𝑇2,并采用可学习的马哈拉诺比斯距离度量[18]来自适应地发现通道之间的相互关系:
where
𝑄
∈
R
𝑇 2 ×
𝑇
2 is a learnable semi-positive definite matrix. It can be practically constructed by 𝑄
=
𝐴
𝑇
·
𝐴
, where
𝐴
is also a learnable matrix. This process introduces a more general and lightweight method from the perspective of metric space and adaptively explores a distance metric to measure the channel correlations for better prediction accuracy.
其中 𝑄 ∈ R 𝑇 2 × 𝑇 2 是一个可学习的半正定矩阵。它实际上可以通过 𝑄 = 𝐴 𝑇 · 𝐴 构造,其中 𝐴 也是一个可学习的矩阵。此过程从度量空间的角度引入了一种更通用、更轻量的方法,并自适应地探索距离度量来测量通道相关性,以获得更好的预测精度。
Normalization.
With the learnable channel distance metric, we first compute the relationship matrix of channels and normalize it to the range of [0, 1]:
规范化。利用可学习的通道距离度量,我们首先计算通道的关系矩阵,并将其规范化到 [0, 1] 范围内:
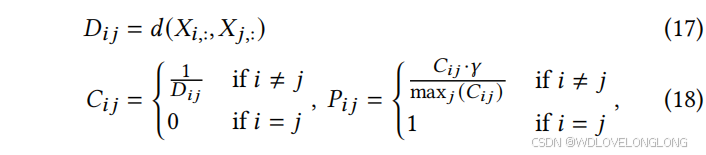
where
𝐷,𝐶, 𝑃
∈
R
𝑁
×
𝑁
are distance, relationship, and probability matrices, 𝛾
∈ (
0
,
1
)
is a discount factor to avoid the absolute connection. Above processes probabilize the relationships among channels, where 𝑃
𝑖𝑗
represents the probability that channel
𝑗
is useful for channel 𝑖
in the prediction task.
其中 𝐷,𝐶,𝑃 ∈ R 𝑁 ×𝑁 分别为距离、关系和概率矩阵,𝛾 ∈ (0, 1) 为避免绝对联系而设置的折扣因子。上述过程将通道间关系概率化,其中 𝑃𝑖𝑗 表示通道 𝑗 在预测任务中对通道 𝑖 有用的概率。
Reparameterization.
Since our goal is to filter out the adverse effects of irrelevant channels and retain the beneficial effects of relevant channels, we further perform Bernoulli resampling on the probability matrix to obtain a binary channel mask matrix M ∈ R
𝑁
×
𝑁
, where
M
𝑖𝑗
≈
Bernoulli
(
𝑃
𝑖𝑗
)
. Higher probability
𝑃
𝑖𝑗 results in M
𝑖𝑗
closer to 1, indicating a relationship between channel
𝑖
and channel
𝑗
. Since
𝑃
𝑖𝑗
contains learnable parameters, we use the Gumbel Softmax reparameterization trick [30
] during Bernoulli resampling to ensure the propagation of gradients
重新参数化。由于我们的目标是滤除不相关通道的不利影响并保留相关通道的有益影响,我们进一步对概率矩阵进行伯努利重采样,以获得二元通道掩码矩阵 M ∈ R 𝑁 ×𝑁 ,其中 M𝑖𝑗 ≈ Bernoulli(𝑃𝑖𝑗)。更高的概率 𝑃𝑖𝑗 导致 M𝑖𝑗 更接近 1,表明通道 𝑖 和通道 𝑗 之间存在关系。由于 𝑃𝑖𝑗 包含可学习的参数,我们在伯努利重采样期间使用 Gumbel Softmax 重新参数化技巧 [30] 来确保梯度的传播
4.4 Fusion Module (FM)
Through the dual clustering on both temporal and channel dimensions, our framework extracts the temporal feature 𝑋
temp
∈
R
𝑁
×
𝑑 and a channel mask matrix M ∈
R
𝑁
×
𝑁
for each time series
𝑋
∈
R
𝑁
×
𝑇
. Subsequently, we utilize a masked attention mechanism to further fuse them. This process can be formalized as follows.
4.4 融合模块(FM)
通过时间和通道维度的双重聚类,我们的框架为每个时间序列 𝑋 ∈ R 𝑁 ×𝑇 提取时间特征 𝑋 temp ∈ R 𝑁 ×𝑑 和通道掩码矩阵 M ∈ R 𝑁 ×𝑁 。随后,我们利用掩码注意力机制进一步融合它们。这个过程可以形式化如下。
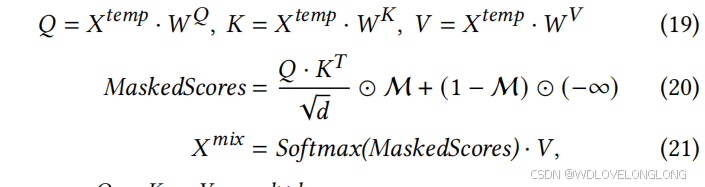
where
𝑊
𝑄
,𝑊
𝐾
,𝑊
𝑉
∈
R
𝑑
×
𝑑
are projection matrices in the attention block, MaskedScores
∈
R
𝑁
×
𝑁
is the attention score matrix,
𝑋
mix
∈
R
𝑁
×
𝑑
is the fused feature. With the application of the masked attention mechanism [60
], the Fusion Module effectively fuses the temporal features extracted by TCM based on the sparse correlations captured by CCM. We also adopt LayerNorm, FeedForward and skip-connection in the Fusion Module (FM) like a classic transformer block. Specifically, LayerNorm [2
] and SkipConnection [85
] ensure FM’s stability and robustness, while the Feed-Forward layer [14
] empowers the FM to capture complex fea
tures. Their synergistic operation optimizes the representational capacity and training efficiency of the Fusion Module. Finally, we adopt a linear projection to predict the future values, which is formulated as follows.
其中 𝑊 𝑄,𝑊 𝐾,𝑊𝑉 ∈ R 𝑑×𝑑 是注意模块中的投影矩阵,MaskedScores ∈ R 𝑁 ×𝑁 是注意分数矩阵,𝑋 mix ∈ R 𝑁 ×𝑑 是融合特征。通过应用掩蔽注意机制 [60],融合模块基于 CCM 捕获的稀疏相关性有效地融合了 TCM 提取的时间特征。我们还在融合模块 (FM) 中采用了 LayerNorm、FeedForward 和 skip-connection,就像经典的 Transformer 模块一样。具体而言,LayerNorm [2] 和 Skip Connection [85] 确保 FM 的稳定性和鲁棒性,而 Feed-Forward 层 [14] 使 FM 能够捕获复杂特征。它们的协同操作优化了融合模块的表示能力和训练效率。最后,我们采用线性投影来预测未来值,其公式如下。
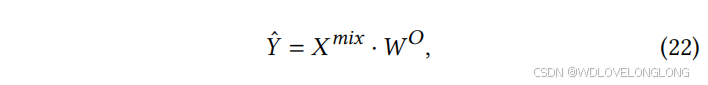
where
𝑊
𝑂
∈
R
𝑑
×
𝐹
,
𝑌
ˆ
∈
R
𝑁
×
𝐹
.
其中 𝑊 𝑂 ∈ R 𝑑×𝐹 , 𝑌ˆ ∈ R 𝑁 ×𝐹 。







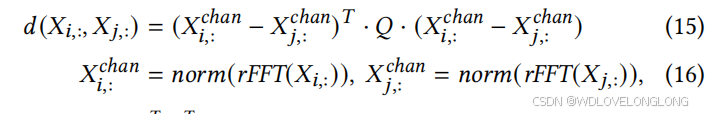


















 1811
1811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









