




 本文探讨了如何通过计算梯度理解卷积神经网络的工作原理,以GradCAM为例,详细剖析了特征图对输出的影响。通过链式法则,逐步揭示了从特征图到输出的数学过程,并提供了相关代码演示。
本文探讨了如何通过计算梯度理解卷积神经网络的工作原理,以GradCAM为例,详细剖析了特征图对输出的影响。通过链式法则,逐步揭示了从特征图到输出的数学过程,并提供了相关代码演示。
在一些对神经网络可解释性的研究中,总是会利用到损失函数对最后一层特征图进行求梯度的操作,例如著名的Grad CAM,因此对于卷积神经网络的理解不能仅仅停留在调包的阶段,我们需要拆解开它求梯度的黑盒。
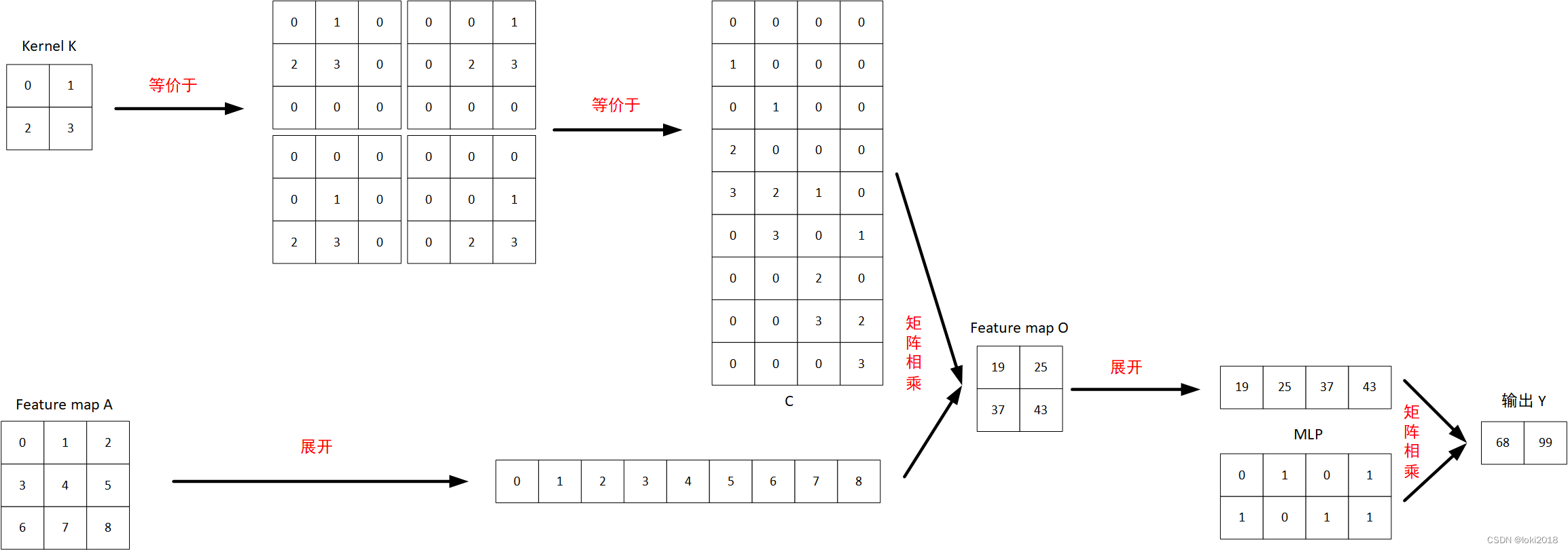
如图所示,假设有一个特征图AAA, 经过一个2×22 \times 22×2的卷积核KKK操作之后,得到一个新的特征图OOO,再将其展平后经过MLPMLPMLP得到一个长度为2的输出向量YYY。
如果想要知道特征图AAA的每个元素对最终输出的贡献大小,就需要计算出YYY对AAA中每个元素的偏导,即∂Y∂A\frac{ \partial Y }{ \partial A }∂A∂Y。
我们整理一下从特征图AAA得到输出YYY的过程,可以写为:
O=CONV(A)O=CONV(A)O=CONV(A)
Y=MLP(O)Y=MLP(O)Y=MLP(O)
因此根据链式求导法则,∂Y∂A=∂Y∂O∂O∂A\frac{ \partial Y }{ \partial A }= \frac{ \partial Y }{ \partial O} \frac{ \partial O }{ \partial A}∂A∂Y=∂O∂Y∂A∂O。
以输出Y1=68Y_1=68Y1=68为例,Y1=0∗O11+1∗O12+0∗O21+1∗O22Y_1=0*O_{11}+1*O_{12}+0*O_{21}+1*O_{22}Y1=0∗O11+1∗O12+0∗O21+1∗O22, 因此
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3181
3181


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








