深度学习--卷积神经网络(含链式反向梯度传导)
最新推荐文章于 2024-09-06 20:01:54 发布





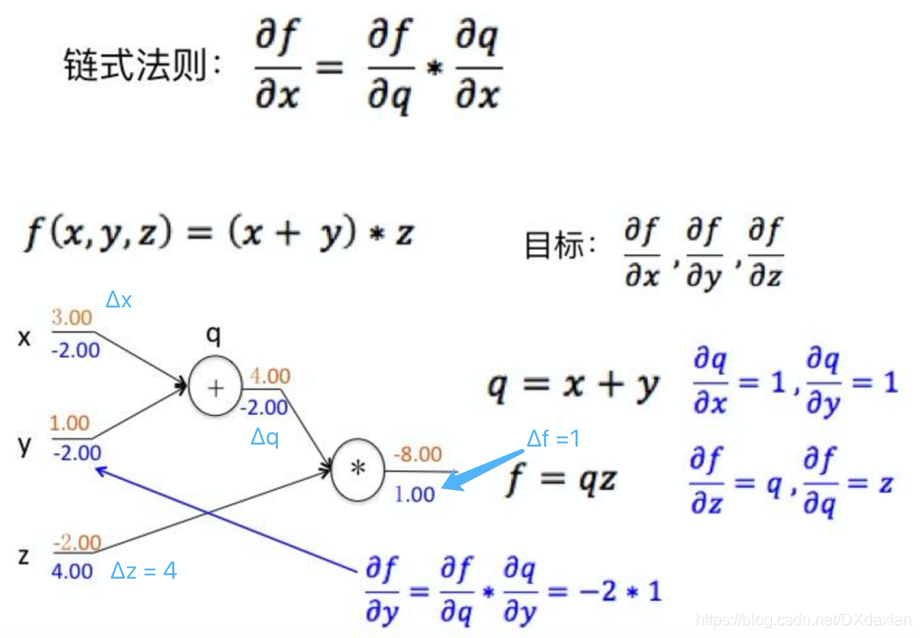
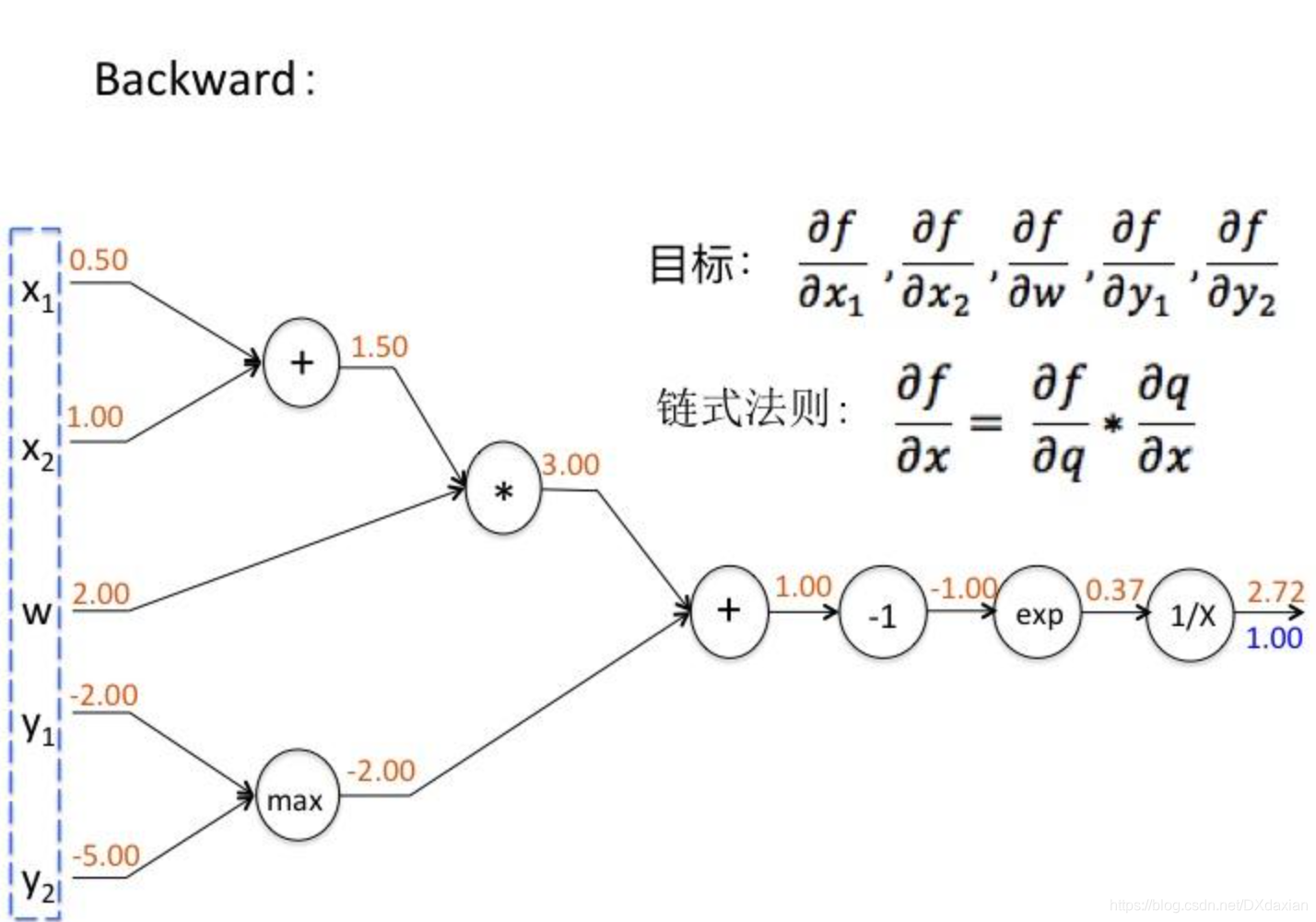
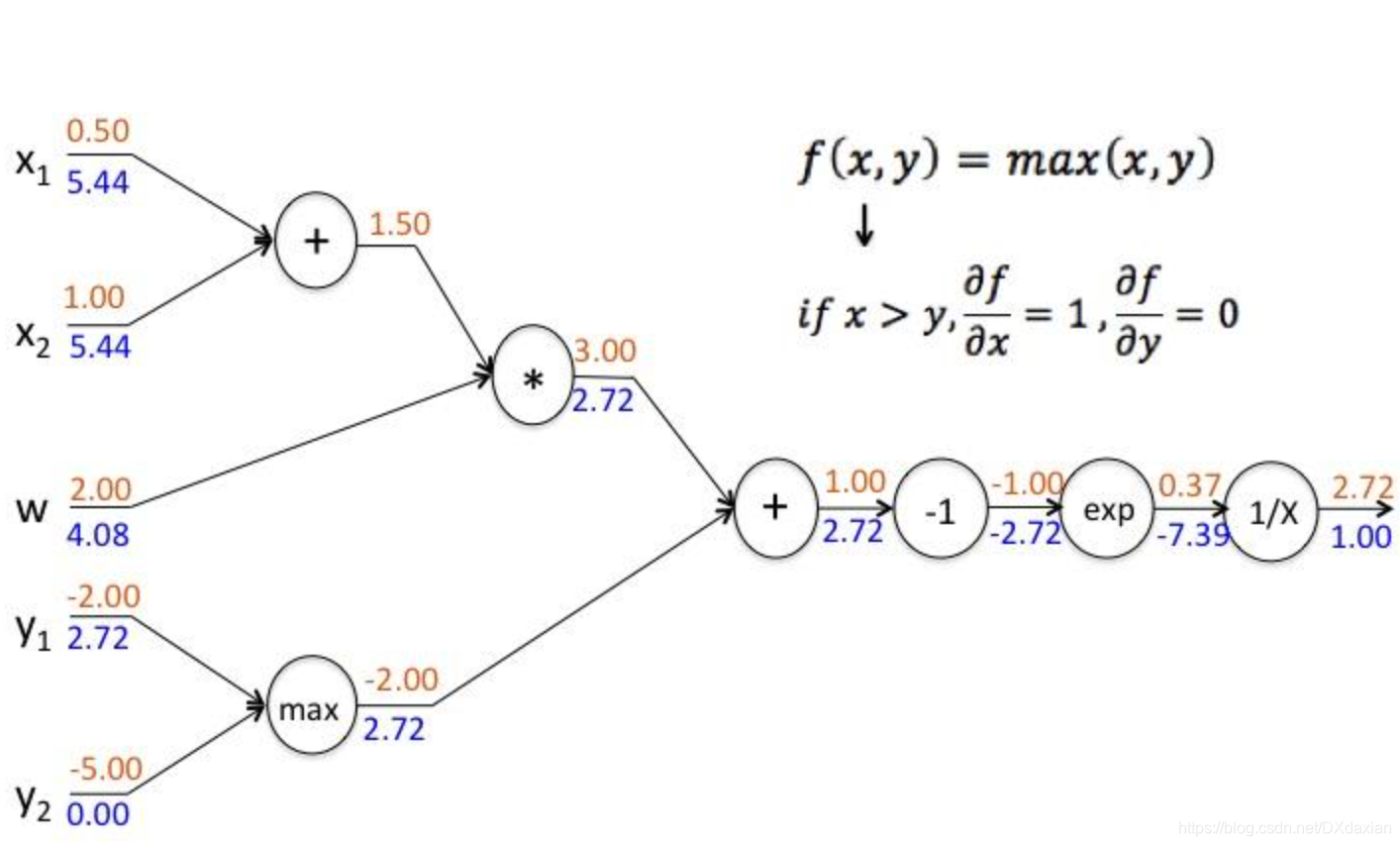
 本文深入探讨卷积神经网络(CNN),对比其与传统神经网络的区别,详细阐述卷积层的参数如卷积核大小、步长、边界扩充等,并解析链式反向梯度传导的数学原理,包括链式求导法则的应用。同时,介绍了CNN的功能层,如非线性激励、池化层和归一化层,以及整体架构中的感受野概念。
本文深入探讨卷积神经网络(CNN),对比其与传统神经网络的区别,详细阐述卷积层的参数如卷积核大小、步长、边界扩充等,并解析链式反向梯度传导的数学原理,包括链式求导法则的应用。同时,介绍了CNN的功能层,如非线性激励、池化层和归一化层,以及整体架构中的感受野概念。
本文深入探讨卷积神经网络(CNN),对比其与传统神经网络的区别,详细阐述卷积层的参数如卷积核大小、步长、边界扩充等,并解析链式反向梯度传导的数学原理,包括链式求导法则的应用。同时,介绍了CNN的功能层,如非线性激励、池化层和归一化层,以及整体架构中的感受野概念。
本文深入探讨卷积神经网络(CNN),对比其与传统神经网络的区别,详细阐述卷积层的参数如卷积核大小、步长、边界扩充等,并解析链式反向梯度传导的数学原理,包括链式求导法则的应用。同时,介绍了CNN的功能层,如非线性激励、池化层和归一化层,以及整体架构中的感受野概念。
 1221
1550
1594
1221
1550
1594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





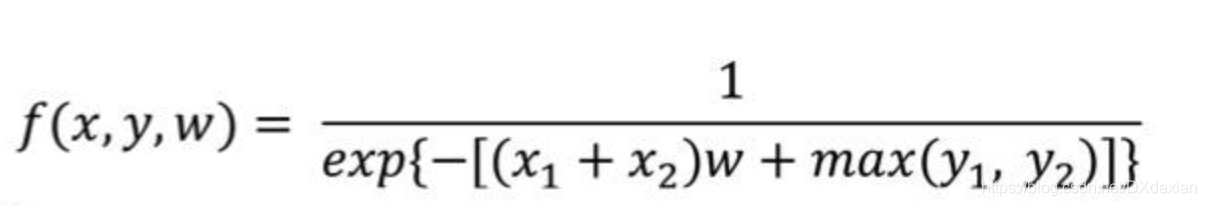

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























