




 本文介绍了向量量化与向量降维的区别,重点讨论了ProductQuantization(PQ)算法,通过子向量分解和聚类减少存储开销。此外,文中还提及了AdditiveQuantization,其无需向量划分,通过加和简单量化码本逼近原向量,以及ResidualVectorquantization,通过多步残差量化逼近原始数据。这些技术在大数据和大语言模型背景下提升存储效率和相似性搜索性能。
本文介绍了向量量化与向量降维的区别,重点讨论了ProductQuantization(PQ)算法,通过子向量分解和聚类减少存储开销。此外,文中还提及了AdditiveQuantization,其无需向量划分,通过加和简单量化码本逼近原向量,以及ResidualVectorquantization,通过多步残差量化逼近原始数据。这些技术在大数据和大语言模型背景下提升存储效率和相似性搜索性能。
1. 什么是向量量化
https://www.pinecone.io/learn/series/faiss/product-quantization/
首先需要搞清楚向量量化和向量降维的区别,在AI领域中,向量往往是以高维的形式存在的,每一维的元素都包含了数据的特征。例如一张图片在经过VGG16网络的计算后,输出的会是一个4096维的向量,而向量降维所研究的侧重点是如何将高维的向量转换为相对低维的向量,以提高计算效率,如下图所示。在此过程中,降维算法会去除高维向量中冗余的特征元素或者噪声,常见的算法有主成分分析(PCA)、线性判别分析(LDA)等。
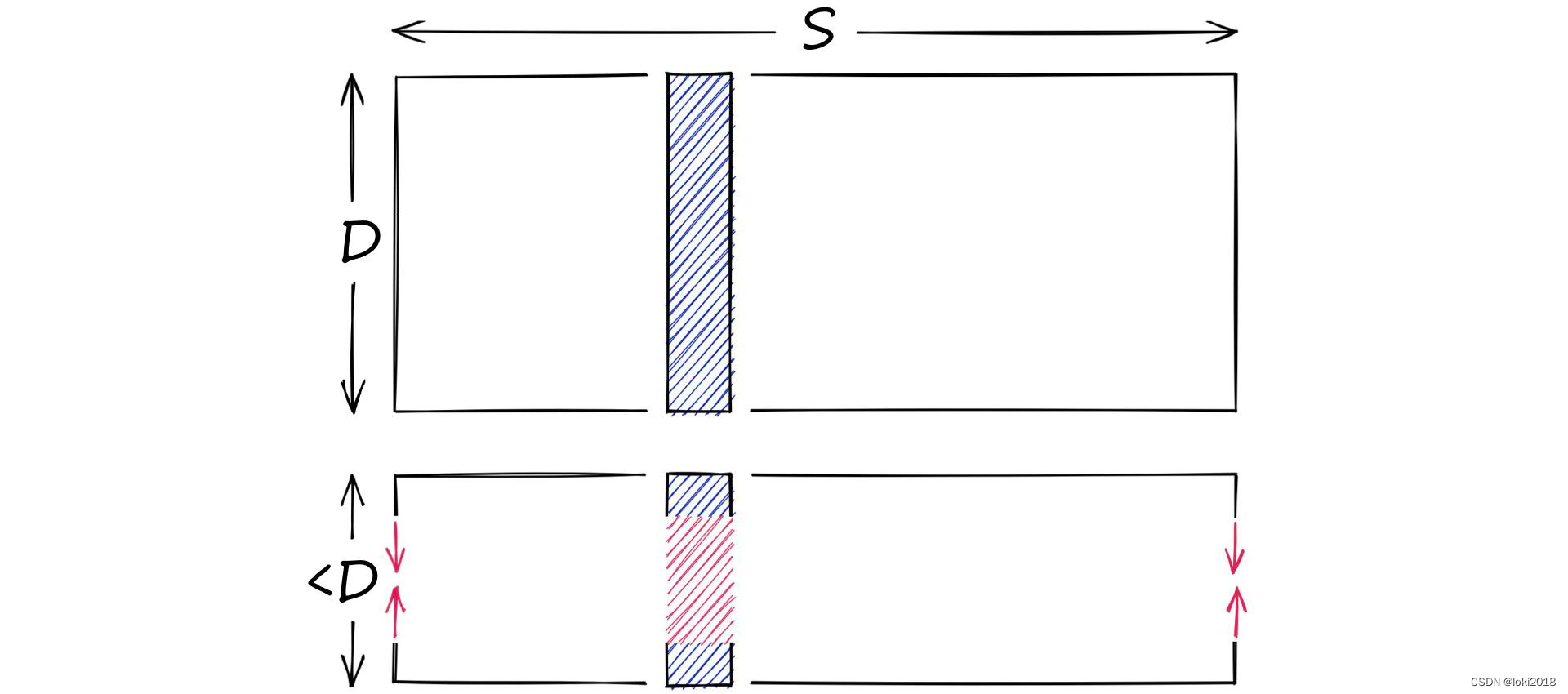
那么向量量化所研究的则是大规模高维向量的存储和相似性检索问题,如下图所示,它的目标是将海量的高维向量数据尽可能用相对有限的向量来进行表示,从而降低存储开销。尤其是在大数据和大语言模型时代,非结构化数据的存储和检索非常关键。最为简单的想法就是利用聚类算法对向量进行聚类,用聚类后的聚类中心向量来近似原始向量。因此,只需要存储聚类中心即可。
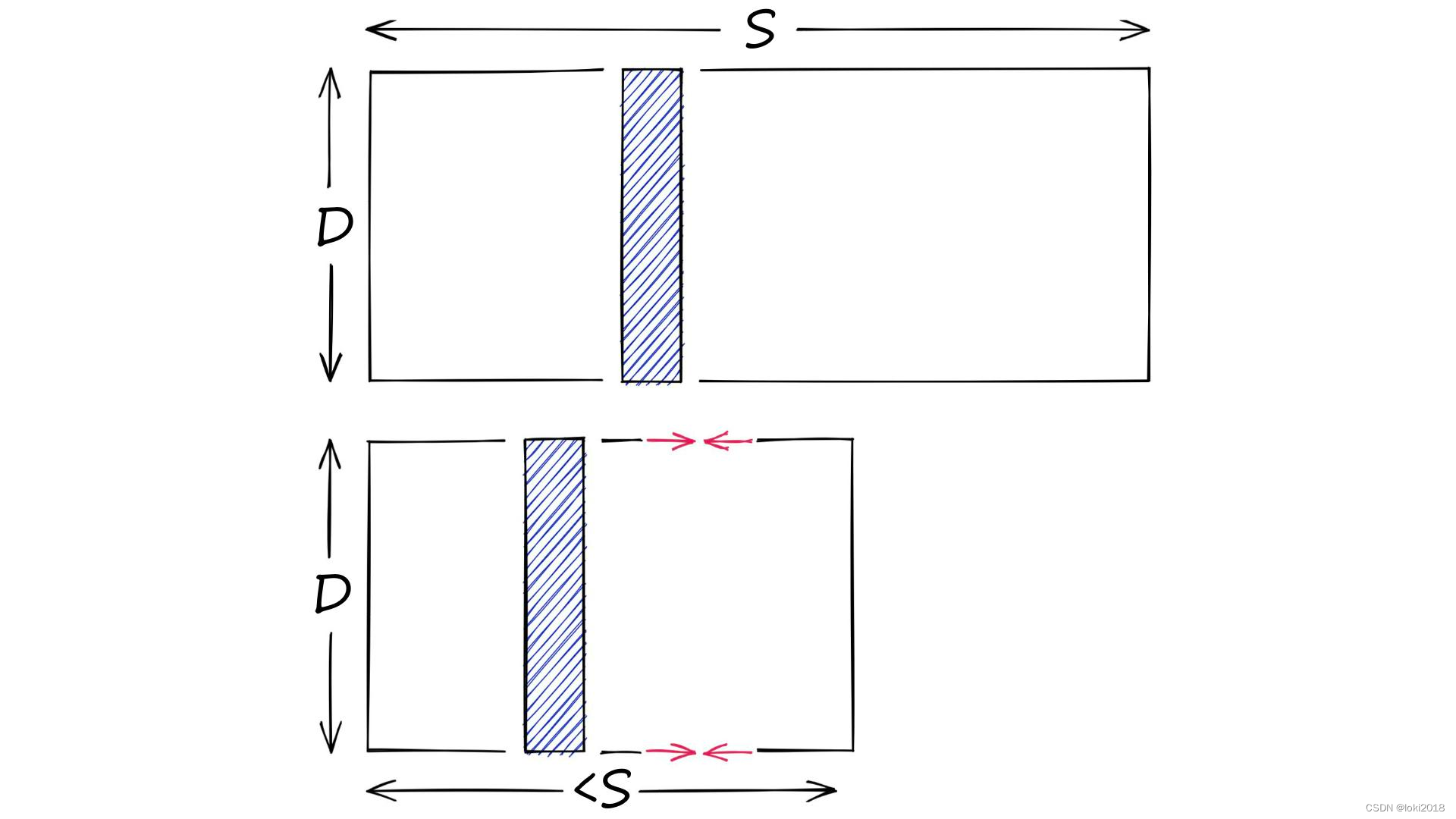
2. Product Quantization
Jegou H, Douze M, Schmid C. Product quantization for nearest neighbor search[J]. IEEE transactions on pattern analysis and machine intelligence, 2010, 33(1): 117-128.
我们首先介绍Product Quantization,下面简称为PQ算法,它的思想很简单,假设向量的维度为DDD,聚类中心个数为KKK,如果使用Kmeans算法,那么存储的复杂度为D×KD \times KD×K。而PQ算法首先将DDD维向量分解为mmm个子向量,每个子向量的维度为D∗=D/mD^* =D / mD∗=D/m, 分别对这些子向量进行聚类,将子空间中聚类中心的个数记为k∗k^*
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4394
4394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









