神经网络参数初始化
- 防止梯度消失或者爆炸: 若是梯度太小,可能0.01然后都是5层,则梯度消失,若是梯度太大则会梯度爆炸
- 提高收敛速度: 例如tanh 的(0,1)就比sigmoid的(0, 0.25)的更快
- 破除对称性: 就是让w不同,防止训练出相同的东西

常见的初始化方法
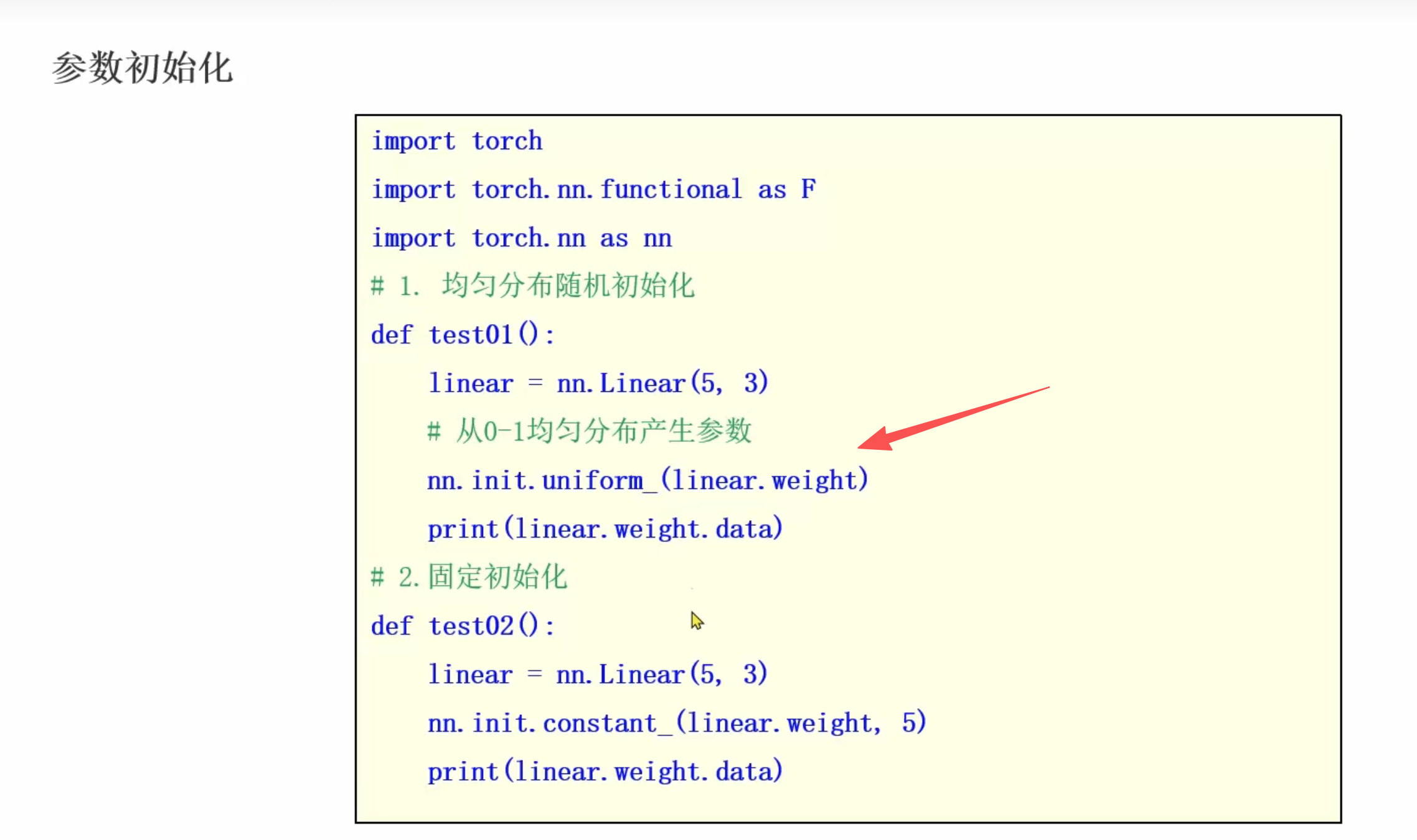
- 均匀初始化:nn.init_uniform_()
- 正太分布初始化 : nn.init.normal_()
- 全0初始化: nn.init.zeros_()
- 全1初始化: nn.init_ones_()
- 固定值初始化: nn.init_constant_()
- kaiming初始化(HE初始化):kaiming_uniform_(),kaiming_normal_()
- xavier初始化(泽威尔):
随机初始化有两大类:均匀分布初始化和正太分布初始化
均匀分布初始化nn.init.uniform_()
- 默认取值为(0,1)
- 若设置之后是(- 1/√d ,1/√d)
- d 是输入个数,也就是上一层的输出个数
正太分布初始化nn.init.normal_()

全0初始化nn.init.zeros_()

全1初始化nn.init.ones_()
固定值初始化nn.init.constant_()
kaiming初始化,只能对w初始化
- 正太分布的he初始化:nn.init.kaiming_normal_()
- 随机分布的he初始化:nn.init.kaiming_uniform_()
- 只考虑上层输入的个数(fan_in)
- 非常适合ReLu激活函数

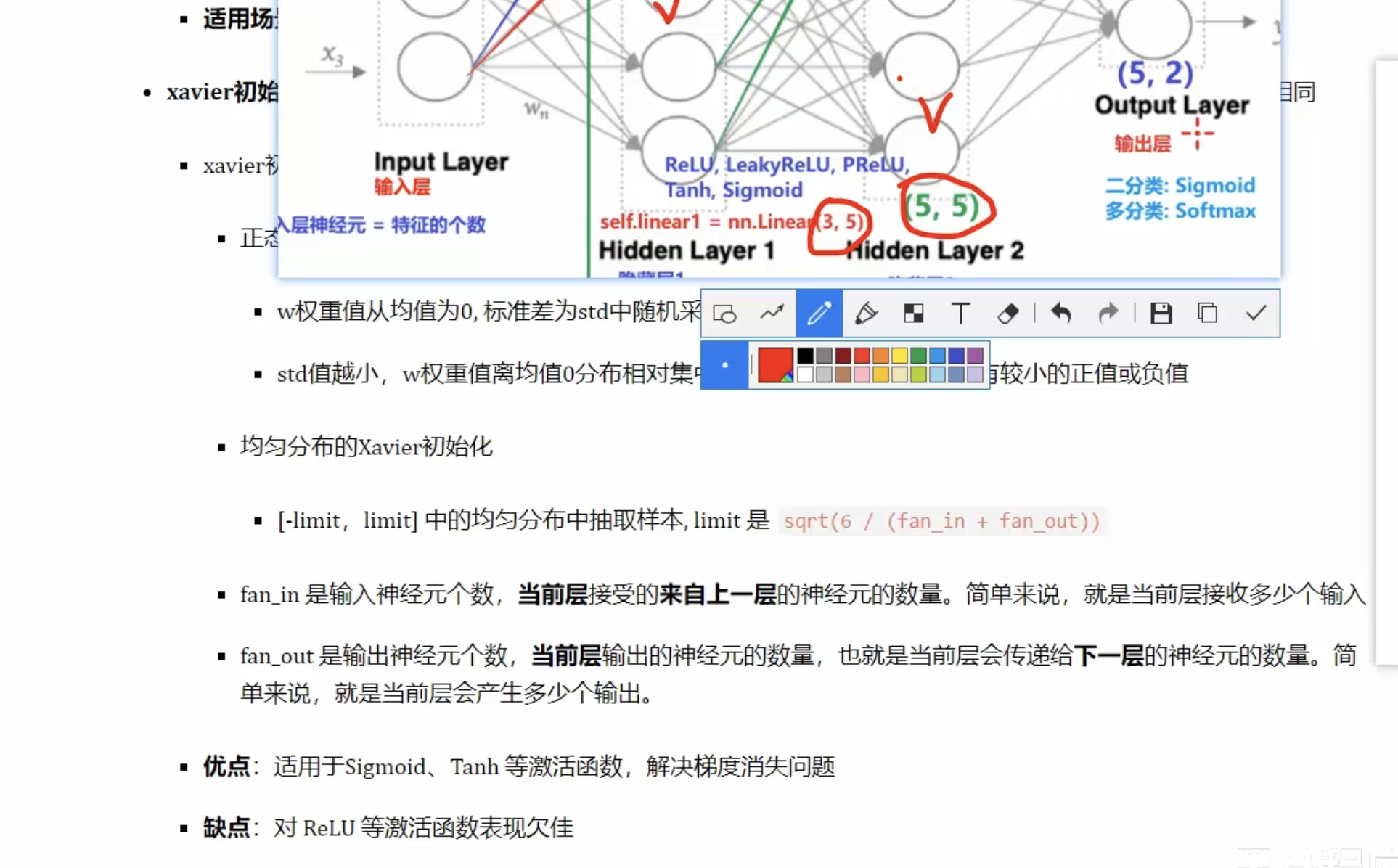
xavier初始化,只能对w初始化
- 正太分布
- 均匀分布
- 也是上一层的输入个数fan_in,和这一层的输出fan_out
- 适用于sigmoid 和tanh,
- 对ReLu等其他激活函数支持不好


测试代码
import torch
from torch import nn
# 均匀分布初始化
def demo_1():
print('demo_1')
linear = nn.Linear(5,3)
nn.init.uniform_(linear.weight)
nn.init.uniform_(linear.bias)
print(linear.weight.data)
print(linear.bias.data)
print('-' * 30)
pass
# 正太分布初始化
def demo_2():
print('demo_2')
linear = nn.Linear(5, 3)
nn.init.normal_(linear.weight)
nn.init.normal_(linear.bias)
print(linear.weight.data)
print(linear.bias.data)
print('-' * 30)
pass
# 全0分布初始化
def demo_3():
print('demo_3')
linear = nn.Linear(5, 3)
nn.init.zeros_(linear.weight)
nn.init.zeros_(linear.bias)
print(linear.weight.data)
print(linear.bias.data)
print('-' * 30)
pass
# 全1分布初始化
def demo_4():
print('demo_4')
linear = nn.Linear(5, 3)
nn.init.ones_(linear.weight)
nn.init.ones_(linear.bias)
print(linear.weight.data)
print(linear.bias.data)
print('-' * 30)
pass
# 固定值分布初始化
def demo_5():
print('demo_5')
linear = nn.Linear(5, 3)
nn.init.constant_(linear.weight,3)
nn.init.constant_(linear.bias,3)
print(linear.weight.data)
print(linear.bias.data)
print('-' * 30)
pass
# kaiming初始化,只能对w进行初始化
def demo_6():
print('demo_6')
linear = nn.Linear(5, 3)
nn.init.kaiming_uniform_(linear.weight)
print(linear.weight.data)
print(linear.bias.data)
nn.init.kaiming_normal_(linear.weight)
print(linear.weight.data)
print(linear.bias.data)
print('-' * 30)
pass
# xavier初始化 只能对w进行初始化
def demo_7():
print('demo_7')
linear = nn.Linear(5, 3)
nn.init.xavier_normal_(linear.weight)
print(linear.weight.data)
print(linear.bias.data)
nn.init.xavier_normal_(linear.weight)
print(linear.weight.data)
print(linear.bias.data)
print('-' * 30)
pass
if __name__ == '__main__':
demo_1()
demo_2()
demo_3()
demo_4()
demo_5()
demo_6()
demo_7()
测试结果
D:\software\python.exe -X pycache_prefix=C:\Users\HONOR\AppData\Local\JetBrains\PyCharm2025.2\cpython-cache "D:/software/PyCharm 2025.2.4/plugins/python-ce/helpers/pydev/pydevd.py" --multiprocess --qt-support=auto --client 127.0.0.1 --port 60462 --file C:\Users\HONOR\Desktop\python\test18_initialization.py
Connected to: <socket.socket fd=620, family=2, type=1, proto=0, laddr=('127.0.0.1', 60463), raddr=('127.0.0.1', 60462)>.
Connected to pydev debugger (build 252.27397.106)
demo_1
tensor([[0.8940, 0.0739, 0.2809, 0.4060, 0.8639],
[0.6235, 0.6284, 0.7542, 0.7762, 0.7209],
[0.4628, 0.2258, 0.7907, 0.1969, 0.9645]])
tensor([0.5167, 0.8713, 0.3997])
------------------------------
demo_2
tensor([[ 0.3861, 0.1851, 1.0631, 1.1591, -0.2224],
[-0.1735, 1.5185, 0.1128, 0.2620, -0.1277],
[ 0.7913, 0.1828, -1.4538, -0.3275, -0.5901]])
tensor([0.0191, 0.8115, 0.7083])
------------------------------
demo_3
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
tensor([0., 0., 0.])
------------------------------
demo_4
tensor([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
tensor([1., 1., 1.])
------------------------------
demo_5
tensor([[3., 3., 3., 3., 3.],
[3., 3., 3., 3., 3.],
[3., 3., 3., 3., 3.]])
tensor([3., 3., 3.])
------------------------------
demo_6
tensor([[-0.4026, -0.0427, -1.0667, 0.9971, -0.3477],
[ 0.7255, -0.3075, 0.1558, -0.7823, 0.0470],
[ 0.4073, 0.4456, 1.0452, -0.7386, -0.5622]])
tensor([ 0.1475, -0.4063, 0.2160])
tensor([[ 1.1510, -0.3566, 0.9788, 0.0305, -0.1595],
[-0.3426, 0.2737, -0.8439, 0.2259, 0.5477],
[ 0.4603, 0.2947, -0.7005, -0.2742, -0.0610]])
tensor([ 0.1475, -0.4063, 0.2160])
------------------------------
demo_7
tensor([[-0.3370, 0.0072, 0.2047, 0.7145, -0.6313],
[-0.2495, 0.5183, 0.6535, -0.1301, -0.7699],
[ 0.7114, 0.4274, -0.4832, 0.7001, 0.5021]])
tensor([ 0.3024, -0.3154, 0.3243])
tensor([[-0.7751, -0.5671, -0.8507, 0.1896, -0.7609],
[ 0.0674, 0.8529, -0.3893, -0.5297, 1.0451],
[ 0.3542, -0.6810, -0.9902, -0.5045, 0.5556]])
tensor([ 0.3024, -0.3154, 0.3243])
------------------------------
Process finished with exit code 0























 1361
1361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









