




声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Effective and Differentiated Use of Control Information for Multi-speaker Speech Synthesis
本文为小米在2021.07.07更新的文章,主要在multispeaker model和speaker adaptation上做了工作,使adap效果提高,具体的文章链接
https://arxiv.org/pdf/2107.03065.pdf
1 研究背景
研究人员对于语音合成的控制信息在tts系统中扮演的角色关注较少,比如speaker embedding,pitch和enery。本文使用这些信息在tacotron系统结构上进行修改,引入Excitation spectrogram模块,从而使合成质量更好。
2 详细设计
整体的系统在tacotron架构上进行修改,具体如图1所示。(乍一看还以为fastspeech)。具体的第一个贡献点是使用enery和pitch信息来生成一种excitation spectrogram信息,该模块的设计根据为source-filter模型,即声音谐波结构,具体的设计为公式3,4,5。另外一个贡献点是设计了CGLSTM(Conditional Gated LSTM)即把speaker embedding信息添加进lstm结构中,具体如图2和公式6,7,8所示。
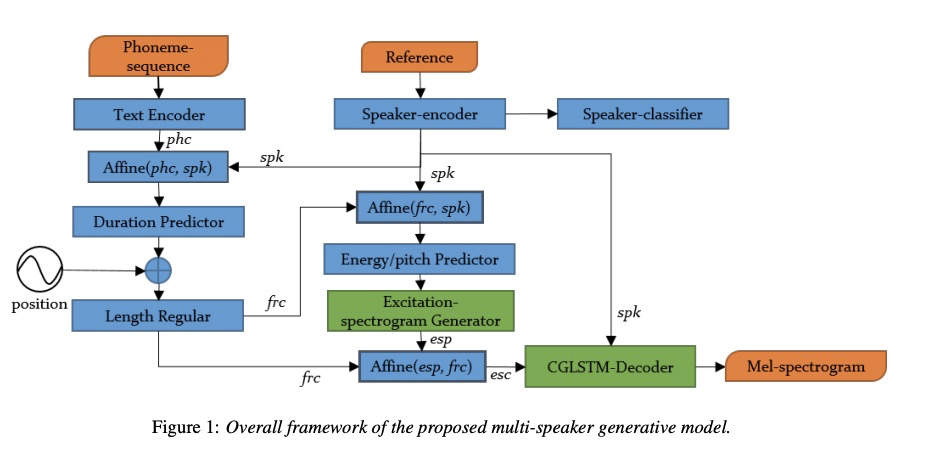
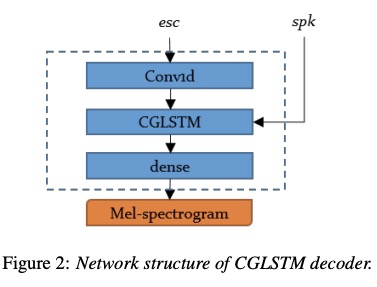
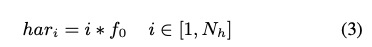

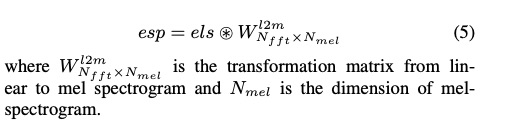
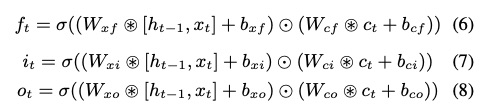
3 实验
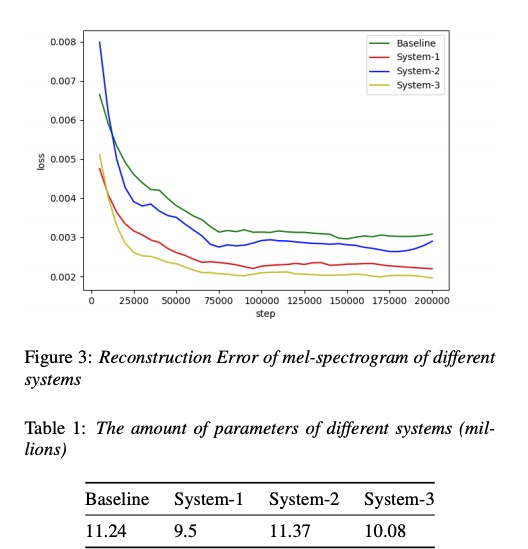
本文实验没有对比第三方的平台系统,感觉实验偏少。下边baseline是不使用CGLSTM和excitation spectrogram generator。图3是各种系统的loss情况,system-3的loss低,同时参数量也较小,如table1。table2显示mos system3最好。


4 总结
本文在tacotron基础上设计excitation spectrogram generator和CGLSTM,从而使speaker adaptation效果更好。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











