





声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Continual Speaker Adaptation for Text-to-Speech Synthesis
本文是瑞士圣加仑大学在2020.03.26更新的文章,主要使用持续性学习方法来解决多人模型在增加新的speaker造成灾难性遗忘的问题,具体的文章链接
https://arxiv.org/pdf/2103.14512.pdf
1 研究背景
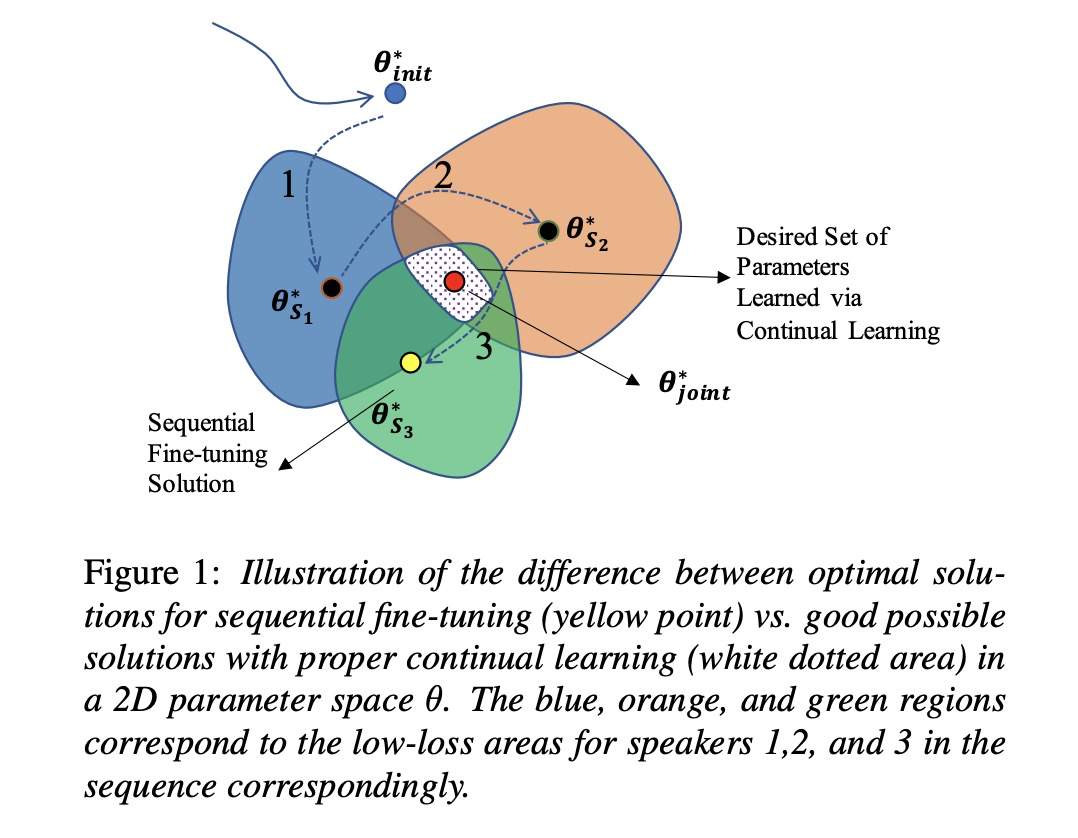
当multi-speaker tts模型增加新的说话人,通常的方案就是在已经训练的模型上对新添加的说话进行微调,但这种方案会造成对原有的说话人信息收到破坏,该种现象被称为灾难性遗忘(CF:catastrophic forgetting)。比如图1所示,白色区域才是对已有说话人不破坏的参数区域,本文使用持续性学习(continual learning)来寻找该参数区域。
2 详细设计
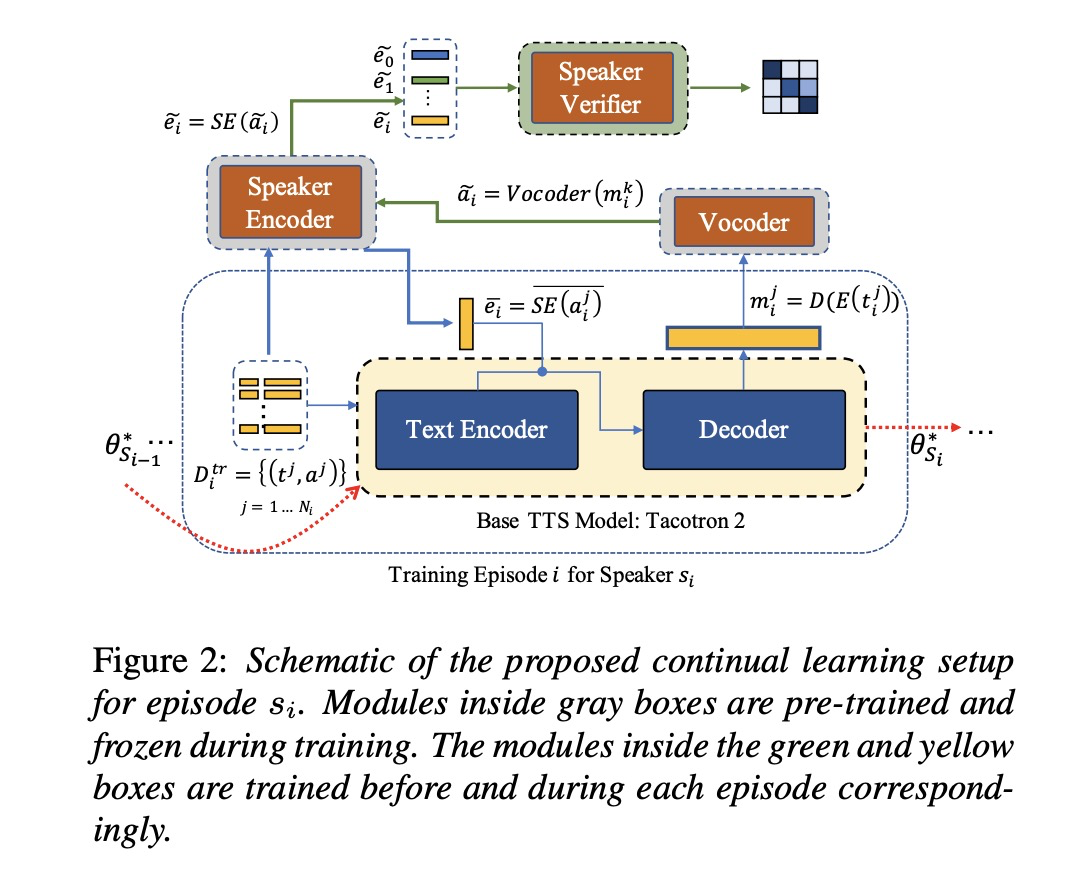
本文的系统架构如图2所示,主要包括:base TTS, speaker encoder和speaker verifier。图中的灰色模块是预训练好后不参加训练。本文的评价值指标为公式1和2的retained accuracy 和forgetting。
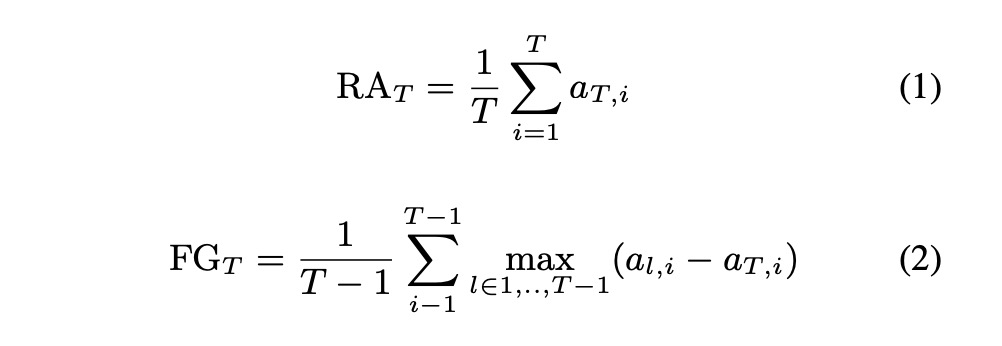
3 实验
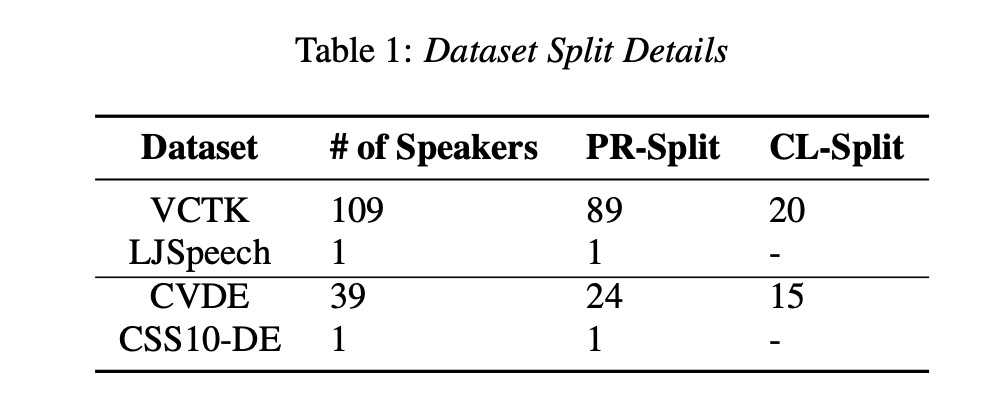
本文的使用的数据如table1所示,其中本文对比以下几种方案:
1)joint training:所有数据一起训练,作为系统的上限
2)sequential adaptation (sa):一个speaker接着一个speaker,作为系统的下限
3)weight regularization: 是持续性学习一种方案,典型的为EWC
4) experience replay (ER): 是持续性学习一种方案,该方案保留以前少量数据一起训练,其算法为algorithm。

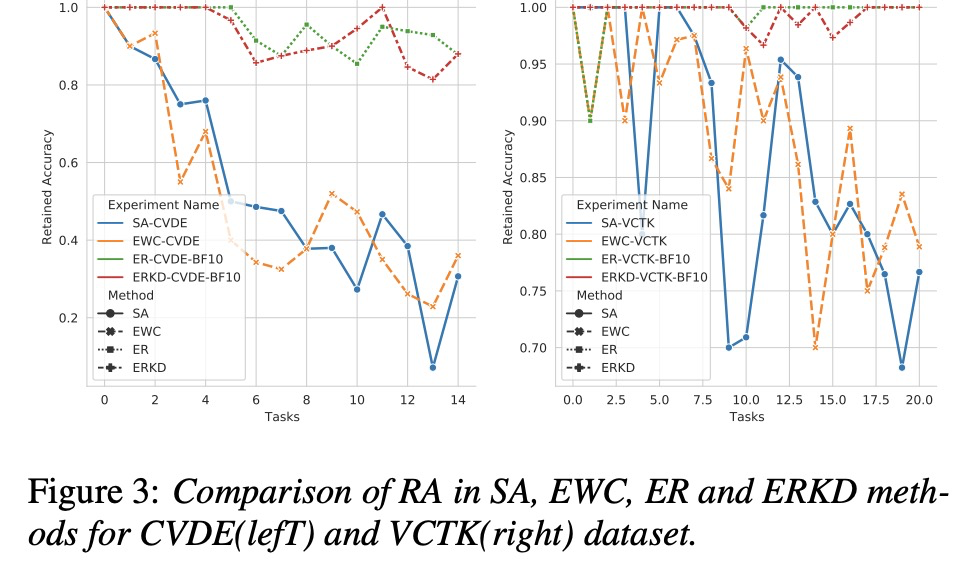
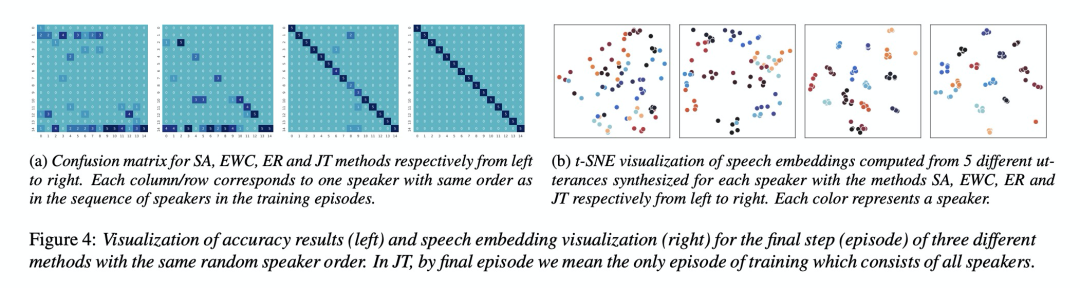
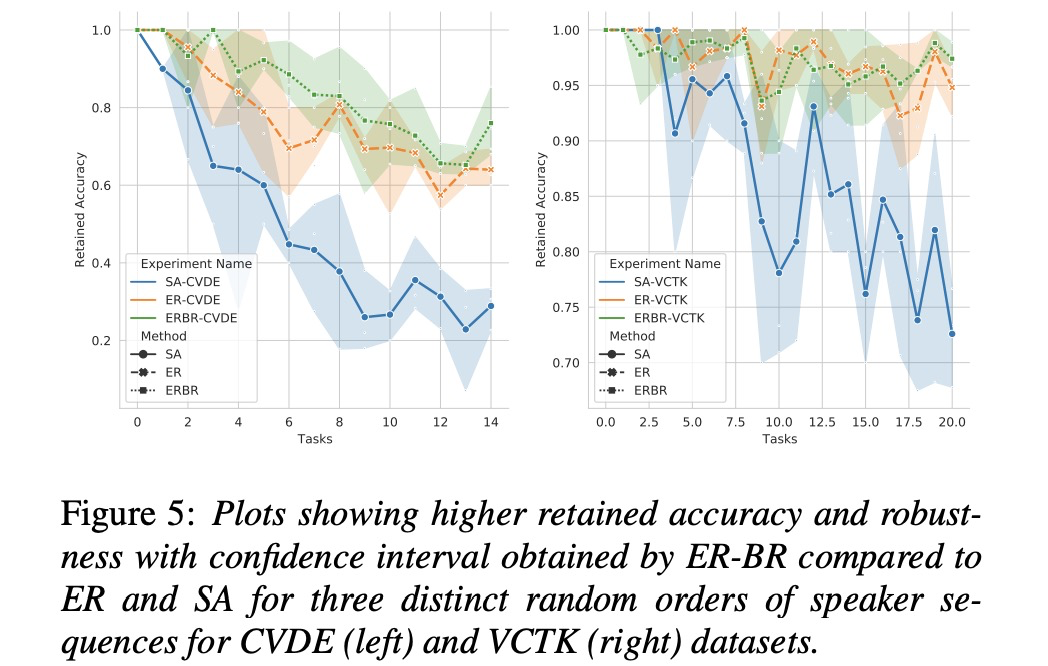
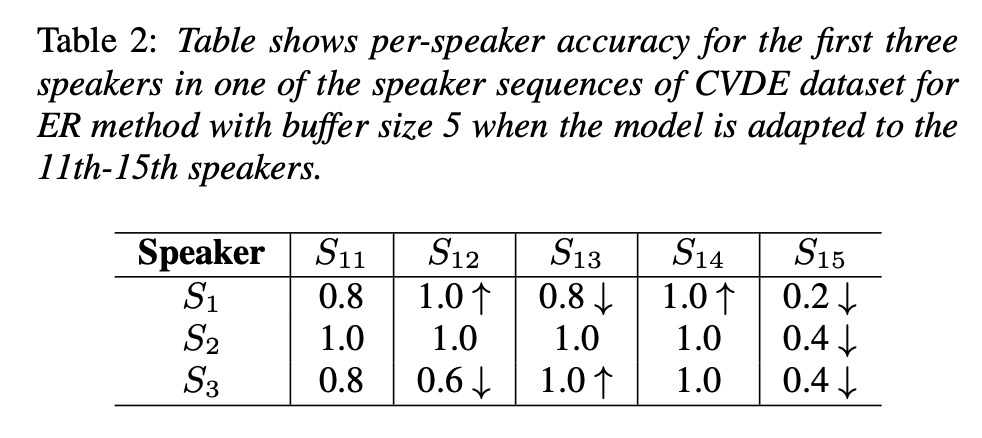
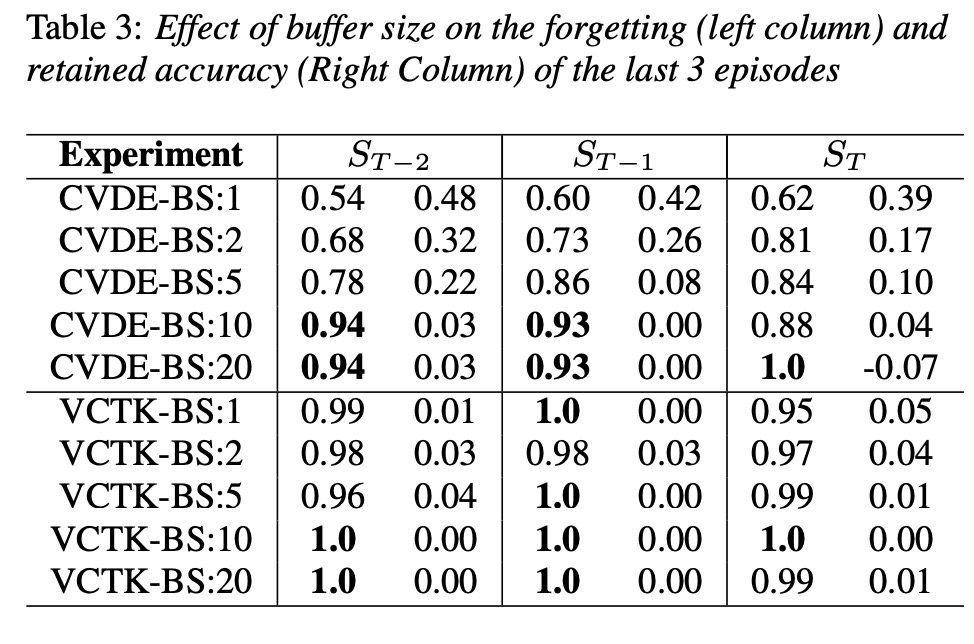
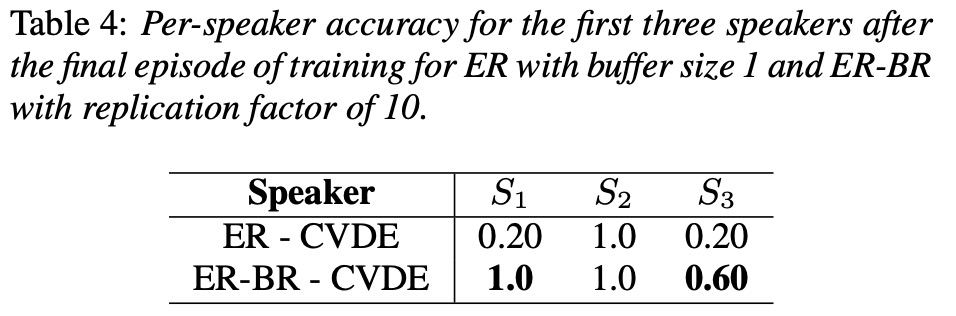
接下来看一看实验结果。图3和图4,图5对比以上几种方案,结果显示基于ER效果较好。table2测试er方案,后续speaker对前面speaker的影响。table3显示ER的buffer等10就很好。
5 总结
本文使用持续性学习来解决multi-speaker tts的灾难性遗忘的问题,结果显示experience replay结果做好。


















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











