




声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Distant Supervision for Polyphone Disambiguation in Mandarin Chinese
本文章是中国科学院软件研究所在interspeech 2020发表的文章,主要的工作为使用远程监控的方法来对中文的多音字进行消歧,具体的文章链接
https://www.isca-speech.org/archive/Interspeech_2020/pdfs/2427.pdf
1 背景
g2p(grapheme-to-phoneme)模块在语音合成系统必不可少的模块,对于大部分的汉子只有一个对应的读音,但中文中存在一个字对应多个读音的问题,我们成为该类字为多音字,多音字的读音需要根据上下文的语境才能够确认。通常多音字消歧的方案分为两类:基于规则的方案和基于数据驱动的方案。基于规则的方案是通过开发者手工写规则来处理多音字,该方案的缺点是覆盖样本较低。基于数据驱动的方案是使用标注的数据来训练模型,然后使用该模型来预测多音字读音(分类问题),该方案的缺点是无法获取大量的标注多音字训练语料,而且语料存在覆盖率不全,数据分布不平衡等等问题。本文提出使用远程监控的方案直接把character sequence映射到phoneme sequence,更好对多音字消歧。
2 详细设计
图1为本文的详细架构图,主要分为三个模块:distantly supervised data generation module, character-phoneme transformation module和reranking module。其中distantly supervised data generation module主要功能是生成<character, phoneme>训练语料,为haracter-phoneme transformation module和reranking module提供训练数据。character-phoneme transformation module 是把<character, phoneme>进行映射的模块,该模块本文使用三种常用的Seq2Seq模型:global attention的LSTM网络、Tansformer和CNN。reranking module对预测的phoneme sequence进行打分,选取得分最高的序列,添加该模块主要是为了缓解distantly supervised data generation module生成的数据带噪。
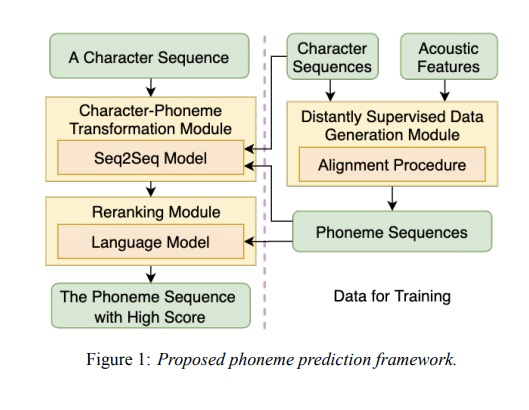
3 实验
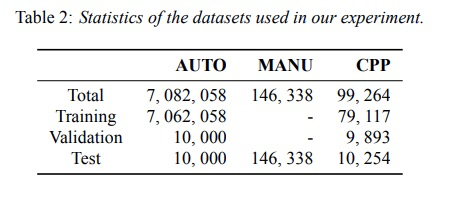
本文主要使用Auto, manu和cpp数据,其中auto数据是distantly supervised data generation module生成的数据,实验数据分配图table 2所示。
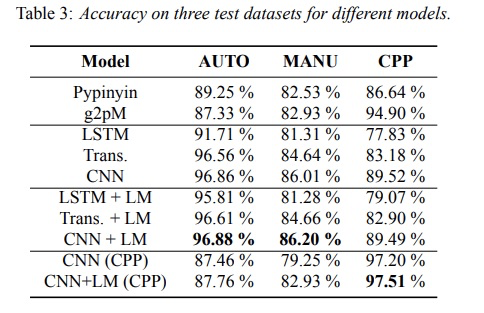
先看一下准确率,本文提到的各种方法比基准方案pypinyin和g2p较优。而且使用LM进行rerank提高了准确率。
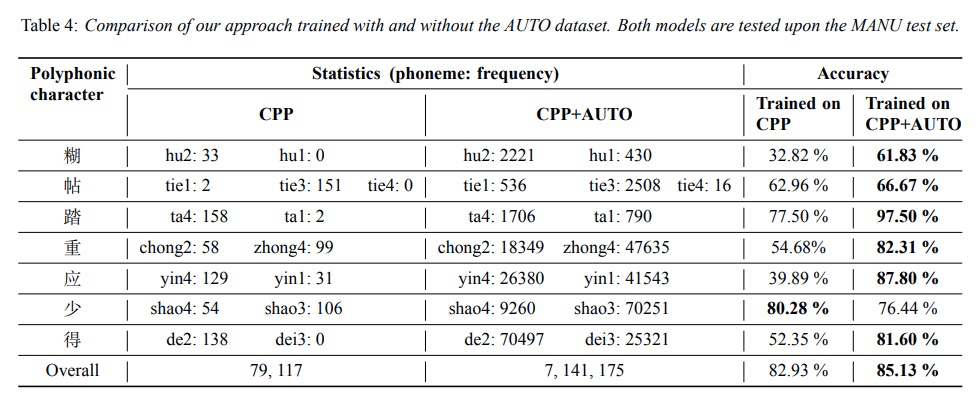
最后比较是否使用auto数据的效果(distantly supervised data generation module的效果),结果显示使用auto数据较好。
4 总结
本文提出使用distantly supervised来对多音字进行消歧,实验证明本文提出的方案可以获得较高的准确率。(说实话,我对LM的那块还没研究透,先做个标记,等有时间看看LM相关的内容)



















 1798
1798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











