




一、简介
我们前面已经和大语言模型(LLM)做了很多交互了。相信此时我们也明白,大模型做不了什么事情,他只是生成文本,这个我们已经看到了。或者使用function call来调用一些函数等等。
所以我们目前清楚的是语言模型本身无法执行作 - 它们只是输出文本。LangChain 的一大用例是创建agent 。 agent是基于LLM推理引擎的系统,用于确定要采取哪些作以及执行作所需的输入。执行作后,可以将结果反馈到 LLM,以确定是否需要更多作,或者是否可以完成。这通常是通过 tool-calling来实现的。也就是说是要基于我们上一篇文章中介绍的tool来构建一个系统,这个系统可以基于大模型来实现他选择的功能。
通俗来说,我们可以把 AI Agent 想象成一个“超级秘书”或“百科全书”。它通过对话了解你的需求,然后利用自身强大的知识库和学习能力,为你提供有针对性的帮助,比如:
- 信息查询:回答你的各种问题,从历史人文到科学技术,从生活百科到行业知识。
- 写作辅助:帮你完成文案、论文、代码等写作任务,提供素材收集、内容生成、文字润色等服务。
- 数据分析:帮你处理和分析海量数据,提取有价值的信息和见解,制作数据可视化图表。
- 创意设计:为你提供创意灵感,协助完成图像、音频、视频等多媒体内容的设计制作。
- 任务规划:帮你制定日程计划、工作安排,优化时间和资源分配,提高效率。
AI Agent 就有点像一个全能的私人助理,7×24 小时为你待命,用智能化的方式满足你的各种需求。
那么,AI Agent 具体是如何实现的呢?
目前主流的实现方式是基于提示词(Prompt)的任务编排。Prompt 是一种人与 AI 对话的范式,通过给 AI 下达指令(instruction)来引导 AI 执行任务。例如你对 AI 说“帮我写一个 500 字关于 AIGC 的普及文章”,AI 就会按照这个 Prompt 生成相应的教程内容。
一个 AI Agent 通常由多个不同领域、不同能力的 AI 模型和插件组成。比如每个模型负责处理某一类任务,比如文本生成模型、图像生成模型、数据分析模型等,然后每个插件负责完成特定的辅助功能,比如 OCR 插件可以帮你将上传的图片解读出文字,飞书文档插件可以帮助你将你最终生成的内容保存到指定的飞书文档上。
当用户提出一个复杂的需求时,需要将这个需求拆解成多个子任务,再将每个子任务分配给对应的 AI 模型或插件来执行。这个过程就叫任务编排或者工作流。任务编排需要一个调度中心来指挥协调各个模型和插件,把每个部分生成的内容整合在一起,形成最终的输出结果。
举个例子,如果你对 AI Agent 说 “帮我制作一个介绍中国景点的 PPT”,为了完成这个任务,AI Agent 需要:
先由一个专门的 Prompt 优化模型将你的需求转化成一系列清晰明确的子任务:
- 搜集整理中国主要景点的文字信息;
- 搜集筛选每个景点的精美图片;
- 依次生成每一页 PPT 的文字内容;
- 为每一页 PPT 匹配设计相应的布局和图片;
- 完成 PPT 的整体美化和特效。
- 然后任务编排系统将这些子任务分别分配给负责文本搜索、图像搜索、文本生成、PPT 设计的 AI 模型来执行。每个模型各司其职,完成分内之事。
最后,任务编排系统将各个模型生成的内容有机整合,形成一个完整的介绍中国景点的 PPT。在这个过程中,还可能涉及对 PPT 反复修改和优化,以达到最佳的展示效果。
而且他还能不断优化自己的问答记忆,来使得下一次的问答更加精准。
总之他是我们之前接触的诸多概念的一个更上层的东西,他负责整合那些能力然后分析输入,并且基于大模型来完成用户的要求。也就是说他是一个产品,而我们之前做的都是一些能力。
二、langchain实现agent
我们将会使用langchain来实现agent。langchain中集成了大量的工具使得我们可以很方便的就构建出来自己的agent。
1、官方文档
我们打开langchain的文档
找到这个位置,点进去看一下agent的实现。
2、实现agent
我们在上一篇文章中使用tools实现了一些llm外部的能力,不管是维基百科的检索还是加减乘除的调用。我们看到大模型可以根据具体的prompt选择正确的实现。但是我们又说大模型不具备直接执行tools的能力,我们需要把一些消息和文本统一交给绑定了tool的llm才可以调用执行。这是我们已经完成的。
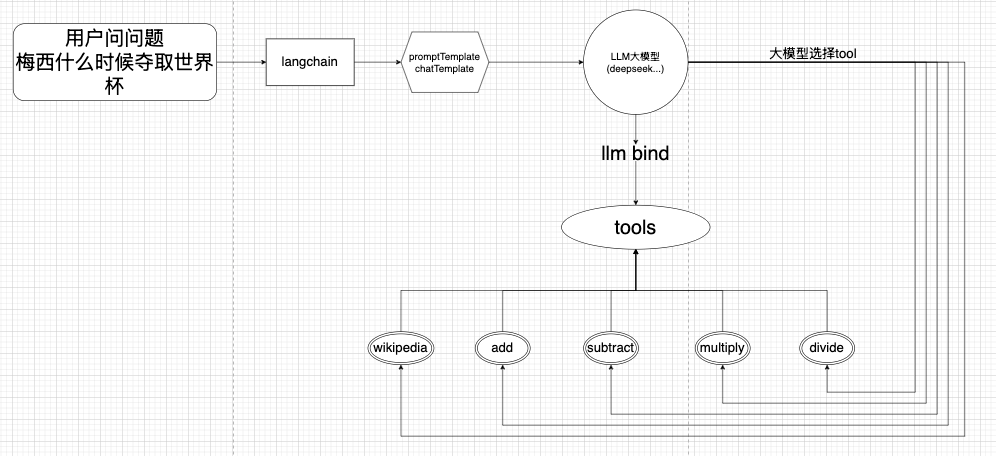
但是这是我们自己调用代码实现的,现在这部分能力应该交给agent。也就是这张图应该被改写为不是大模型去选择tool,也不是选择之后需要一些信息去执行tool,而是agent,他帮我们选择,执行tool。来得到最后结果。这样你会节省很多精力,不需要写那么多代码了。并且他会拆分你的输入,选择不同的模型去执行,并且汇聚返回。
所以当agent出现的时候,我们就不需要面对那么多的概念了,agent会帮我们搞定一切。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
from langchain.agents import initialize_agent,AgentType
from dotenv import load_dotenv
llm = ChatOllama(base_url = "http://127.0.0.1:11434",model = "huihui_ai/deepseek-r1-abliterated:14b",temperature = 0.5,num_predict = 10000)
load = load_dotenv("./.env")
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
@tool
def add(a: int, b: int) -> int:
"Add two numbers and return a result."
return int(a) + int(b)
@tool
def subtract(a: int, b: int) -> int:
"""Subtract two numbers and return a result."""
return a - b
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers and return a result."""
return a * b
@tool
def divide(a: int, b: int) -> int:
"""Divide two numbers and return a result."""
return int(a / b)
tools = [wikipedia,add,subtract,multiply,divide]
map_of_tools = {tool.name:tool for tool in tools}
# 构建一个agent,传入llm和tools。并且指定agent类型是AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,这样可以给我们的tool传参
# verbose表示详细输出处理过程
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
query = 'Whats is the sum of 1 and 2 . Who is kobe?'
resp = agent.run(query)
print(resp)
运行程序可以看到
<think>
Okay, so I need to figure out what the user is asking for. The first part says "whats is the sum of 1 and 2." Hmm, that's a math problem. Let me check: 1 plus 2 equals 3. That seems straightforward.
Then the second part asks, "Who is kobe?" I think they're referring to Kobe Bryant, the basketball player. I'll look up his information from Wikipedia. He was a famous NBA player known for his skills and achievements with the Los Angeles Lakers.
So I need to provide both answers in the required format.
</think>
Okay, let's break this down step by step.
First, the user asked about the sum of 1 and 2. That's a simple math problem. Let me use the add tool to calculate that.
Next, they asked "Who is kobe?" I'll look up Kobe Bryant on Wikipedia to provide an accurate answer.
Now, let's present both answers in the correct format.
Action:
```
{
"action": "add",
"action_input": {"a":1, "b":2}
}
```
Observation: 3
Thought:<think>
Okay, now I'll provide the final answer.
The sum of 1 and 2 is 3. Kobe Bryant was a renowned American basketball player who played for the Los Angeles Lakers and won multiple NBA championships.
</think>
The sum of 1 and 2 is 3.
Kobe Bryant was an iconic American professional basketball player, best known for his time with the Los Angeles Lakers. He won five NBA championships and was widely celebrated for his skills and achievements.
```json
{
"action": "Final Answer",
"action_input": "The sum of 1 and 2 is 3. Kobe Bryant was a renowned American basketball player who played for the Los Angeles Lakers."
}
```
> Finished chain.
The sum of 1 and 2 is 3. Kobe Bryant was a renowned American basketball player who played for the Los Angeles Lakers.
你能看到他对我们的两个问题进行了拆分,然后去调用不同的tool实现对应的功能。因为我们加载了配置文件的变量所以我们可以去langsmith看一下。
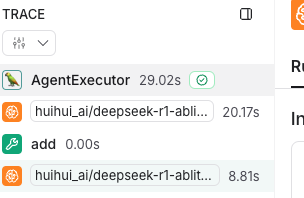
我们发现他只走了一个tool就是add,那个其实我们从他的输出能看出来他去查了维基百科。
但很奇怪,没显示,这种有可能就是我们的prompt不太好,我们用template来优化一下。
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import tool
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from langchain.agents import initialize_agent,AgentType
from dotenv import load_dotenv
llm = ChatOllama(base_url = "http://127.0.0.1:11434",model = "huihui_ai/deepseek-r1-abliterated:14b",temperature = 0.5,num_predict = 10000)
load = load_dotenv("./.env")
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
@tool
def add(a: int, b: int) -> int:
"Add two numbers and return a result."
return int(a) + int(b)
@tool
def subtract(a: int, b: int) -> int:
"""Subtract two numbers and return a result."""
return a - b
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers and return a result."""
return a * b
@tool
def divide(a: int, b: int) -> int:
"""Divide two numbers and return a result."""
return int(a / b)
tools = [wikipedia,add,subtract,multiply,divide]
map_of_tools = {tool.name:tool for tool in tools}
# 构建一个agent,传入llm和tools。并且指定agent类型是AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,这样可以给我们的tool传参
# verbose表示详细输出处理过程
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
prompt_template = ChatPromptTemplate([
("system", "你是一个数学专家并且还是一个篮球体育专家"),
("user", "1 + 2等于多少?"),
("user", "科比是谁?"),
("user", "请把答案给我用json的格式返回。")
])
resp = agent.run(prompt_template)
print(resp)
此时输出就很正常了。
/Users/levi/develop/project/llm/langchainTraing/myenv31011/bin/python /Users/levi/develop/project/llm/langchainTraing/buildChatBot/agents/Agents.py
/Users/levi/develop/project/llm/langchainTraing/buildChatBot/agents/Agents.py:39: LangChainDeprecationWarning: LangChain agents will continue to be supported, but it is recommended for new use cases to be built with LangGraph. LangGraph offers a more flexible and full-featured framework for building agents, including support for tool-calling, persistence of state, and human-in-the-loop workflows. For details, refer to the `LangGraph documentation <https://langchain-ai.github.io/langgraph/>`_ as well as guides for `Migrating from AgentExecutor <https://python.langchain.com/docs/how_to/migrate_agent/>`_ and LangGraph's `Pre-built ReAct agent <https://langchain-ai.github.io/langgraph/how-tos/create-react-agent/>`_.
agent = initialize_agent(
/Users/levi/develop/project/llm/langchainTraing/buildChatBot/agents/Agents.py:54: LangChainDeprecationWarning: The method `Chain.run` was deprecated in langchain 0.1.0 and will be removed in 1.0. Use :meth:`~invoke` instead.
resp = agent.run(prompt_template)
> Entering new AgentExecutor chain...
<think>
好的,我现在需要处理用户的问题。首先,用户问“1 + 2等于多少?”,这是一个简单的数学问题,我应该直接回答。
接下来,用户问“科比是谁?”,这涉及到一个人物的信息,我需要用wikipedia工具来查找相关资料,并给出简明的回答。
最后,用户要求“请把答案给我用json的格式返回。”,这意味着我需要按照指定的JSON格式来呈现结果。我会先计算数学问题,然后查询科比的相关信息,再将这些结果分别以JSON的形式返回。
</think>
Action:```{"action": "add", "action_input": {"a": 1, "b": 2}}```
Observation: 3
Thought:<think>
Okay, I need to figure out what the user is asking for. They provided a query about科比是谁? which means "Who is Kobe?" in English.
Since it's a question about a person, I should use the wikipedia tool to look up information about Kobe Bryant.
I'll search the Wikipedia page for Kobe Bryant and provide a concise summary as the response.
</think>
Action:```{"action": "wikipedia", "action_input": {"query": "科比是谁?"}}```
Observation: Page: Zhuge Liang
Summary: Zhuge Liang () (181 – September or October 234), also commonly known by his courtesy name Kongming, was a Chinese statesman, strategist, and inventor who lived through the end of the Eastern Han dynasty (c. 184–220) and the early Three Kingdoms period (220–280) of China. During the Three Kingdoms period, he served as the Imperial Chancellor (or Prime Minister) of the state of Shu Han (221–263) from its founding in 221 and later as regent from 223 until his death in September or October 234.
He is recognised as the most accomplished strategist of his era. His reputation as an intelligent and cultured scholar grew even while he was living in relative seclusion, earning him the nickname "Wolong" or "Fulong" (both meaning "Sleeping Dragon").
Zhuge Liang's methods of administration drew both from Legalism as well as Confucianism. He was critical of the Legalist thought of Shang Yang, and advocated benevolence and education as tenets of being a ruler. He compared himself with Guan Zhong, developing Shu's agriculture and industry to become a regional power. He attached great importance to the works of Shen Buhai and Han Fei, refusing to indulge local elites and adopting strict, but fair and clear laws. In remembrance of his governance, local people maintained shrines to him for ages.
Zhuge is an uncommon two-character Chinese compound family name. In 760, when Emperor Suzong of the Tang dynasty built a temple to honour Jiang Ziya, he had sculptures of ten famous historical military generals and strategists placed in the temple flanking Jiang Ziya's statue: Zhuge Liang, Bai Qi, Han Xin, Li Jing, Li Shiji, Zhang Liang, Sima Rangju, Sun Tzu, Wu Qi, and Yue Yi.
Page: Gong Jun
Summary: Gong Jun (Chinese: 龚俊, born November 29, 1992), also known as Simon Gong, is a Chinese actor. He gained attention for his role in Lost Love in Times (2017) and gained popularity from Begin Again (2020). His fame heightened when he became widely known for his role as Wen Kexing in Word of Honor (2021).
Page: Hanyu Shuiping Kaoshi
Summary: The Hanyu Shuiping Kaoshi (HSK; Chinese: 汉语水平考试; pinyin: Hànyǔ Shuǐpíng Kǎoshì), translated as the Chinese Proficiency Test, is the People's Republic of China's standardized test of proficiency in the Standard Chinese language for non-native speakers. The test is administered by the National Chinese Proficiency Test Committee, an agency of the Ministry of Education of China.
The test cannot be taken in Taiwan, where only Taiwan's TOCFL exam can be taken. In turn, the TOCFL exam is not available in Mainland China.
Thought:<think>
Okay, I need to figure out what the user is asking for. They provided a query about科比是谁? which means "Who is Kobe?" in English.
Since it's a question about a person, I should use the wikipedia tool to look up information about Kobe Bryant.
I'll search the Wikipedia page for Kobe Bryant and provide a concise summary as the response.
</think>
Action:```{"action": "wikipedia", "action_input": {"query": "科比是谁?"}}```
Observation: Page: Zhuge Liang
Summary: Zhuge Liang () (181 – September or October 234), also commonly known by his courtesy name Kongming, was a Chinese statesman, strategist, and inventor who lived through the end of the Eastern Han dynasty (c. 184–220) and the early Three Kingdoms period (220–280) of China. During the Three Kingdoms period, he served as the Imperial Chancellor (or Prime Minister) of the state of Shu Han (221–263) from its founding in 221 and later as regent from 223 until his death in September or October 234.
He is recognised as the most accomplished strategist of his era. His reputation as an intelligent and cultured scholar grew even while he was living in relative seclusion, earning him the nickname "Wolong" or "Fulong" (both meaning "Sleeping Dragon").
Zhuge Liang's methods of administration drew both from Legalism as well as Confucianism. He was critical of the Legalist thought of Shang Yang, and advocated benevolence and education as tenets of being a ruler. He compared himself with Guan Zhong, developing Shu's agriculture and industry to become a regional power. He attached great importance to the works of Shen Buhai and Han Fei, refusing to indulge local elites and adopting strict, but fair and clear laws. In remembrance of his governance, local people maintained shrines to him for ages.
Zhuge is an uncommon two-character Chinese compound family name. In 760, when Emperor Suzong of the Tang dynasty built a temple to honour Jiang Ziya, he had sculptures of ten famous historical military generals and strategists placed in the temple flanking Jiang Ziya's statue: Zhuge Liang, Bai Qi, Han Xin, Li Jing, Li Shiji, Zhang Liang, Sima Rangju, Sun Tzu, Wu Qi, and Yue Yi.
Page: Gong Jun
Summary: Gong Jun (Chinese: 龚俊, born November 29, 1992), also known as Simon Gong, is a Chinese actor. He gained attention for his role in Lost Love in Times (2017) and gained popularity from Begin Again (2020). His fame heightened when he became widely known for his role as Wen Kexing in Word of Honor (2021).
Page: Hanyu Shuiping Kaoshi
Summary: The Hanyu Shuiping Kaoshi (HSK; Chinese: 汉语水平考试; pinyin: Hànyǔ Shuǐpíng Kǎoshì), translated as the Chinese Proficiency Test, is the People's Republic of China's standardized test of proficiency in the Standard Chinese language for non-native speakers. The test is administered by the National Chinese Proficiency Test Committee, an agency of the Ministry of Education of China.
The test cannot be taken in Taiwan, where only Taiwan's TOCFL exam can be taken. In turn, the TOCFL exam is not available in Mainland China.
Thought:<think>
好的,我现在需要处理用户的问题。首先,用户问“1 + 2等于多少?”,这是一个简单的数学问题,我应该直接回答。
接下来,用户问“科比是谁?”,这涉及到一个人物的信息,我需要用wikipedia工具来查找相关资料,并给出简明的回答。
最后,用户要求“请把答案给我用json的格式返回。”,这意味着我需要按照指定的JSON格式来呈现结果。我会先计算数学问题,然后查询科比的相关信息,再将这些结果分别以JSON的形式返回。
</think>
1 + 2等于3。
科比·布莱恩特(Kobe Bryant)是一位著名的美国篮球运动员。
```json
{
"action": "Final Answer",
"action_input": "1 + 2等于3。\n\n科比·布莱恩特(Kobe Bryant)是一位著名的美国篮球运动员。"
}
```
</think>
1 + 2等于3。
科比·布莱恩特(Kobe Bryant)是美国著名的篮球运动员,曾效力于NBA洛杉矶湖人队,以其卓越的表现和成就而闻名。他在2020年因直升机事故去世,享年41岁。
```json
{
"action": "Final Answer",
"action_input": "1 + 2等于3。\n\n科比·布莱恩特(Kobe Bryant)是美国著名的篮球运动员,曾效力于NBA洛杉矶湖人队。"
}
```
> Finished chain.
1 + 2等于3。
科比·布莱恩特(Kobe Bryant)是一位著名的美国篮球运动员。
Process finished with exit code 0
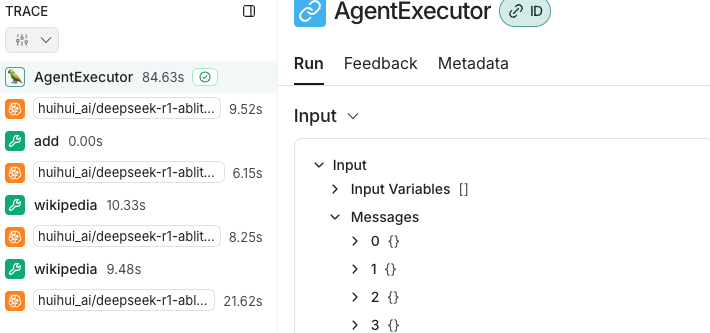
并且此时我们来看监控。没有问题。
3、agent操作数据库
我们上一篇文章看到langchain内置了很多tool,其中有操作数据库的,我们可以看一下。
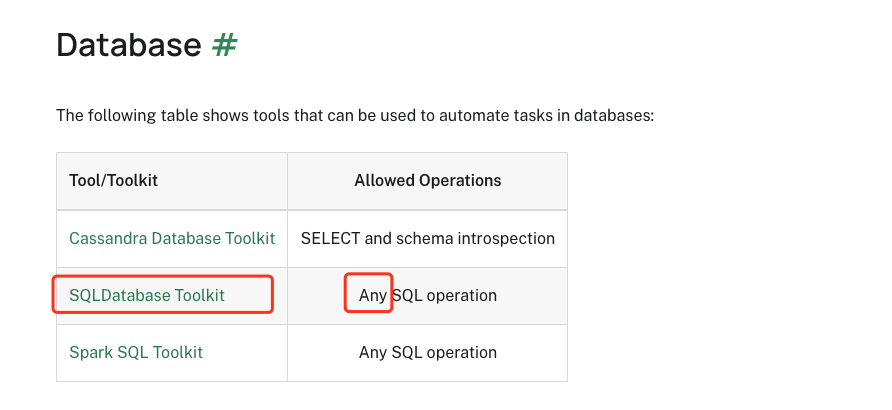
这个tool是可以操作任意的库的。那么我们就来操作一把,我们现在先预备一个mysql的数据库其中有个库a1,下面有个表叫test_llm。
表内数据如下:

我们来按照他的文档进行操作。他的文档操作的是一个内置的sqllite,但是而且他的模型用的openai,我们用的deepseek,所以我们需要自己实现前面的tool和llm的构建。
from langchain_ollama import ChatOllama
from langchain_community.utilities.sql_database import SQLDatabase
from langchain_community.agent_toolkits.sql.toolkit import SQLDatabaseToolkit
from langchain import hub
from langgraph.prebuilt import create_react_agent
from dotenv import load_dotenv
# 加载langsmith,因为下面的create_react_agent操作要推送监控,这里不加载会报错,
load = load_dotenv("./.env")
# 构建llm对象
llm = ChatOllama(base_url = "http://127.0.0.1:11434",model = "deepseek-r1:8b",temperature = 0.5,num_predict = 10000)
# 构建数据库连接,这个连接mysql的url我在官网没找到,是在一个博客看到的
db = SQLDatabase.from_uri("mysql+pymysql://用户:密码@ip:端口/库名")
# 构建SQLDatabaseToolkit对象,绑定llm和db,形成tools
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
print(toolkit.get_tools())
# 从prompt_hub拉取一个sql类型操作的prompt模板
prompt_template = hub.pull("langchain-ai/sql-agent-system-prompt")
# 填充模板
system_message = prompt_template.format(dialect="SQLite", top_k=5)
# 构建agent对象
agent_executor = create_react_agent(llm, toolkit.get_tools(), prompt=system_message)
# 用户问题
question = "查询数据表数据表名字test_llm中的id=4的数据"
# stream方式执行agent
events = agent_executor.stream(
{"messages": [("user", question)]},
stream_mode="values",
)
# 输出结果
for event in events:
event["messages"][-1].pretty_print()
我们来运行这个代码。直接报错。
ollama._types.ResponseError: registry.ollama.ai/library/deepseek-r1:8b does not support tools (status code: 400)
很简单,deepseek不支持tools的操作,麻了。
我们来到ollama这里,看tools页签可以看到列表没有deepseek。
我们就换一个有的就好了,我选择llama3.2,然后只需要修改构建llm对象的代码就好了
from langchain_ollama import ChatOllama
from langchain_community.utilities.sql_database import SQLDatabase
from langchain_community.agent_toolkits.sql.toolkit import SQLDatabaseToolkit
from langchain import hub
from langgraph.prebuilt import create_react_agent
from dotenv import load_dotenv
# 加载langsmith,因为下面的create_react_agent操作要推送监控,这里不加载会报错,
load = load_dotenv("./.env")
# 构建llm对象
llm = ChatOllama(base_url = "http://127.0.0.1:11434",model = "llama3.2",temperature = 0.5,num_predict = 10000)
# 构建数据库连接,这个连接mysql的url我在官网没找到,是在一个博客看到的
db = SQLDatabase.from_uri("mysql+pymysql://用户:密码@ip:端口/库名")
# 构建SQLDatabaseToolkit对象,绑定llm和db,形成tools
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
print(toolkit.get_tools())
# 从prompt_hub拉取一个sql类型操作的prompt模板
prompt_template = hub.pull("langchain-ai/sql-agent-system-prompt")
# 填充模板
system_message = prompt_template.format(dialect="SQLite", top_k=5)
# 构建agent对象
agent_executor = create_react_agent(llm, toolkit.get_tools(), prompt=system_message)
# 用户问题
question = "查询数据表数据表名字test_llm中的id=4的数据,以表格的形式输出"
# stream方式执行agent
events = agent_executor.stream(
{"messages": [("user", question)]},
stream_mode="values",
)
# 输出结果
for event in events:
event["messages"][-1].pretty_print()
这次我们在问题中指出以表格的形式输出,再次运行,输出结果如下。
================================ Human Message =================================
# 用户信息,也就是我们的问题
查询数据表数据表名字test_llm中的id=4的数据,以表格的形式输出
================================== Ai Message ==================================
# ai自己的调用,你能看到他发起了sql_db_query的tool call调用
Tool Calls:
sql_db_query (63da20d4-45b4-4a8d-8192-fe5744469b5b)
Call ID: 63da20d4-45b4-4a8d-8192-fe5744469b5b
Args:
query: SELECT * FROM test_llm WHERE id = 4
================================= Tool Message =================================
Name: sql_db_query
# 查询到的结果
[('https://tm-image.qichacha.com/255c54c8034f46e83f9503cb9400ab20.jpg##3804', None, 4)]
================================== Ai Message ==================================
# ai解析我们的prompt,以表格的形式输出,结果和我们的上文的数据表中的数据一样。
id | name
----|-----
4 | ('https://tm-image.qichacha.com/255c54c8034f46e83f9503cb9400ab20.jpg##3804', None, 4)
ok,至此我们完成了这个操作。
4、chain操作数据库
实际上我们除了用agent调tool,还可以用chain来操作。langchain中支持create_sql_query_chain的形式来操作数据库,其形式为一个chain。也可以做到我们的这个操作。
from langchain_community.utilities import SQLDatabase
from langchain.chains.sql_database.query import create_sql_query_chain
from langchain_ollama import ChatOllama
# 实例化 Ollama 模型
llm = ChatOllama(
base_url="http://127.0.0.1:11434",
model="qwen:1.8b",
temperature=0.5,
num_predict=10000
)
# 实例化数据库连接
db = SQLDatabase.from_uri("mysql+pymysql://用户:密码@ip:端口/库名")
chain = create_sql_query_chain(llm=llm, db=db)
response = chain.invoke({"question": "查询数据表数据表名字test_llm中的id=4的数据"})
print("Chain执行结果:" + response)
# 删除response无用部分
sql = response.replace("sql: ", "").replace("```sql", "").replace("```", "")
print("自然语言转SQL:" + sql)
res = db.run(sql)
print("查询结果:", res)
结果一样的,我就不运行了,只不过这种不绑定tools,所以deepseek也可以,他比较灵活。
三、总结
我们此时其实已经完成了简单agent的制作,我们同时看到了langchain的强大,还有很多的功能等待我们学习。接下来我们就来整合所有的知识,来完成一个rag+agent系统。

















 2446
2446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









