




一、简介
我们在使用各种大模型产品的时候,我们作为用户其实能做的不多。只是构建一个合理的输入这样就没了。
更多的是交给大模型端来处理,那么我们这个系列其实是针对大模型之上,用户之下构建的定位。我们需要在这里做更多的东西来让大模型和用户之间交流的更加顺畅。其中有一个非常重要的点就是上下文的记忆。
如果我们没有上下文记忆,那我们使用大模型就和传统搜索引擎没有任何区别,永远局限于当前交流,这种无疑问是不合理的。所以我们需要构建用户交流的上下文,交给大模型然后使得他拥有记忆能力。这样可以在一个比较好的上下文中做交流,让大模型知道我们在交流什么,不会产生问答的割裂感,才会有一种我们在和人工智能交流的感觉。
比较幸运的是langchain提供了一些实现来帮助我们构建这种需求。这就是Message History,当我们每次继续交流的时候,我们会提供上下文给大模型,这样他可以知道我们的交流内容。于是我们的架构图就变成了这样。
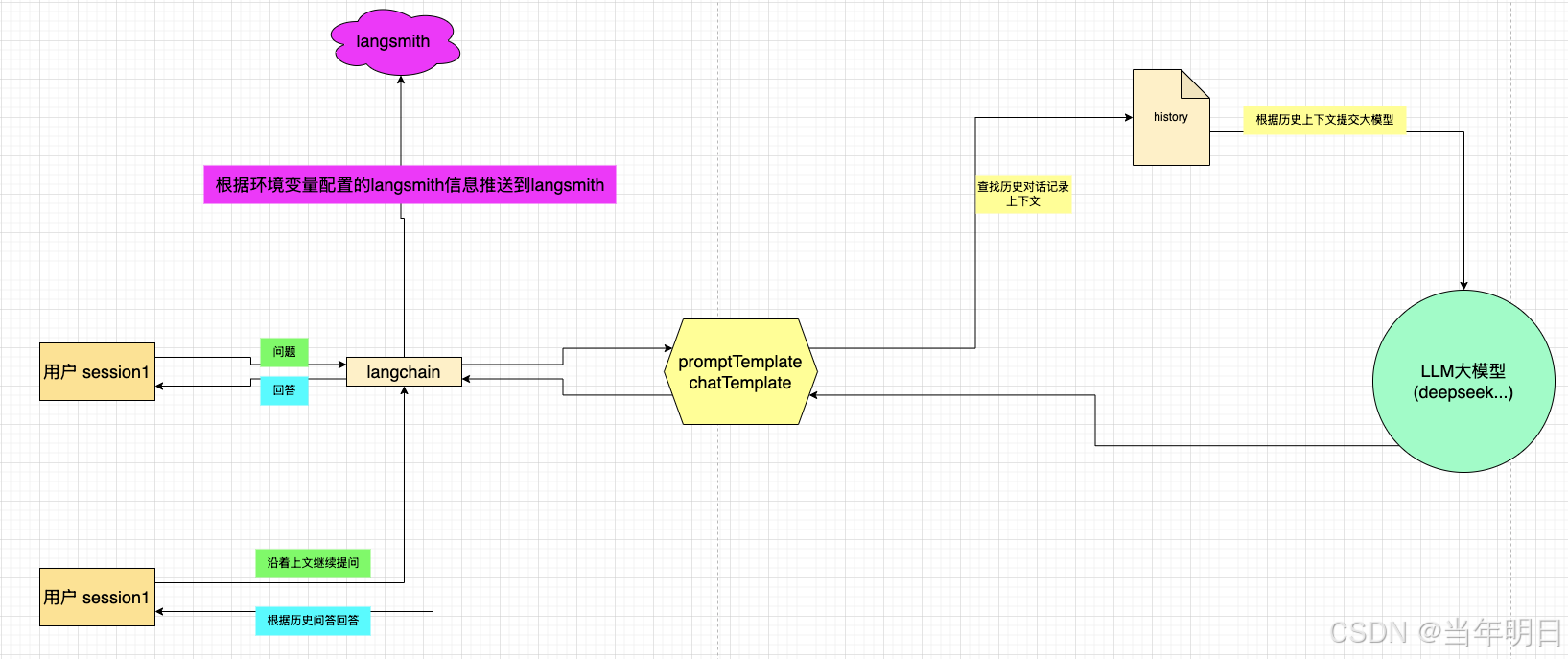
只要你是一个session,也就是说你们处于一个对话上下文中的时候他会获取这一个对话窗口的多轮对话记录,从而得知你们交流的内容,做出合理的回复。
当然你开启新的session,也就是新的对话窗口,此时就是新的上下文了,之前的记录也就不生效了。
二、RunnableWithMessageHistory
我们这次这个功能的实现主要使用到的是RunnableWithMessageHistory
以及一个langchain_community这个包,这个包不是标准库里面的,需要我们额外安装一下。
我们在jupyter上执行一下下面这句代码。安装成功之后我们就可以开始开发了。
!pip install langchain_community
ok,一切准备好之后我们就开始先看一下这个类。
管理另一个 Runnable 的聊天消息历史记录。
聊天消息历史记录是表示对话的消息序列。
RunnableWithMessageHistory 包装另一个 Runnable 并为其管理聊天消息历史记录;它负责读取和更新聊天消息历史记录。
包装的 Runnable 的输入和输出支持的格式如下所述。
RunnableWithMessageHistory 必须始终使用包含聊天消息历史记录工厂的相应参数的配置来调用。
默认情况下,Runnable 应采用一个名为 session_id 的配置参数,它是一个字符串。此参数用于创建与给定 session_id 匹配的新聊天消息历史记录或查找现有聊天消息历史记录。
我们其实可以看到,他本身就是一个实现了Runnable接口的类,所以他也是一个Runnable,我们前面所有的关于Runnable的操作这里都还能用。
其次我们看到他是管理历史记录的,包括读取和更新。
并且他的参数是一个Runnable,这个正常他要把我们要执行的业务(Runnable)包装进去,并且传入一个session_id来区分是不是同一个对话上下文。这个我们基本都能理解到。
于是我们来第一次编码。
1、内存记忆上下文
我们按照官方文档来实现一下。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import chain
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
# 定义一个ChatPromptTemplate,prompt就是你的当前问题输入占位符,history就是将来我们把历史上下文的占位符,之后langchain会把上下文信息传递到这里来填充模板
template = ChatPromptTemplate.from_messages([
('human',"{prompt}"),
('placeholder',"{history}")
])
# 构建一个chain
chain = template | llm | StrOutputParser()
# 做一个内存的缓存,避免多次创建ChatMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 构建RunnableWithMessageHistory,传入参数,交给langchain来管理
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="prompt",
history_messages_key="history",
)
# 构建session id
session_id = "levi22"
# 可以选择每次执行前是不是清除历史的上下文信息
#get_session_history(session_id).clear()
# langchain执行,把当前的问题和session_id传进去。langchian去填充构建
resp1 = chain_with_history.invoke(
{"prompt": "百度是一个什么东西呢?输出不要think过程"},
config={"configurable": {"session_id": session_id}}
)
# 用相同的session_id来执行第二个问题,保持上下文效果
resp2 = chain_with_history.invoke(
{"prompt": "和谷歌对比一下呢?输出不要think过程"},
config={"configurable": {"session_id": session_id}}
)
print(resp1)
print("****************************")
print(resp2)
输出如下:
百度是中国的一家知名搜索引擎公司。它于2000年1月在中国大陆成立,主要提供搜索服务,并为用户提供各种在线服务,如网页搜索、图像搜索、视频搜索等。
****************************
百度也是中国最大的搜索引擎之一,仅次于谷歌。
以下是百度和谷歌的比较:
**搜索功能**
* 百度:支持中文和英文搜索,能够提供更准确的结果。
*谷歌:支持多种语言的搜索,能够提供更广泛的内容。
**用户体验**
* 百度:用户界面简洁、易用,能够快速找到所需信息。
*谷歌:用户界面更加复杂,需要更多的操作来找到所需信息。
**在线服务**
* 百度:提供各种在线服务,如网页搜索、图像搜索、视频搜索等。
*谷歌:提供多种在线服务,如Google Maps、Google Drive、Google Docs等。
**市场份额**
*百度:占据了中国大陆的主要搜索引擎市场份额。
*谷歌:占据了全球的主要搜索引擎市场份额。
总之,百度和谷歌都是非常好的搜索引擎公司,它们各有其强项和弱点。
我们看到上下文还是有作用的。起码他能记住我们的上下文来回答。
2、记忆上下文存储Elasticsearch
我们上面的上下文是存储在内存中的,重启或者其他操作可能会导致丢失,一般生产我们都是存储在数据库中。langchain-community为我们提供了多种数据库存储的交互实现可以看一下。langchain-community
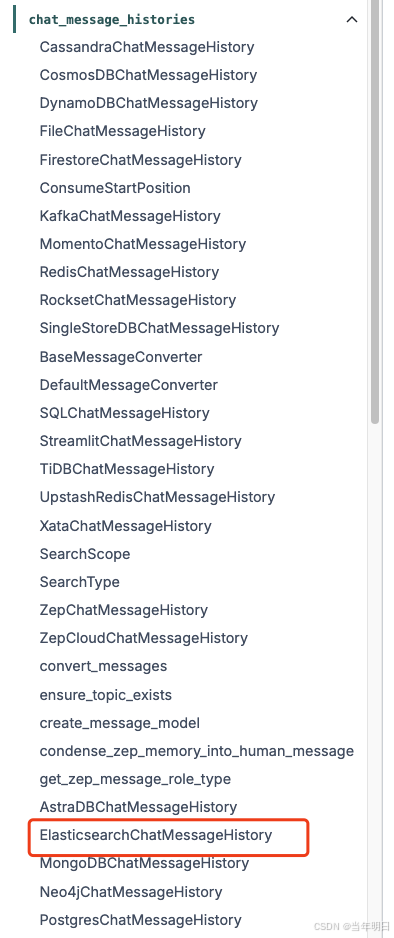
因为后面我们会使用Elasticsearch向量数据库来实现rag,所以我们在众多的存储中选择了Elasticsearch。至于如何启动一个es这个我就不说了,前面其实我写过。我选择的es版本是8.8.0,启动好es和kibana之后我们来编写代码。
2.1、安装python环境es的依赖
在jupyter中执行,我多说一嘴,如果你不用jupyter,你要在打包的时候安装,这就是python的包管理,这个网上资料很多。
!pip install elasticsearch
如果不安装,后面会报错。
2.2、代码实现
代码实现可以参考官方文档
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import chain
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ElasticsearchChatMessageHistory
# 无密码的elasticsearch配置
es_url = "http://localhost:9200"
# 存储的索引,我们不用预先创建索引,因为说实话我也不知道字段,langchain会创建,并且自动映射字段
index_name = "chat_history"
session_id = "levi"
template = ChatPromptTemplate.from_messages([
('human',"{prompt}"),
('placeholder',"{history}")
])
chain = template | llm | StrOutputParser()
# 构建ElasticsearchChatMessageHistory
def get_session_history(session_id: str) :
return ElasticsearchChatMessageHistory(
index=index_name,
session_id=session_id,
es_url=es_url
)
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="prompt",
history_messages_key="history",
)
resp1 = chain_with_history.invoke(
{"prompt": "百度是一个什么东西呢?输出不要think过程"},
config={"configurable": {"session_id": session_id}}
)
resp2 = chain_with_history.invoke(
{"prompt": "和谷歌对比一下呢?输出不要think过程"},
config={"configurable": {"session_id": session_id}}
)
print(resp1)
print("****************************")
print(resp2)
输出结果如下:
百度是中国的一家知名.search引擎公司,成立于2000年。它的主要业务包括搜索引擎、在线广告、数据分析等。
****************************
百度的搜索引擎被认为是中国最受欢迎的搜索引擎之一,提供了快速、高效的搜索体验。
与谷歌相比,百度的优势在于其能够更好地理解中文搜索需求,并为中文用户提供了高质量的搜索结果。同时,百度也积极推进自己的一些创新技术,如AI等。
也是有上下文关系的,没毛病。
然后我们再来看es中的情况。我们直接查看索引中的数据:
GET chat_history/_search

首先,索引建立了,数据也存进去了,只不过,上下文信息被存储为加密文,我勒个dj。而且我没发现他有明文存储的参数,这个就坑爹了。你加密之后我怎么发挥es的全文检索呢,难不成当我是火星人。没办法我们来看下源码
我们来看一下ElasticsearchChatMessageHistory的构造函数,应该存在可以配置的东西。
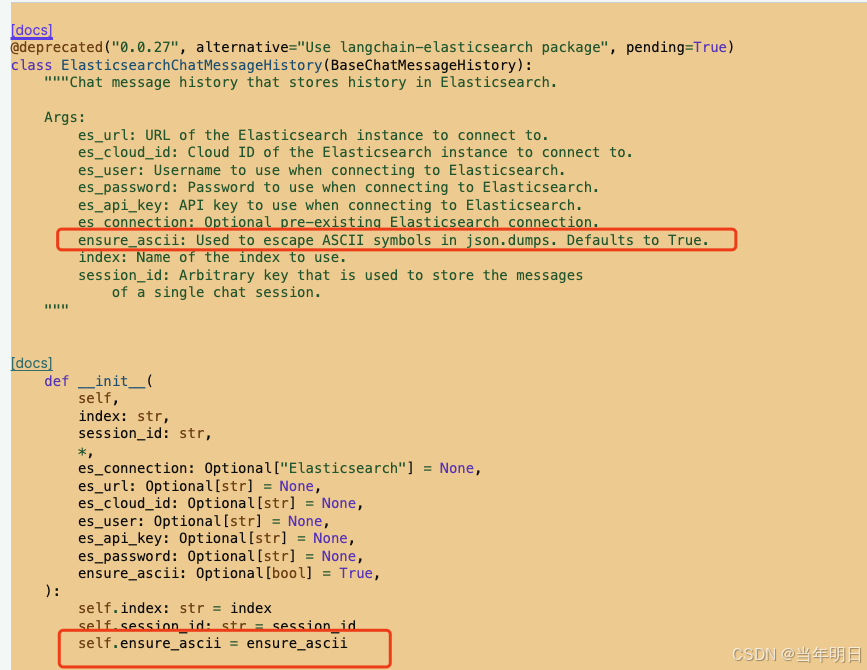
他有一个ensure_ascii默认是true,也就是说他默认存es是ascii编码之后的,你要是想读取,可以从es里取出来对ascii做解密。但是我不想那么麻烦,我想直接存进去的就是unicode的汉字类型。那我就要把这个参数设置为False(py中的布尔类型首字母大写)。
为此我们需要改造构造方法。
# 构建ElasticsearchChatMessageHistory
def get_session_history(session_id: str) :
elasticsearchChatMessageHistory = ElasticsearchChatMessageHistory(
index=index_name,
session_id=session_id,
es_url=es_url,
# 设置不存ascii编码的内容
ensure_ascii=False
)
# 设置不存ascii编码的内容
# elasticsearchChatMessageHistory.ensure_ascii = False
return elasticsearchChatMessageHistory
ok,此时再执行,然后查看es,一切正常了。

我们来审视一下这个上下文到底存的是啥,你会发现他把你的问题以及模型的输入作为一条一条数据存进去了,然后下次构建上下文的时候他把这些数据都组合起来发给大模型,这就是多轮对话,每次都把历史数据整一起发给大模型,让大模型去处理,这就是精髓,难不成你以为还有什么高深的吗?理论上轮数越多,发的历史就越多,也会处理的越慢,不过现在模型都很厉害,这种差距应该看不出来,而且估计还有别的机制,我们就不去探索LLM那一层了。做好rag和agent就好了。
至此我们其实完成了大模型多轮对话的一个功能,后面再我们构建rag的时候这个必不可少。我们即将开始正式构建应用,各位乘客,坐稳发车了,我们下期见。

















 132
132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









