




一、简介
之前我们用langchain来操作本地部署的模型做了一些工作。我们今天就操作一下openai的接口,全面了解一下具体的运作方式。
二、官方配置
1、Api Key
我们首先来登陆openai的开发者平台,这里可以为我们创建账号的api-key和一些开发文档的提供。
如果你没有登陆过,你需要用你的谷歌或者其他账户登陆一下。这里我已经登陆进来了。
我们直接点击首页的设置进入操作页面。
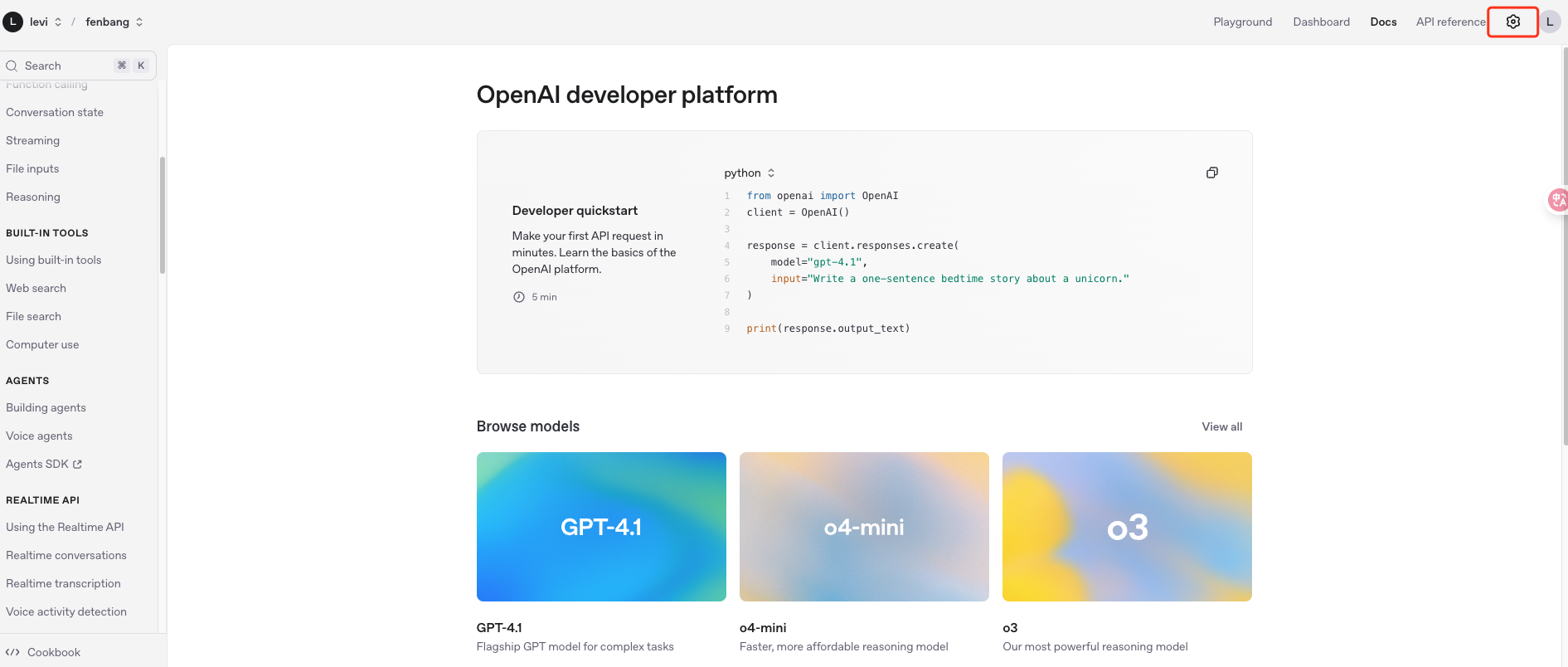
紧接着你可以来到Api keys选项这里设置你账户的Api key。记住,创建之后记得保存出来,不然后面你就看不到了。我这里创建了两个,其实有一个没用,你自己看吧。
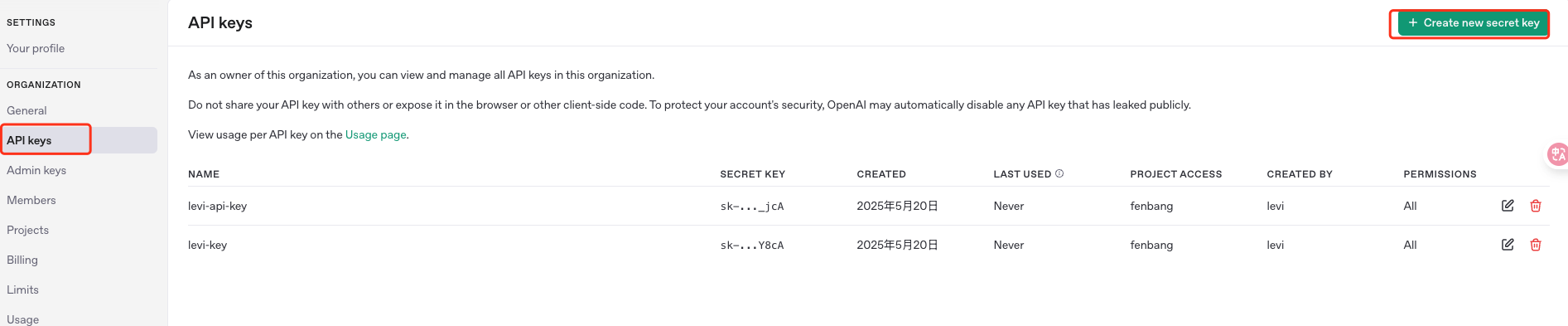
此时我们就完成了创建api key的操作。
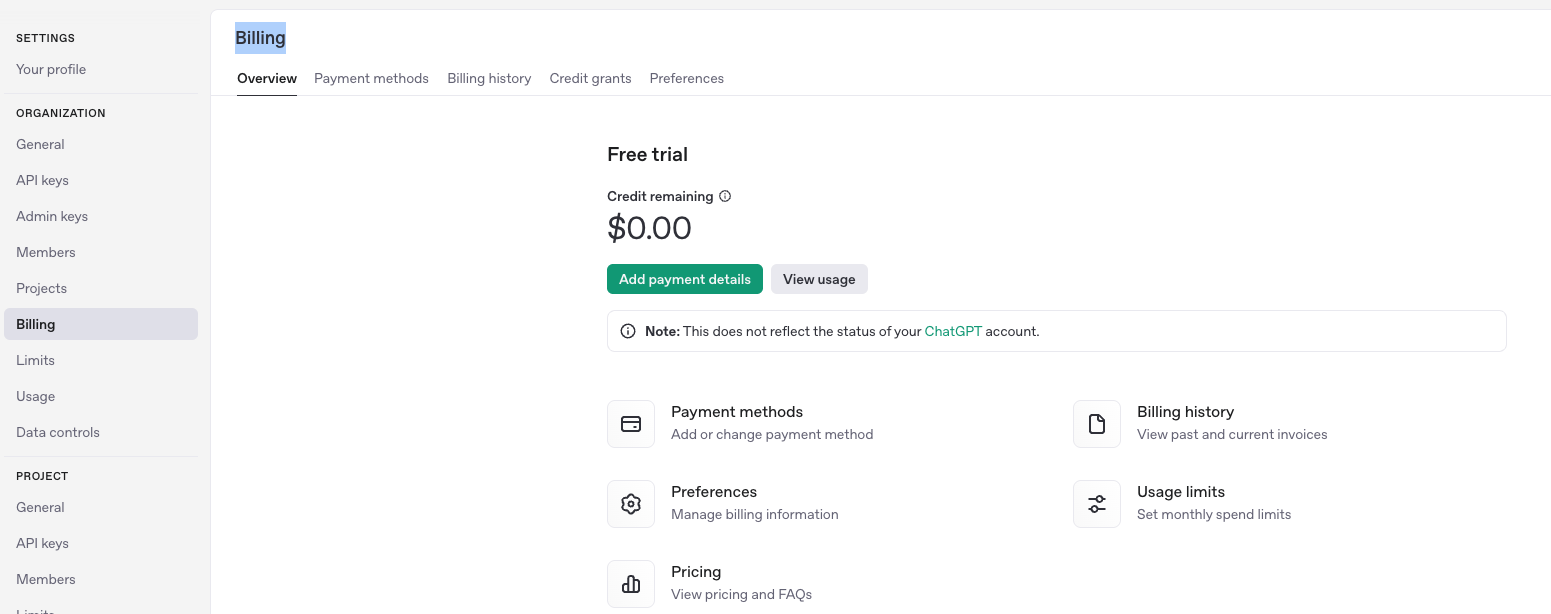
其实这里还有很多其他的操作可以让你选择,比如Billing这个选项可以对一些OpenAi的模型进行付费。我们看到这里默认是0,所以无需付费,可能有些比较强的模型需要付费吧。
2、Api文档
我们接下来都将基于OpenAi的官方api文档进行开发。
这个文档列出了open ai所有的能够交互的api,我们先不一点一点过,我们直接找到我们最关心的一个内容,聊天chat功能
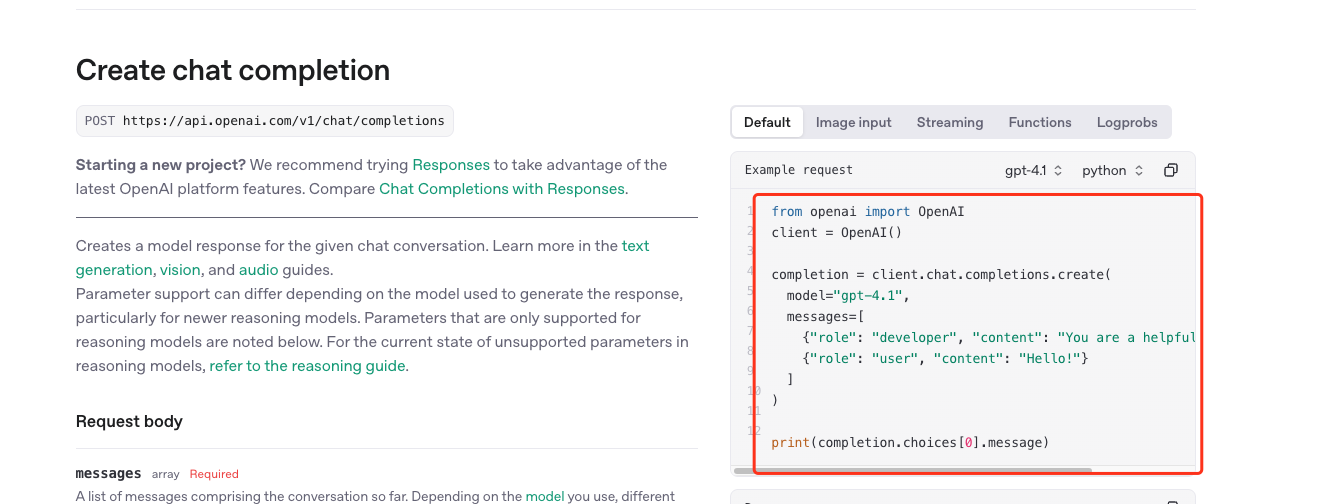
这里有很简单的入门代码,我们可以看一下,运行起来先。
这里他有个问题就是这个案例代码没有加载api key,我们需要创建一个.env文件(名字必须是.env)。然后把我们刚才在开发者平台上设置的api key配置进去。
OPENAI_API_KEY="sk-proj-***"
然后我们运行代码
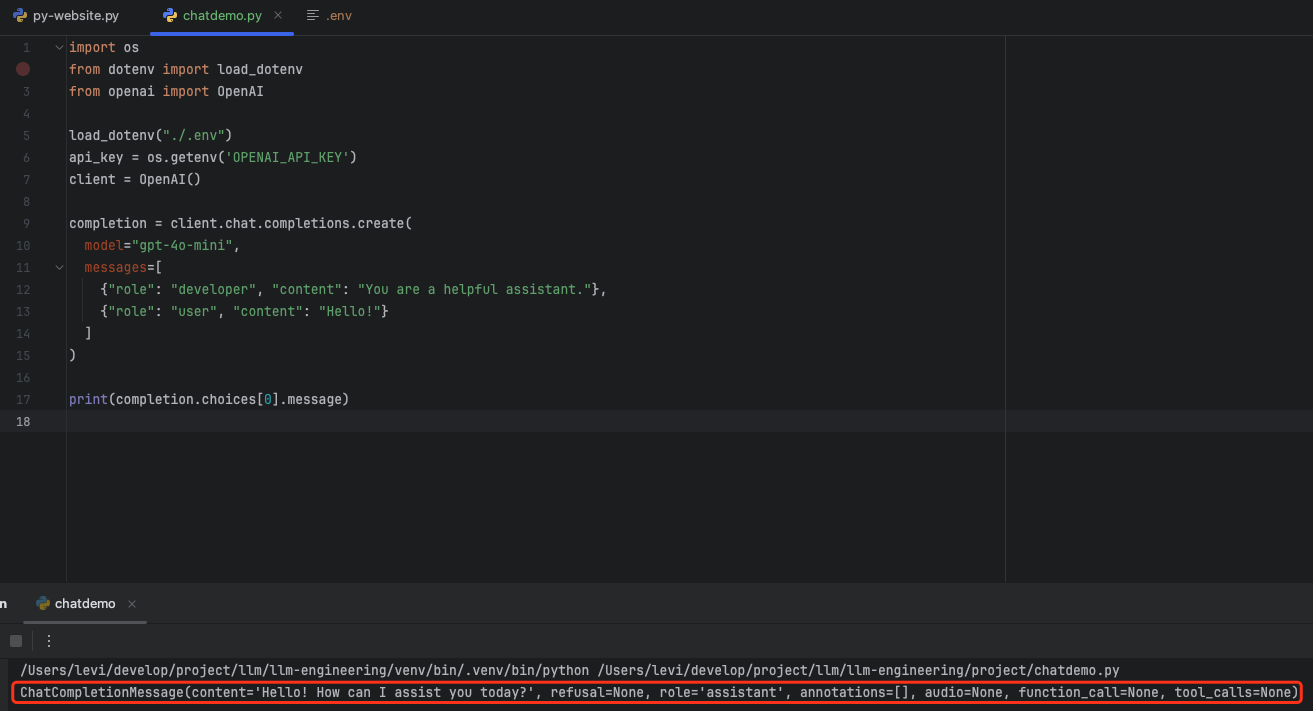
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv("./.env")
api_key = os.getenv('OPENAI_API_KEY')
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
打印出来了prompt的message信息。这就是openapi的运行模式,我们先简单了解一下他的启动方式。后面我们逐步完成一些功能。其实你会发现他和langchain有很多地方很相似。
三、代码实现
基于以上的一些功能调用方式,我们可以来实现一些规范化的代码。我们基于openai的接口来实现如何爬取一个网站的信息,代码如下。
Utils.py 工具类的封装,
import os
from dotenv import load_dotenv
from openai import OpenAI
class OpenAiUtil:
def __init__(self, data):
self.data = data
# 构建一个open ai的客户端
@staticmethod
def buildOpenAiClient() -> OpenAI:
load_dotenv("./.env")
api_key = os.getenv('OPENAI_API_KEY')
if not api_key:
print("api-key 未发现设置!")
elif not api_key.startswith("sk-proj-"):
print("api-key 有问题")
else:
print("ok,api-key没问题了")
return OpenAI()
Website.py 网站读取
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
# 封装对于网站获取的类,使用requests包来处理
class Website:
def __init__(self, url):
"""
初始化一个操作对象
"""
self.url = url
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
self.title = soup.title.string if soup.title else "No title found"
for irrelevant in soup.body(["script", "style", "img", "input"]):
irrelevant.decompose()
self.text = soup.body.get_text(separator="\n", strip=True)
py-website.py 调用llm 开始读取输出
from IPython.display import display
from Utils import OpenAiUtil
from Website import Website
# 加载openAi客户端
openai = OpenAiUtil.buildOpenAiClient()
# 定义prompt
system_prompt = "你是一个分析网站内容并提供简短摘要的助手,并且你在总结的时候会忽略可能与导航相关的文本。"
def user_prompt_for(website):
return f"你正在查看一个名为“{website.title}”的网站。该网站的内容如下{website.text},请提供这个网站的简短摘要,使用 Markdown 格式。如果包含新闻或公告,请一并总结。"
# 构建message prompt
def messages_for(website):
return [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt_for(website)}
]
# 发起llm call
def summarize(url):
website = Website(url)
response = openai.chat.completions.create(model = "gpt-4o-mini",messages = messages_for(website))
return response.choices[0].message.content
# 输出最终结果
def display_summary(url):
summary = summarize(url)
display(summary)
# call 我们来爬取一个java nio的网址
display_summary("https://jenkov.com/tutorials/java-nio/index.html")
我们爬了java nio的一个学习网址,内容如下。

然后我们来看我们的输出。一切正常。ok,到此为止我们就完成了初步的工作。


















 2381
2381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









