



 本文探讨中国数据库市场现状,分析国内外数据库软件竞争格局,强调国产数据库发展机遇与挑战,提及云数据库趋势。
本文探讨中国数据库市场现状,分析国内外数据库软件竞争格局,强调国产数据库发展机遇与挑战,提及云数据库趋势。
guo'chan
中国不乏好电影,但能登得上银幕的那就寥寥无几了,幸亏有了抖音,各种不能登上大雅之堂的都能看到,看完反思自己 what's the point of the life ? meaning nothing , just make you confortable,有不少人问,天天写你不累,天天写你的有多闲,实际上我很忙,写仅仅是让我感到 confortable 实际上没有那么多的“故事”。
回到正文做技术的同学都希望埋头钻研技术, 其实在行业中生存,也是需要狐獴精神的,觅食的过程中,是不是抬起头看看,有没有猛兽到访,天上的,路上的,四肢行走的,匍匐前进的,还有电闪雷鸣加雨雪冰雹,稍有不慎,没看到就可能成为牺牲品.会偶然 search 一下 Most popular database , the database future ,等词汇.
这篇文字的起因是下面的这张图, 首先的感觉是,这不科学呀,NO.1 不应该是Oracle , 这一定必有原有.仔细看了这篇文章
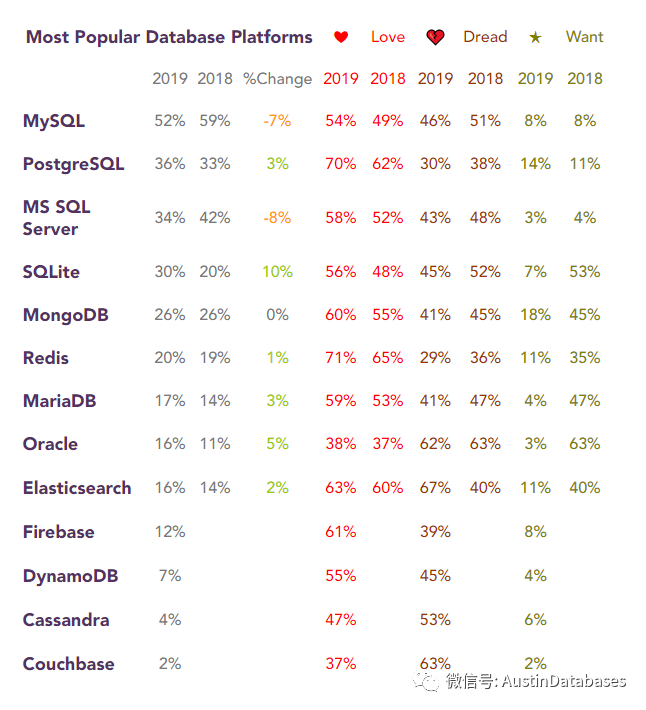
读完第一段后,明白了这篇文字主要的对象是数据库容器化,和DEVOPS , 在2019年在这些方面中,数据库被喜爱的程度, 那ORACLE 有此名次也就在正常不过了。

那么统计的数据从哪里来, Stack Overflow, 别说你不知道这是啥, 地球人IT的都知道, 比GOOGLE 搜索对于某些方面可能收集的信息的准确度会更高,因为至少人家要提问题,并不是随便搜索一个词就被统计进去

为什么PG在头部排名的原因, 免费好用,提供的功能多, 一句话表达 easy one to make many things.
要表达easy 下面有一个实例,最近开发问过我,如果开发中使用PG的话,应该是用 VARCHAR ,Char ,我给的答复是 text,是的因为在PG的原理中 VARCHAR 和 TEXT 其实没有性能的不同,他们再次和我确认,你是认真的吗, 这不就是跟随意扩展字段一样,以后就没有什么因为字段不够导致的,要改字段结构的事情,尤其特别大的表. 我都看到他们的嘴咧到后槽牙了. (当然实际中是会限制的)
同时可以看到上面的排名中,MONGODB 也比较靠前的原因也和目前的主流的数据交互形式有关,JSON 是程序接口间标准的数据交互形式,所以MONGODB 在支持JSON的同时,还能进行数据的分析和聚合,并且社区版提供了大部分的必要功能,(NEO4J这点就比较差了,社区和企业差距太大).
所以听听不同的声音,有利于脑部做做课间操。
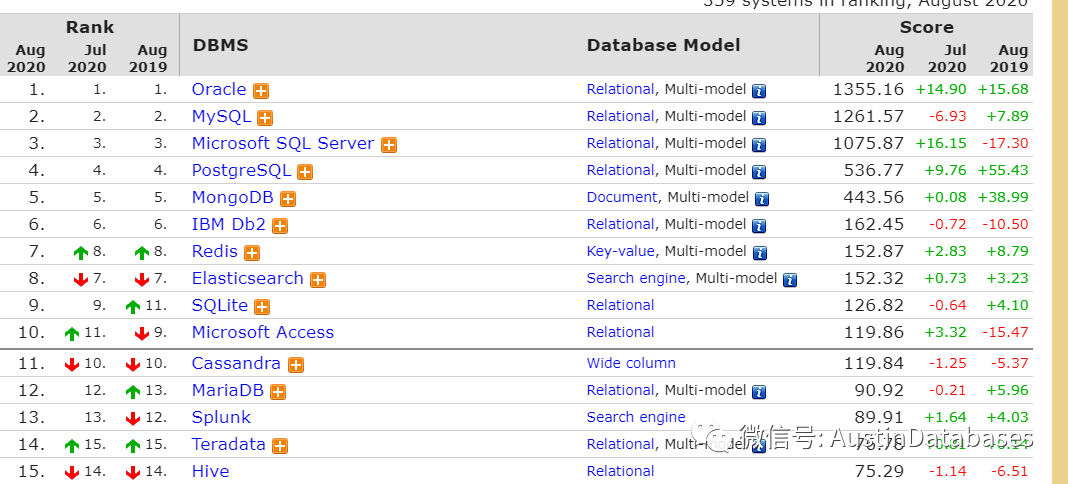
回到此文的重点,中国的数据库市场是怎样,到底怎么发展,因为饭碗在中国, 红旗的方向就是饭碗的方向.这边找了一篇最近金融行业对中国数据库产业的分析报告. 哦顺便说一句,这篇文字你在BAIDU 上可还真不容易找到,所以要找到这篇文字,还靠G。

这篇文字在开头就指出,我国2020年的数据库软件市场规模会达到200亿元。当然这结论不是直接得出,是通过多年的调研和数据,分析得出,2009年到2019年,我国的数据库市场以平均17.5的速度平稳的增长。其中的另一个数据2017年我国的120.22亿元的数据库市场,国外的软件企业份额在103.07亿元,16亿元的国产数据库份额在 14.27%。
其实本身数据库的种类从之前的RDS,到 NO-SQL ,(NOSQL 也分为,键值数据库, 列式存储,文档数据库,图形数据库), 当然还有时序数据库等等,从需求看OLTP OLAP ,HTAP 的需求可以将这些数据库在分分类。当然如果要再分,就是传统数据库和分布式数据库之间的战争。所以如果到此脑部,还仅仅有oracle 这一个单词,那你和数据库市场之间的距离就是东京到巴黎,土耳其和莫斯科的距离了。
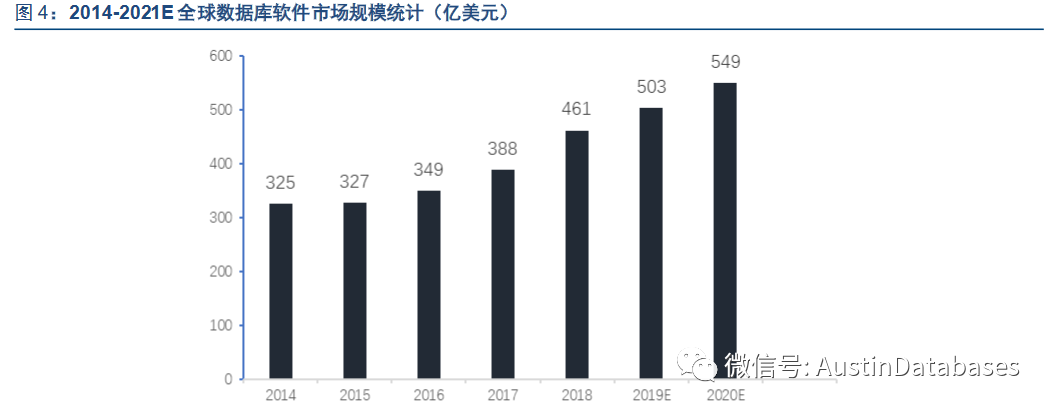
从分析报告中给出的国内国产数据库市场的规模也是逐年递增的
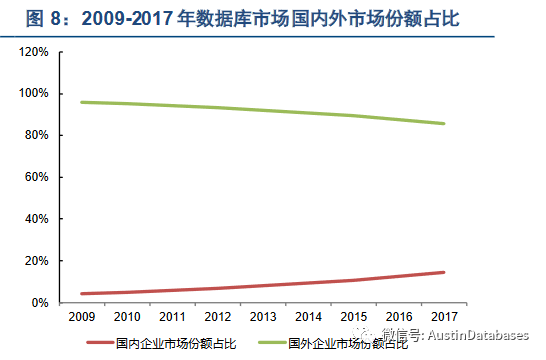
从上图可以看出从2009年开始,国内的数据库市场处于0 ,但到2017年已经达到20%, 当然从今年开始估计这个数字会更好看。
这里就产生一个问题,为什么大部分数据库从业者,还是很难感受到国产数据库软件,国产数据库软件都在哪些企业使用的问题。和到底哪些软件被使用。要说清这个问题还的需要分类
数据库研发方式 : 自研 和 非自研
国产数据库市场份额比例 :超过10% 和 低于 10%
另外到底谁使用了,这个问题也是大家关心的
摘取:文中的一段话

具体的内容可以去看这篇文字的PDF, 因为涉及厂家以及敏感信息,庙小就不多言了,一句话,国产数据库走向了和国家初期发展电动汽车时的老路,何时这些厂家不会因为在涉密,信密体系的名单中存活,和国产汽车企业一样,开始和合资车正面抗争,那国产数据库才真的能被称为国产数据库.
实际上国产数据库大部分都是在,银行,政府,军队来买单,大中小型企业基本上看不到太多的身影,原因也很简单,有盗版的ORACLE , SQL SERVER 在大量的使用,并且国产数据库软件,基本上处于三无的水平,无广泛宣传,无知名社区,无专业知名的大咖。如提到ORACLE 那就想到盖老师, 提到PG 就想到 德哥. 国产继续如此发展也会和国产汽车的经历差不多,如中国汽车企业发展了多年,其实在变速器,发动机,底盘上还是和国外有差距,目前还只能在中低端中存活,反观那些国家的国企汽车企业,和民营的汽车企业相比就更差了,还不如民营的汽车企业有知名度较高的辨识的产品,就是保护太多,扶不起来。
注:某国产数据库服务的行业

到底国产数据库要怎么弯道超车,文中也提到,上云,其中提到2023年 75%的数据库要运行在云上,其实我对此有些疑问,大型企业,国家企业,有多少会上云,上云的企业大多是不是小型企业,考虑上云的企业大部分是在成本上的考虑,减少维护人员,减少数据库本身购买的成本,减少配套的基础设备的成本,这一切都和钱有关,而又有多少企业在具备的一定规模后,又开始将数据,从云上迁出,这些文中都没给出答案。
如,某云本身行业知名度不高,但做起政府的生意稳准狠,将大部分政府的网站都迁移到这个云,看似是政府上云,实际上不过又是政府保护主义的延伸。
到此,风口到底在哪里,这里不是对从业者来说,而是对国产数据库软件厂商来说,抱着政府采购,涉密名单这样的想法存活,风口不风口的不值得讨论,而是怎么达到政府的标准,让数据库能让政府批量采购,这样的方面动心思,最后只能落得国产数据库,而不是国产数据库产业。
这里胆敢胡说八道,针对国产数据库软件,为什么不能也有免费试用,来盗盗版,或者说你使用,厂商补贴的活动,进行大范围的推广才是当下要做的,收集出客户对数据库软件的建议和不满,将产品做的更贴近市场,到时候不用政府采购也能活着,你不选我没得选精神发扬光大.
其实风口已经来临,政治因素,地缘因素,市场因素已经齐聚,至于要怎么
飞,飞得起来飞不起来,只能看国家的导向,和扶持的方式,以及各个厂商自己的选择的“命” 而定了。

















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









