



 本文介绍了一种快速定位MYSQL CPU使用率高的方法,包括使用pidstat查看线程CPU使用率,结合查询确定问题连接,以及使用PMM监控系统查找CPU消耗点。通过实际案例测试,增加CPU数量并不能解决LOAD100%的问题。
本文介绍了一种快速定位MYSQL CPU使用率高的方法,包括使用pidstat查看线程CPU使用率,结合查询确定问题连接,以及使用PMM监控系统查找CPU消耗点。通过实际案例测试,增加CPU数量并不能解决LOAD100%的问题。

MYSQL 的CPU 使用率高,干时间长的DB们都会遇到,其实其他的数据库也都是有类似的问题,CPU一升高。大部分DBA 的首要工作就是要看是不是有大事务,大查询,慢查询等等。实际上我们是不是有更好的快速定位的方法
下图我们可以看到系统CPU一直在 90%, 到底什么原因造成MYSQL的CPU 利用率一直高怎么分析。follow me.
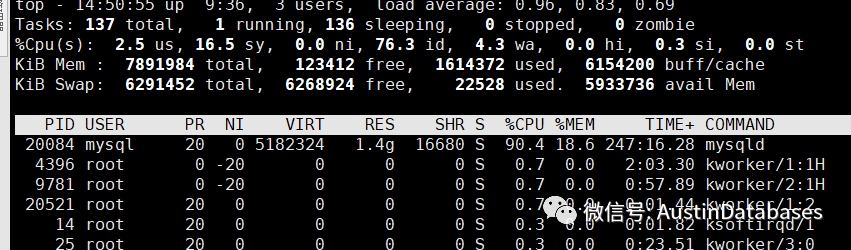
我们通过pidstat 来查看当前MYSQL的线程中那个CPU的使用率比较高

可以通过上图看到0 和 1 号CPU 核心的使用率比较其他的核心要高,并且我们也看到TID ,线程的数字,然后我们拿到这些线程的ID 直接回到MYSQL 内部,我们看看到底这两个线程在做什么。
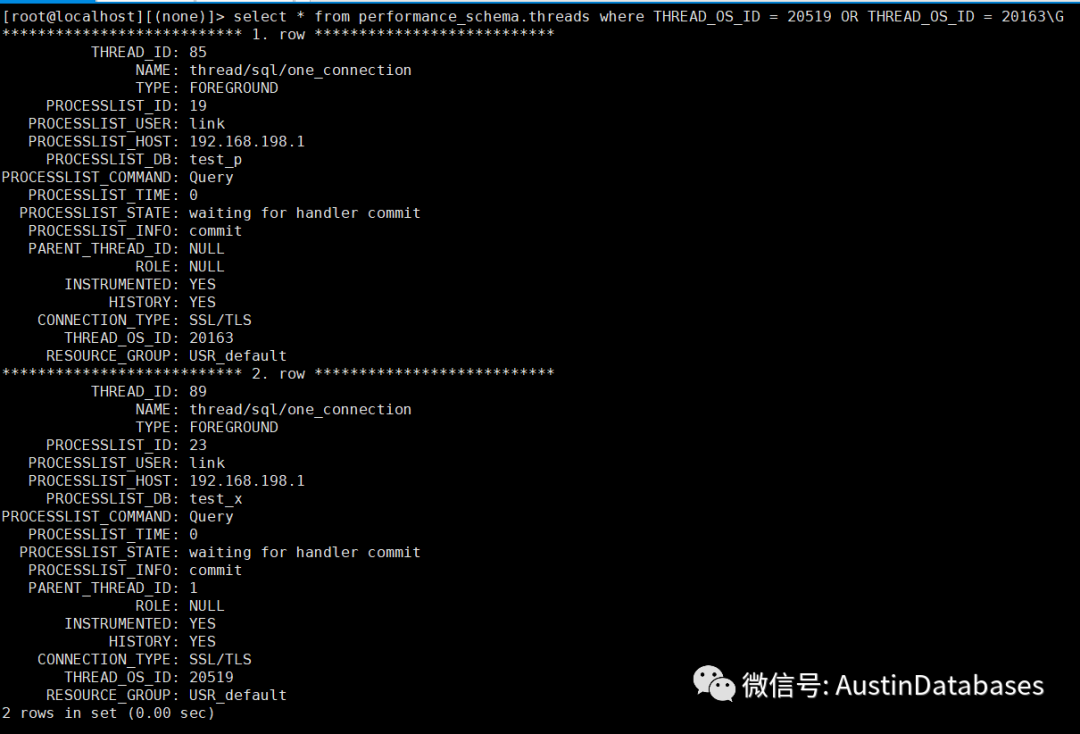
我们可以结合上面的查询
1 我们可以确定到底多核心CPU上到底那个核心的CPU的利用率比较高
2 通过查找到哪个核心的CPU的使用率多少,定位到MYSQL 中的有问题的连接。
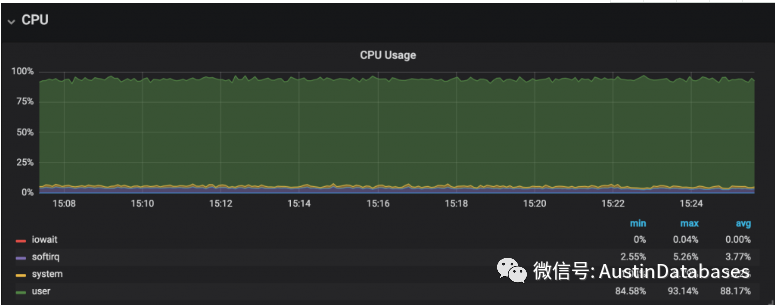
另外也可以通过监控系统来查看CPU 消耗在哪里,例如可以使用PMM,查看CPU 的消耗点在哪里,如果是用户user的层面,那就可以确认是用户的某些线程消耗了CPU的资源。然后可以通过上面的手段来定位当前到底那些线程在大量的使用CPU
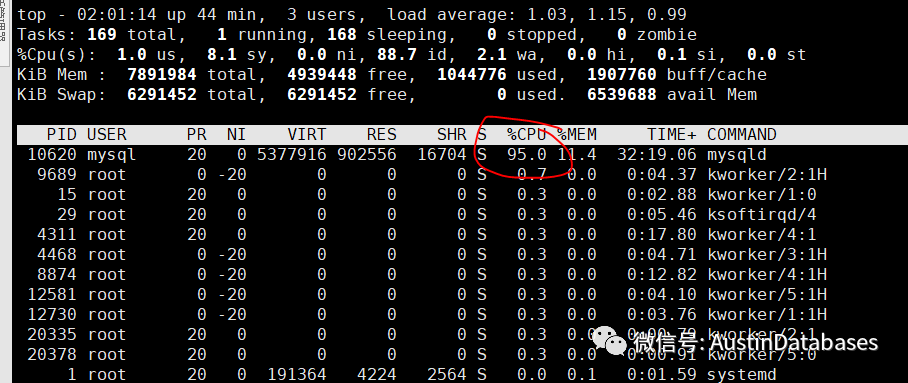
这里有一个插曲,曾经听到如果遇到这样的情况,添加CPU 暂时缓解CPU LOAD 100 percent 的情况,这里做了一个test.
将上面的有压力的MYSQL 的CPU 添加一倍从4 croe 变为 8核心,最终结果(至少在我这里),CPU的LOAD 基本上没有变化,在负载同样的情况。
另外同时可以用下面的脚本,看一下瞬时的 QPS TPS 看看是不是系统已经超负荷运行。
mysqladmin -uroot -p'password' --socket=/data/mysql/mysql.sock extended-status -i1|awk 'BEGIN{local_switch=0;print "QPS Commit Rollback TPS Threads_con Threads_run \n------------------------------------------------------- "}
$2 ~ /Queries$/ {q=$4-lq;lq=$4;}
$2 ~ /Com_commit$/ {c=$4-lc;lc=$4;}
$2 ~ /Com_rollback$/ {r=$4-lr;lr=$4;}
$2 ~ /Threads_connected$/ {tc=$4;}
$2 ~ /Threads_running$/ {tr=$4;
if(local_switch==0)
{local_switch=1; count=0}
else {
if(count>10)
{count=0;print "------------------------------------------------------- \nQPS Commit Rollback TPS Threads_con Threads_run \n------------------------------------------------------- ";}
else{
count+=1;
printf "%-6d %-8d %-7d %-8d %-10d %d \n", q,c,r,c+r,tc,tr;
}
}
}'
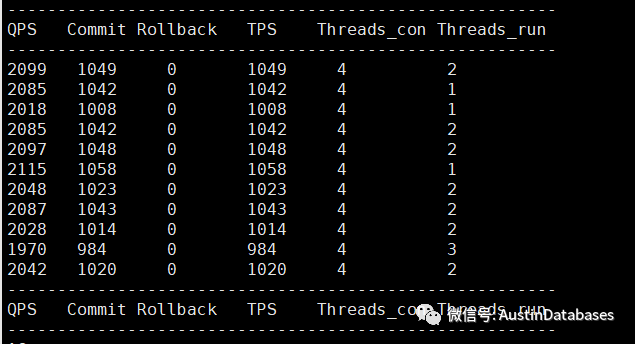
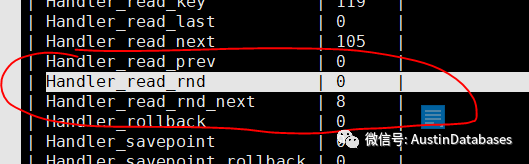
同时可以辅助查看当前的handler_read_rnd , handler_read_rnd_next 等参数,如果快速的增长,说明当前的查询有全表扫描或者无法有效利用索引的情况。
剩下的工作可能就要和相关的一些慢查询或者捕捉到的语句来进行相关的分析了。



















 1652
1652




 到【灌水乐园】发言
到【灌水乐园】发言







