







文章目录
Spark-SQL物理执行
物理执行作为Spark-SQL执行过程中的最后一步,是将逻辑执行计划转换为物理执行计划SparkPlan,然后可以在Spark-Core上直接运行生成RDD。
Spark-Sql的整个执行过程其实在QueryExecution中定义得非常清楚,如代码所示:
//QueryExecution
//执行优化
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
//选取物理执行计划
lazy val sparkPlan: SparkPlan = {
SparkSession.setActiveSession(sparkSession)
//目前只是选取多个物理计划的第一个
planner.plan(ReturnAnswer(optimizedPlan)).next()
}
//执行前准备
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
//执行物理计划
lazy val toRdd: RDD[InternalRow] = executedPlan.execute()
分区操作和分布情况(Partitioning和Distribution)
在spark中,分区一直是影响性能的重要指标。尤其是在Join和聚合的场景中,例如在plan1和plan2的Hash Join中,plan1和plan2的分区方式就必须要求是基于相同key的hash分布。如果是广播类型的Join,就要求至少有一边是广播变量数据分布。
Distribution是数据分布情况,Partitioning是分区操作
Distribution与Partitioning关联,定义了数据在集群各个节点上的分布情况
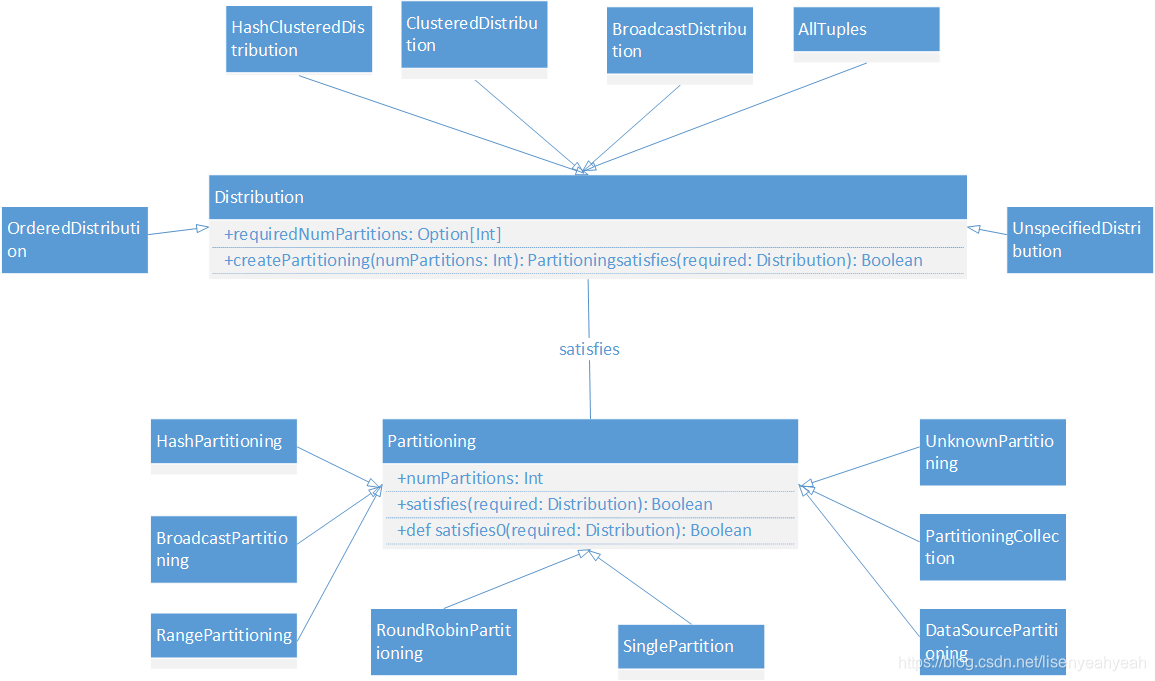
Distribution包括以下6种:
| Distribution类型 | 描述 |
|---|---|
| UnspecifiedDistribution | 未指定分布 |
| AllTuples | 单分区,例如GlobalLimit算子 |
| BroadcastDistribution | 广播分布,数据会广播到所有节点上,构造参数mode为广播模式(BroadcastMode),例如Broadcast的Join操作中的requiredChildDistribution为[BroadcastDistribution(mode)] |
| ClusteredDistribution | 构造参数clustering是Seq[Expression]类型,起到哈希函数的效果,经过clustering之后,相同的value数据会放到一个分区中,例如SortAggregateExec类型的Join操作中的requiredChildDistribution就是ClusteredDistribution(exprs) |
| HashClusteredDistribution | 构造参数expressions是Seq[Expression]类型,起到哈希函数的效果,经过expressions之后,相同的value数据会放到一个分区中,例如SortMerge类型的Join操作中的requiredChildDistribution就是[HashClusteredDistribution(leftKeys), HashClusteredDistribution(reghtKeys)] |
| OrderedDistribution | 构造参数ordering是Seq[SortOrder]类型,数据会根据ordering计算后的结果排序。在全局的Sort算子中,requiredChildDistribution就是[OrderedDistribution(sortOrder)] |
Partitioning表示数据分区操作,如上图所示,介绍下内部重要的成员变量和函数
trait Partitioning {
//该SparkPlan输出RDD的分区数目
val numPartitions: Int
//当前的partitioning操作能否得到所需的数据分布,当不满足时返回false,一般需要进行repartition操作,
//对数据进行重新组织
final def satisfies(required: Distribution): Boolean = {
required.requiredNumPartitions.forall(_ == numPartitions) && satisfies0(required)
}
protected def satisfies0(required: Distribution): Boolean = required match {
case UnspecifiedDistribution => true
case AllTuples => numPartitions == 1
case _ => false
}
}
Partitioning包括以下7种
| Partitioning类型 | 描述 |
|---|---|
| UnknownPartitioning | 不进行分区 |
| RoundRobinPartitioning | 在1-numPartitions范围内轮训式分区 |
| HashPartitioning | 基于Hash的分区 |
| RangePartitioning | 基于范围的分区 |
| PartitioningCollection | 分区方式的集合,描述物理算子的输出 |
| BroadcastPartitioning | 广播分区 |
| DataSourcePartitioning | V2 DataSource的分区方式 |
物理计划(SparkPlan)
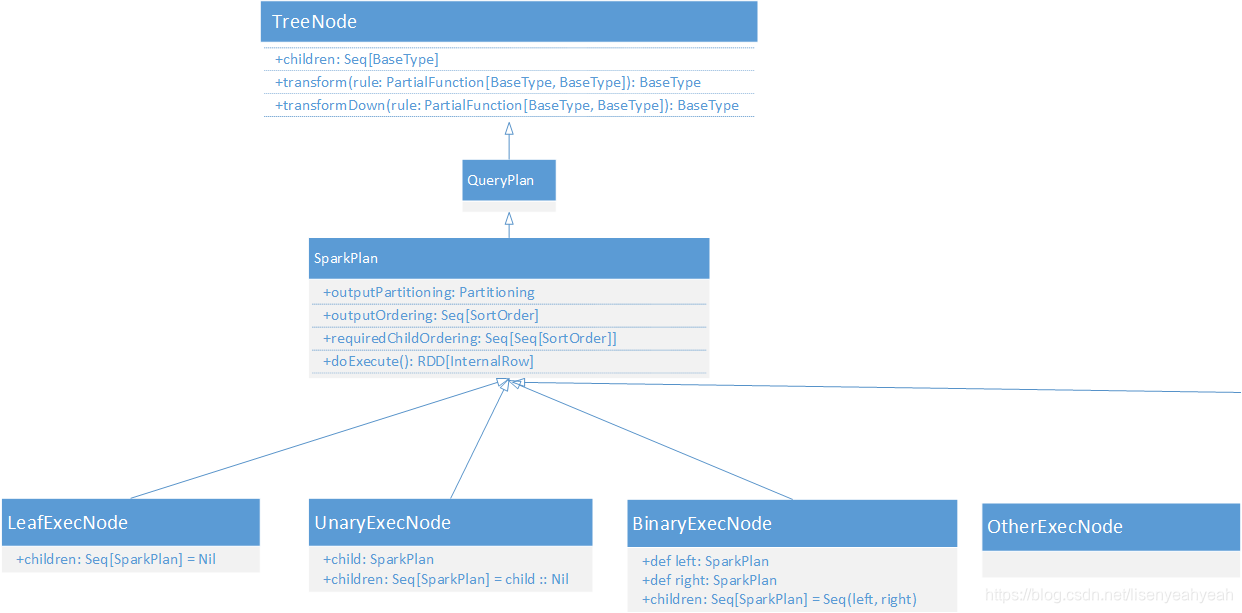
SparkPlan和LogicalPlan基本是一一对应的,和LogicalPlan类似,都继承自QueryPlan[PlanType <: QueryPlan[PlanType]],命名规则都是XXXExec。SparkPlan的重要方法如下:
| 方法 | 作用描述 |
|---|---|
| outputPartitioning | 定义SparkPlan输出数据的分区方式 |
| requiredChildDistribution | 定义SparkPlan要求子节点遵守的分区方式 |
| outputOrdering | 定义SparkPlan输出数据的排序方式 |
| requiredChildOrdering | 定义SparkPlan要求子节点遵守的排序方式 |
| doExecute | 执行生成RDD |
abstract class SparkPlan extends QueryPlan[SparkPlan] with Logging with Serializable {
...
//定义SparkPlan输出数据的分区方式
def outputPartitioning: Partitioning = UnknownPartitioning(0)
//定义SparkPlan要求子节点遵守的分区方式
def requiredChildDistribution: Seq[Distribution] =
Seq.fill(children.size)(UnspecifiedDistribution)
//定义SparkPlan输出数据的排序方式
def outputOrdering: Seq[SortOrder] = Nil
//定义SparkPlan要求子节点遵守的排序方式
def requiredChildOrdering: Seq[Seq[SortOrder]] = Seq.fill(children.size)(Nil)
//执行操作
protected def doExecute(): RDD[InternalRow]
下面介绍几个比较常见的SparkPlan:
投影(ProjectExec)
doExecute方法比较简单,就是执行子节点的execute方法并通过子节点的输出属性构造RDD[InternalRow]返回,其中输出的Ordering和Partitioning都取自子节点的排序和分区。
case class ProjectExec(projectList: Seq[NamedExpression], child: SparkPlan)
extends UnaryExecNode with CodegenSupport {
override def output: Seq[Attribute] = projectList.map(_.toAttribute)
override def inputRDDs(): Seq[RDD[InternalRow]] = {
child.asInstanceOf[CodegenSupport].inputRDDs()
}
protected override def doExecute(): RDD[InternalRow] = {
child.execute().mapPartitionsWithIndexInternal {
(index, iter) =>
val project = UnsafeProjection.create(projectList, child.output,
subexpressionEliminationEnabled)
project.initialize(index)
iter.map(project)
}
}
override def outputOrdering: Seq[SortOrder] = child.outputOrdering
override def outputPartitioning: Partitioning = child.outputPartitioning
}
过滤(FilterExec)
过滤的execute方法也比较简单,也是执行子节点的execute方法,通过子节点的输出属性和condition构造predicate表达式,计算数据并返回RDD[InternalRow]
case class FilterExec(condition: Expression, child: SparkPlan)
extends UnaryExecNode with CodegenSupport with PredicateHelper {
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
child.execute().mapPartitionsWithIndexInternal {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3398
3398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









