




 本文深入解析Spark SQL如何利用Antlr4进行SQL语句的解析,从词法分析到语法树构建,再到未解析逻辑计划的生成,详细阐述了Spark-SQL解析流程及Antlr4的应用。
本文深入解析Spark SQL如何利用Antlr4进行SQL语句的解析,从词法分析到语法树构建,再到未解析逻辑计划的生成,详细阐述了Spark-SQL解析流程及Antlr4的应用。
Spark-SQL解析
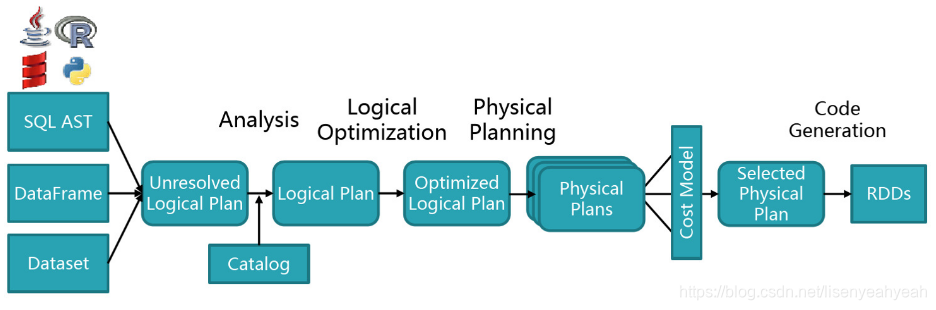
如下图所示,Spark-SQL解析总体分为以下几个步骤:解析(Parser)、绑定(Analysis)、优化(Optimization)、执行(Physical)、生成RDD(RDDs)。接下来,我们先介绍解析部分,对于绑定、逻辑计划的优化、物理执行计划、生成RDD后面再专门介绍。
Antlr4
一、简介
最新的Spark-Sql解析模块为spark-catalyst_2.11,通过Antlr4(Another Tool for Language Recognition)框架来实现。ANTLR 是用JAVA写的语言识别工具,它用来声明语言的语法。它的语法识别分为两个阶段:
1.词法分析阶段 (lexical analysis)
对应的分析程序叫做 lexer ,负责将符号(token)分组成符号类(token class or token type)
2.解析阶段
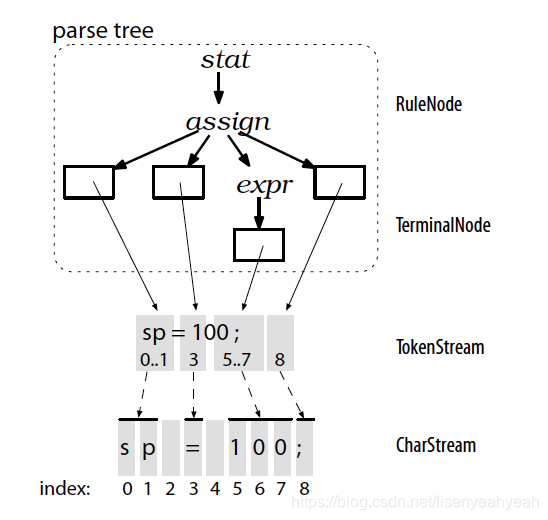
根据词法,构建出一棵分析树(parse tree)或叫语法树(syntax tree)
二、语法
以下是四则运算的例子,Math.g4
grammar Math; //声明语法头,类似于java类的定义
@header{package com.zetyun.aiops.core.math;} //在运行脚本后,生成的类中自动带上这个包路径,避免了手动加入的麻烦。
prog : stat+;
stat: expr NEWLINE # printExpr //定义规则:这是核心,表示规则,以 “:” 开始, “;” 结束, 多规则以 "|" 分隔。
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*' ; // assigns token name to '*' used above in grammar
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ;
INT : [0-9]+ ;
NEWLINE:'\r'? '\n' ;
WS : [ \t]+ -> skip;
字符含义
() : 产生式组合
? : 产生式出现0或1次
* : 0或多次
+ : 1或多次
. : 任意一个字符
~ : 不出现后面的字符
.. : 字符范围
三、编译
利用antlr4-maven-plugin插件即可完成自动编译。
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-runtime</artifactId>
<version>4.7</version>
</dependency>
<plugin>
<groupId>org.antlr</groupId>
<artifactId>antlr4-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>antlr4</goal>
</goals>
</execution>
</executions>
<configuration>
<visitor>true</visitor>
<sourceDirectory>../stream-catalyst/src/main/antlr4</sourceDirectory>
</configuration>
</plugin>
可通过IDEA的maven插件编译,之后可在根目录\target\generated-sources\antlr4\com\hikvs\bigdata\catalyst\parser下产生以下JAVA文件:
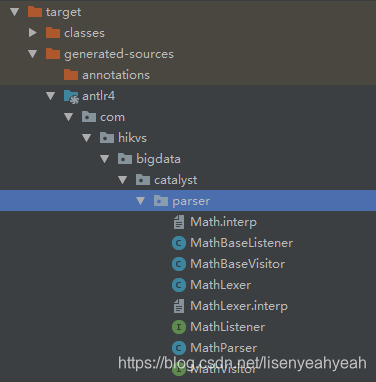
其中MathLexer是词法分析器、MathParser是语法分析器、MathVisitor和MathBaseVisitor分别是访问者接口和访问者类。
四、遍历模式
Antlr4的遍历模式分两种:
1.Listener(观察者模式)
优点:通过节点监听,触发处理方法,用户不需要显示控制语法树的顺序,实现简单。
缺点:不能显示控制遍历语法树的顺序;没有返回值,需要使用map、栈等结构在节点间传值
2.Visitor(访问者模式)
优点:主动遍历,用户可以显示定义遍历语法树的顺序、有返回值。
比较两种模式,一般采用访问者模式,可以显示控制遍历树的顺序。访问者类的作用是用于遍历整个语法树,然后进行相关操作,用户可以自己实现访问者类来定义自己需要的功能。
public class MathVisitorTest extends MathBaseVisitor<Integer> {
Map<String, Integer> memory = new HashMap<String, Integer>();
@Override
public Integer visitPrintExpr(MathParser.PrintExprContext ctx) {
Integer value = visit(ctx.expr());
return value;
}
@Override
public Integer visitAssign(MathParser.AssignContext ctx) {
String id = ctx.ID().getText();
int value = visit(ctx.expr());
memory.put(id, value);
return value;
}
@Override
public Integer visitBlank(MathParser.BlankContext ctx) {
return super.visitBlank(ctx);
}
@Override
public Integer visitParens(MathParser.ParensContext ctx) {
return visit(ctx.expr());
}
@Override
public Integer visitMulDiv(MathParser.MulDivContext ctx) {
int left = visit(ctx.expr(0));
int right = visit(ctx.expr(1));
if ( ctx.op.getType() == MathParser.MUL ) return left * right;
return left / right;
}
@Override
public Integer visitAddSub(MathParser.AddSubContext ctx) {
// TODO Auto-generatedmethod stub
int left = visit(ctx.expr(0));
int right = visit(ctx.expr(1));
if ( ctx.op.getType() == MathParser.ADD ) return left + right;
return left - right;
}
@Override
public Integer visitId(MathParser.IdContext ctx) {
String id = ctx.ID().getText();
if ( memory.containsKey(id) ) return memory.get(id);
return 0;
}
@Override
public Integer visitInt(MathParser.IntContext ctx) {
return Integer.valueOf(ctx.INT().getText());
}
}
public class Math {
public static void main(String[] args) {
CharStream input = CharStreams.fromString("1*(6-3)/2");
MathLexer lexer = new MathLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
MathParser parser = new MathParser(tokens);
ParseTree tree = parser.prog(); // parse
MathVisitorTest vt = new MathVisitorTest();
Integer r = vt.visit(tree);
System.out.println(r.toString());
}
}
五、Spark-Sql之Antlr4
1.SqlBase.g4
SqlBase.g4是spark-sql的语法解析文件,所属模块为spark-catalyst,SqlBase.g4位于路径\spark-2.3\sql\catalyst\src\main\antlr4\org\apache\spark\sql\catalyst\parser\SqlBase.g4。查询的部分语法如下:
grammar SqlBase;
singleStatement
: statement EOF
;
statement
: query #statementDefault
;
query
: ctes? queryNoWith
;
queryNoWith
: insertInto? queryTerm queryOrganization #singleInsertQuery
| fromClause multiInsertQueryBody+ #multiInsertQuery
;
queryTerm
: queryPrimary #queryTermDefault
| left=queryTerm operator=(INTERSECT | UNION | EXCEPT | SETMINUS) setQuantifier? right=queryTerm #setOperation
;
queryPrimary
: querySpecification #queryPrimaryDefault
| TABLE tableIdentifier #table
| inlineTable #inlineTableDefault1
| '(' queryNoWith ')' #subquery
;
querySpecification
: (((SELECT kind=TRANSFORM '(' namedExpressionSeq ')'
| kind=MAP namedExpressionSeq
| kind=REDUCE namedExpressionSeq))
inRowFormat=rowFormat?
(RECORDWRITER recordWriter=STRING)?
USING script=STRING
(AS (identifierSeq | colTypeList | ('(' (identifierSeq | colTypeList) ')')))?
outRowFormat=rowFormat?
(RECORDREADER recordReader=STRING)?
fromClause?
(WHERE where=booleanExpression)?)
| ((kind=SELECT (hints+=hint)* setQuantifier? namedExpressionSeq fromClause?
| fromClause (kind=SELECT setQuantifier? namedExpressionSeq)?)
lateralView*
(WHERE where=booleanExpression)?
aggregation?
(HAVING having=booleanExpression)?
windows?)
;
2.访问者-AstBuilder
整个SQL解析相关的实现如下图:
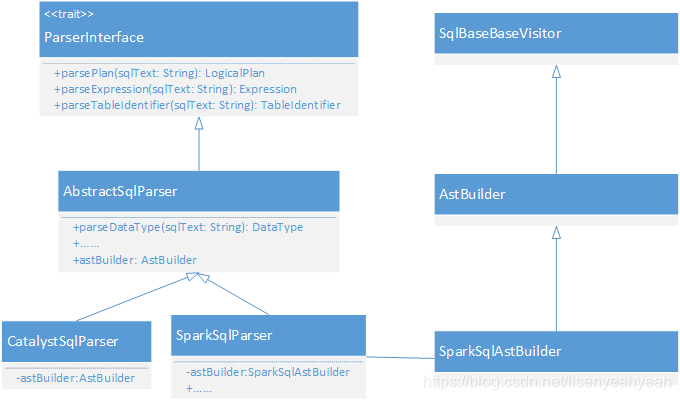
AstBuilder实现了SqlBaseBaseVisitor,并实现了部分visitXXX方法
class AstBuilder(conf: SQLConf) extends SqlBaseBaseVisitor[AnyRef]{
override def visitQuerySpecification(ctx: QuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
.......
}
override def visitSingleStatement(ctx: SingleStatementContext): LogicalPlan = withOrigin(ctx) {
.......
}
override def visitSingleExpression(ctx: SingleExpressionContext): Expression = withOrigin(ctx) {
.......
}
}
3.Spark-SQL执行入口
SparkSession .sql(sqlText: String)是暴露给用户的方法,用于执行sql文本。
class SparkSession private(){
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
}
visitSingleStatement为根节点开始采用递归下降的方式遍历整个语法树,解析后返回的是LogicalPlan,后面我们将介绍逻辑计划(LogicalPlan)。
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match {
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
}
}
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
logDebug(s"Parsing command: $command")
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command)))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
val tokenStream = new CommonTokenStream(lexer)
val parser = new SqlBaseParser(tokenStream)
parser.addParseListener(PostProcessor)
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
try {
try {
// first, try parsing with potentially faster SLL mode
parser.getInterpreter.setPredictionMode(PredictionMode.SLL)
toResult(parser)
}
catch {
......
}
}
catch {
......
}
}
逻辑计划(LogicalPlan)
一、TreeNode
TreeNode 是Catalyst的核心类,语法树的构建都是由一个个TreeNode组成。继承关系如下:
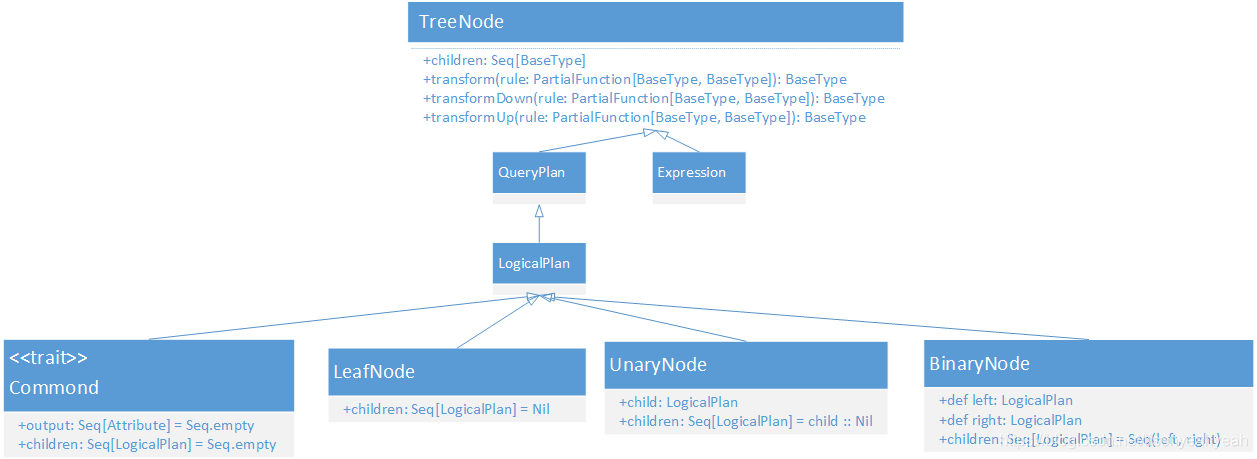
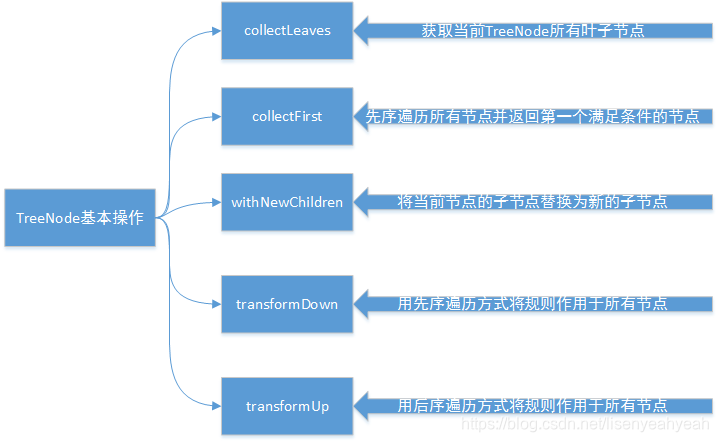
其核心方法的作用如下:
LogicalPlan是TreeNode 的子类,作为数据结构记录了对应逻辑算子树节点的基本信息和基本操作,包括输入输出和各种处理逻辑等。
二、QueryPlan
QueryPlan是LogicalPlan的直接父类,继承自TreeNode,其核心属性和方法可以分为6个部分:
1.输入输出
输入或输出属性,比如Project的output方法就返回所有查询的字段信息。
override def output: Seq[Attribute] = projectList.map(_.toAttribute)
2.基本属性
表示QueryPlan节点的一些基本信息,比如其中schema对应output输出属性的schema信息。
lazy val schema: StructType = StructType.fromAttributes(output)
3.字符串
打印QueryPlan树形结构信息。
4.规范化
QueryPlan的canonicalized直接赋值为当前的QueryPlan类,sameResult方法会利用canonicalized来判断两个QueryPlan的输出结果是否相同。
5.表达式操作
比如expressions会返回改节点所有表达式的列表,另外还有遍历表达式的方法transformExpressions等。
6.约束
可以推导的一种过滤条件,比如“a>1”,可以推出a不能为null。
三、Expression
Expression是SQL语句中的表达式,是指不需要执行引擎计算,而可以直接计算或处理的节点,包括Cast操作、Porjection操作、四则运算和逻辑操作符运算等等。
四、Commond
Commond是直接运行的命令,常见的有ShowCreateTableCommand(展示表)、CreateTableCommand(创建表)、AlterTableRenameCommand(修改表名字)等
trait Command extends LogicalPlan {
override def output: Seq[Attribute] = Seq.empty
override def children: Seq[LogicalPlan] = Seq.empty
}
五、LeafNode
LeafNode是叶子节点,是没有子节点的LogicalPlan,常见的有UnresolvedRelation(未解析的逻辑计划),所有经过antlr4解析后的都是UnresolvedRelation,不能被计算,有未绑定的属性和数据类型。
abstract class LeafNode extends LogicalPlan {
override final def children: Seq[LogicalPlan] = Nil
override def producedAttributes: AttributeSet = outputSet
def computeStats(): Statistics = throw new UnsupportedOperationException
}
六、UnaryNode
UnaryNode有一个子节点,常见的有Filter(过滤)、Project(投影)、Window(窗口)等
abstract class UnaryNode extends LogicalPlan {
def child: LogicalPlan
override final def children: Seq[LogicalPlan] = child :: Nil
protected def getAliasedConstraints(projectList: Seq[NamedExpression]): Set[Expression] = {
......
}
override protected def validConstraints: Set[Expression] = child.constraints
}
七、BinaryNode
BinaryNode有两个子节点,常见的有Join(关联)、Except(差集)、Intersect(交集)
abstract class BinaryNode extends LogicalPlan {
def left: LogicalPlan
def right: LogicalPlan
override final def children: Seq[LogicalPlan] = Seq(left, right)
}
生成未解析逻辑计划(UnResolve LogicalPlan)
以查询为例子来说明生成未解析逻辑计划的过程,例如执行SQL为:
SELECT SUM(AGE)
FROM
(SELECT A.ID,
A.NAME,
CAST(B.AGE AS LONG) AS AGE
FROM
NAME A INNER JOIN AGE B
ON A.ID == B.ID)
WHERE AGE >20
通过antlr4解析后得到的抽象语法树如下图所示:
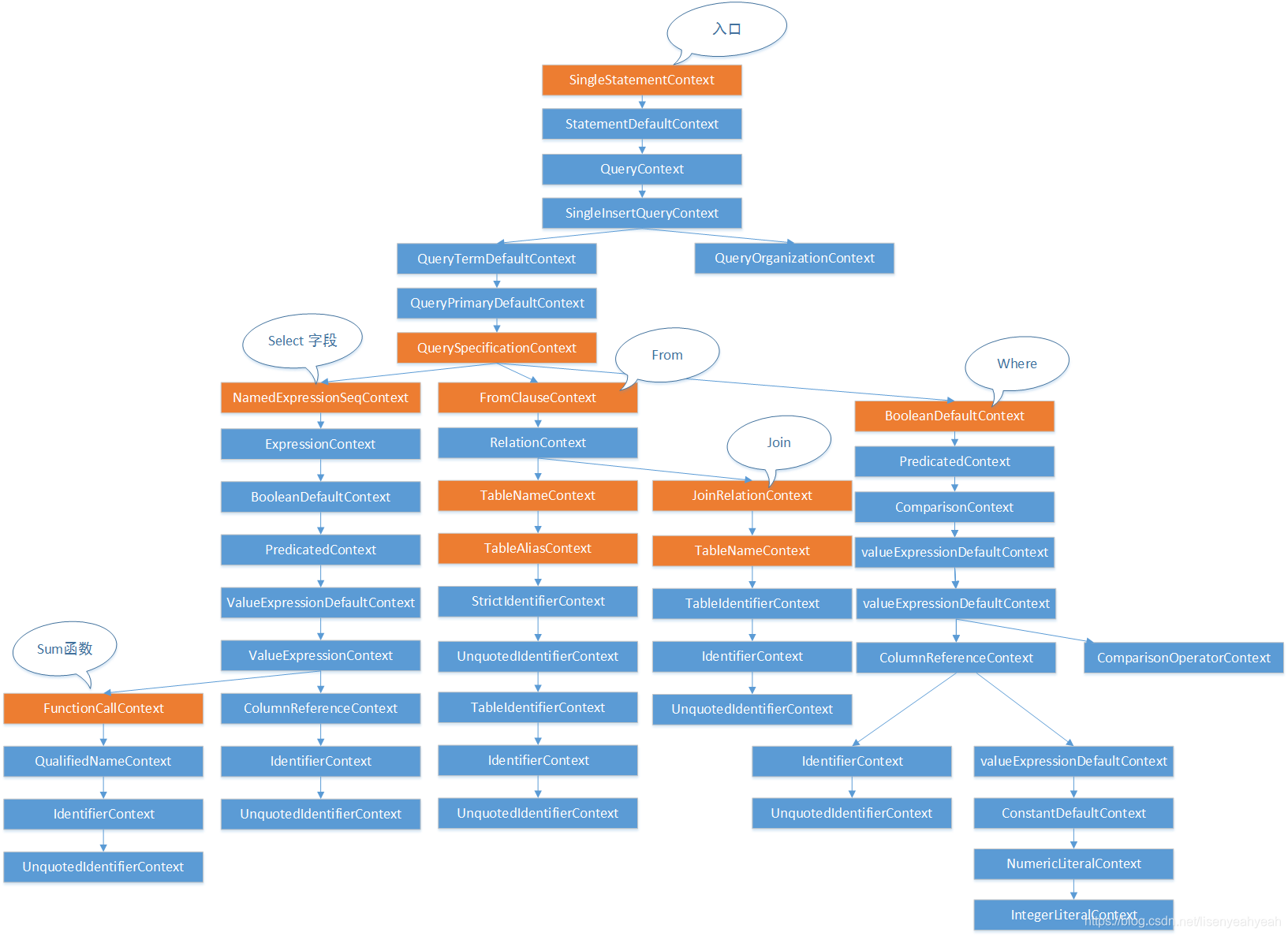
通过Asbuilder访问类对语法树进行访问,代码会执行
override def visitQuerySpecification(
ctx: QuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) {
visitFromClause(ctx.fromClause)
}
withQuerySpecification(ctx, from)
}
生成UnResolve LogicalPlan的过程如图:
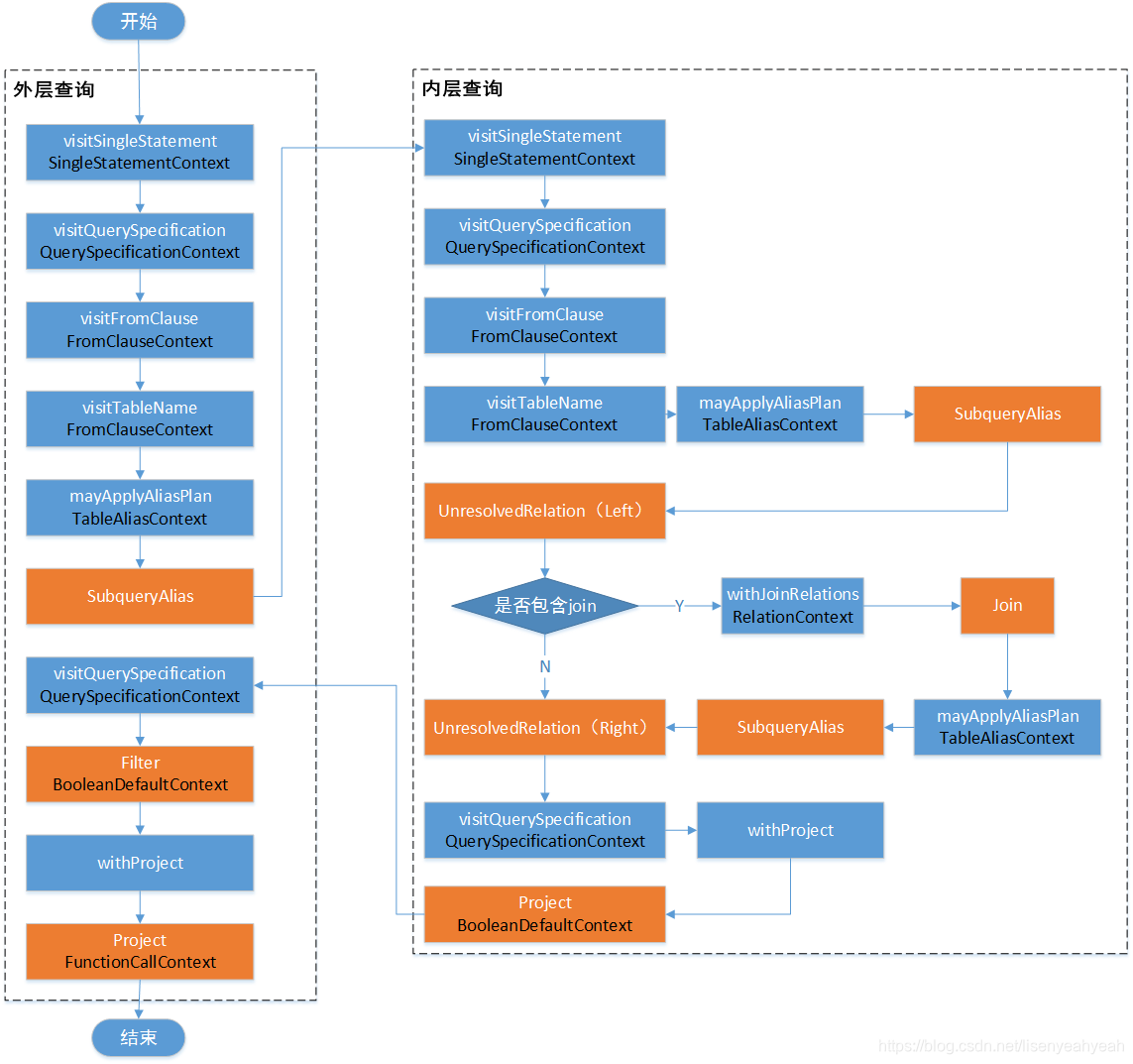
简化后的流程图为:
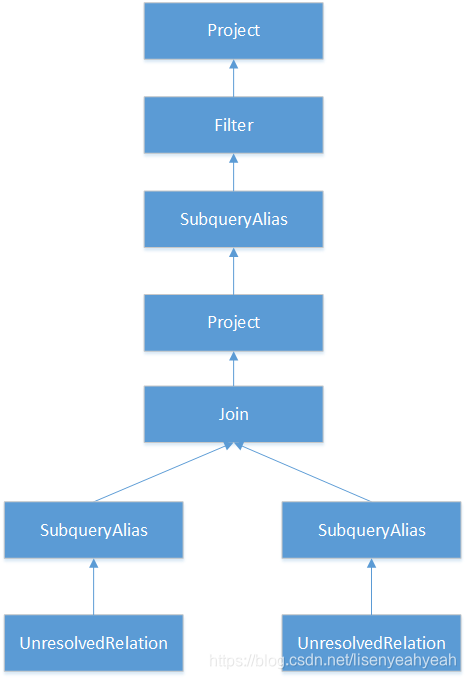
具体步骤如下:
(1)UnresolvedRelation:对应SQL语句的from的表名,访问FromClauseContext并递归向下访问,最终匹配到TableNameContext节点时,直接根据TableNameContext的信息生成UnresolvedRelation,构造名为from的LogicalPlan并返回。
(2)Join:对应SQL语句中的INNER JOIN语句,通过withJoinRelations最终构造Join(left, plan(join.right), joinType, condition)返回。包括左表、右表、关联类型、条件。
(3)Filter:对应SQL语句中的where语句,QuerySpecificationContext中包含了BooleanExpressionContext类型,Asbuilder会对改子树进行递归访问,此例中碰到ComparisonContext节点,生成GreaterThan表达式,然后生成expression并返回作为过滤条件,构造Filter(expression(ctx), plan)返回。
(4)Project:对应SQL语句中select对列值的选择操作,Asbuilder在访问中会获取NamedExpressionSeqContext,并对其所有子节点对应的表达式进行转换,生成Expression列表expressions,基于expressions构造Project(namedExpressions, withFilter)返回。
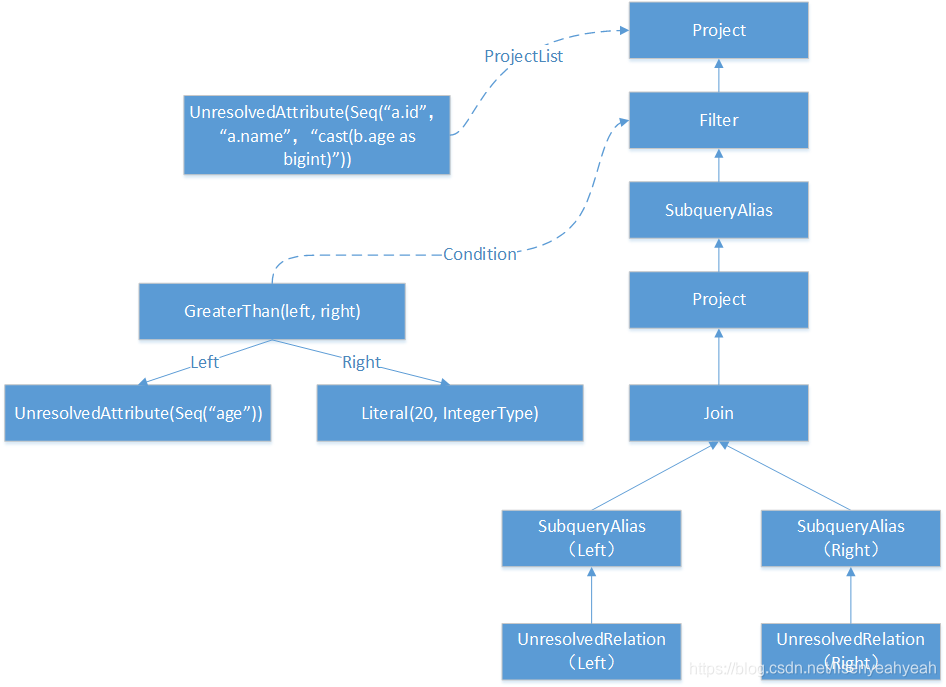
其中各节点中的Expression情况如下:
下表列出了构造Filter逻辑算子树节点中的condition表达式。根据ColumnReferenceContext节点信息生成UnresolvedAttribute表达式。
| 访问操作 | Expression |
|---|---|
| visitColumnReference | UnresolvedAttribute(Seq(“age”)) |
| visitIntegerLiteral | Literal(20, IntegerType) |
| visitComparison | GreaterThan(left, right) |
下表列出了构造Project逻辑算子树节点中的condition表达式。
| 访问操作 | Expression |
|---|---|
| visitColumnReference | UnresolvedAttribute(Seq(“a.id”,“a.name”,“cast(b.age as bigint)”)) |
树形结构如下图:
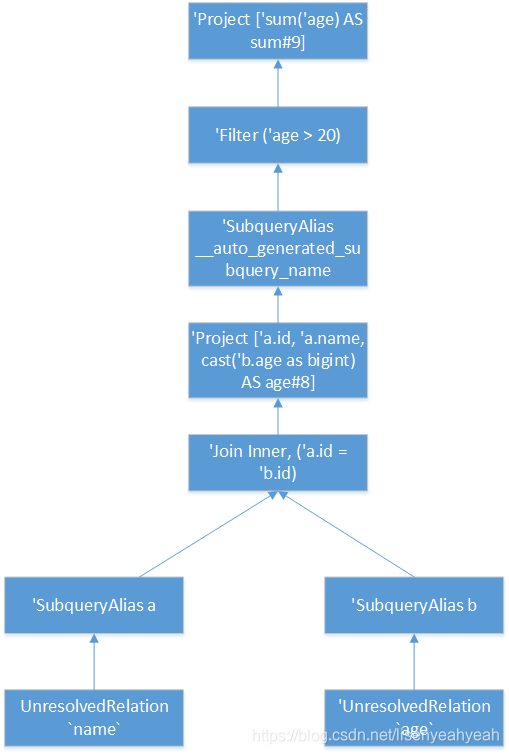
最终生成的未解析LogicalPlan为:
'Project ['sum('age) AS sum#9]
+- 'Filter ('age > 20)
+- 'SubqueryAlias __auto_generated_subquery_name
+- 'Project ['a.id, 'a.name, cast('b.age as bigint) AS age#8]
+- 'Join Inner, ('a.id = 'b.id)
:- 'SubqueryAlias a
: +- 'UnresolvedRelation `name`
+- 'SubqueryAlias b
+- 'UnresolvedRelation `age`
树形结构如下图所示:
至此,我们知道了Spark是如何将一个SQL语句通过Antlr4生成未解析的LogicalPlan的流程,这个LogicalPlan中的表名、函数名、字段名等都是未解析的,并没有绑定任何东西。接下来会进入Analyzer(分析)阶段,完成绑定操作,具体请参考下一篇文章。
参考资料
[1]: 《Spark SQL内部剖析》朱锋 张韶全 黄明 著
[2]: Spark SQL catalyst概述和SQL Parser的具体实现
[3]: 利用ANTLR4实现一个简单的四则运算计算器

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









