




Flink发送Elasticsearch的问题
场景
目前是基于Flink1.11.1来实现日志的处理,中间涉及日志的解析和转发,最终发送到Elasticsearch,Elasticsearch服务端版本为6.3.1,客户端使用flink-connector-elasticsearch6_2.11(Flink提供的es sink connector,依赖的es客户端版本也是6.3.1),部署模式采用Flink Standalone,集群上一共就运行1个任务。
问题
资源配置困难
flink每个operator都可以配置并行度,具体每个operator应该设置多少并行度,每个TaskManager设置多少slot,多少内存,目前都是盲配的状态,主要有以下几个原因:
-
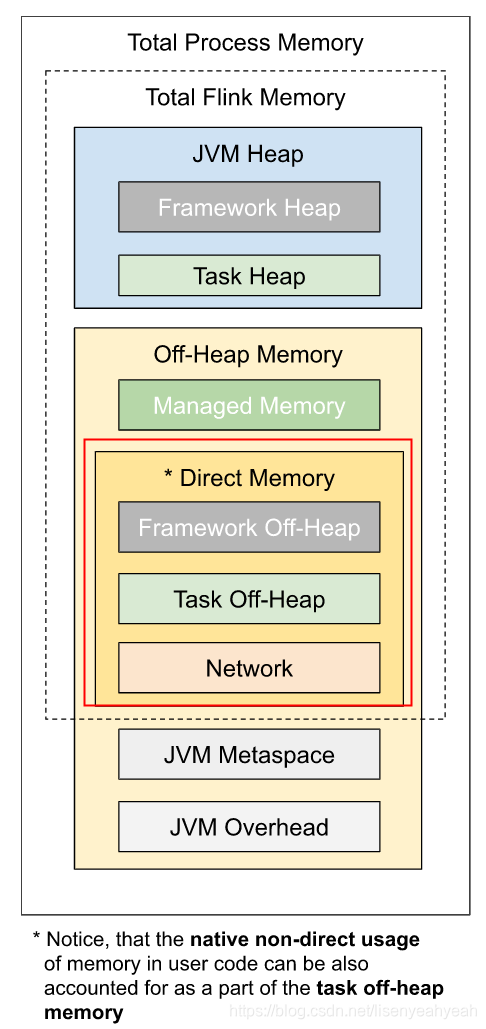
flink taskmanager提供很多内存参数,包括堆内存、堆外内存、metaspace内存等,粒度较细;
-
slot虽然是flink最小的资源单元,但并没有对资源做完全的隔离;
-
task和slot对应关系不确定,1个slot里可以运行多个task(都来自同一个Job的不同task的subtask允许共享slot,即share);
-
flink提供的默认资源配置很多时候无法满足要求
对此有几点建议:
- slot个数必须大于等于整个job的最大并行度,比如
source(3)->window(5)->sink(4)这个链路,其中source为3个并发,window为5个并发,sink为4个并发,则最大并行度为5,slot个数必须大于等于5才能让job调度起来; - kafka source的并行度应该和topic的分区个数对应来调整,一般要求并行度小于等于topic分区数,否则会存在空跑的task,浪费资源
- 尽可能地将 operator 的 subtask 链接(chain)在一起形成 task,每个 task 在一个线程中执行,可以减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
- 保证足够的并行度,但并行度也不是越大越好,太多会加重数据在多个solt/task manager之间数据传输压力,包括序列化和反序列化带来的压力。
- CPU资源是task manager上的solt共享的,注意监控CPU的使用。
反压和job重启
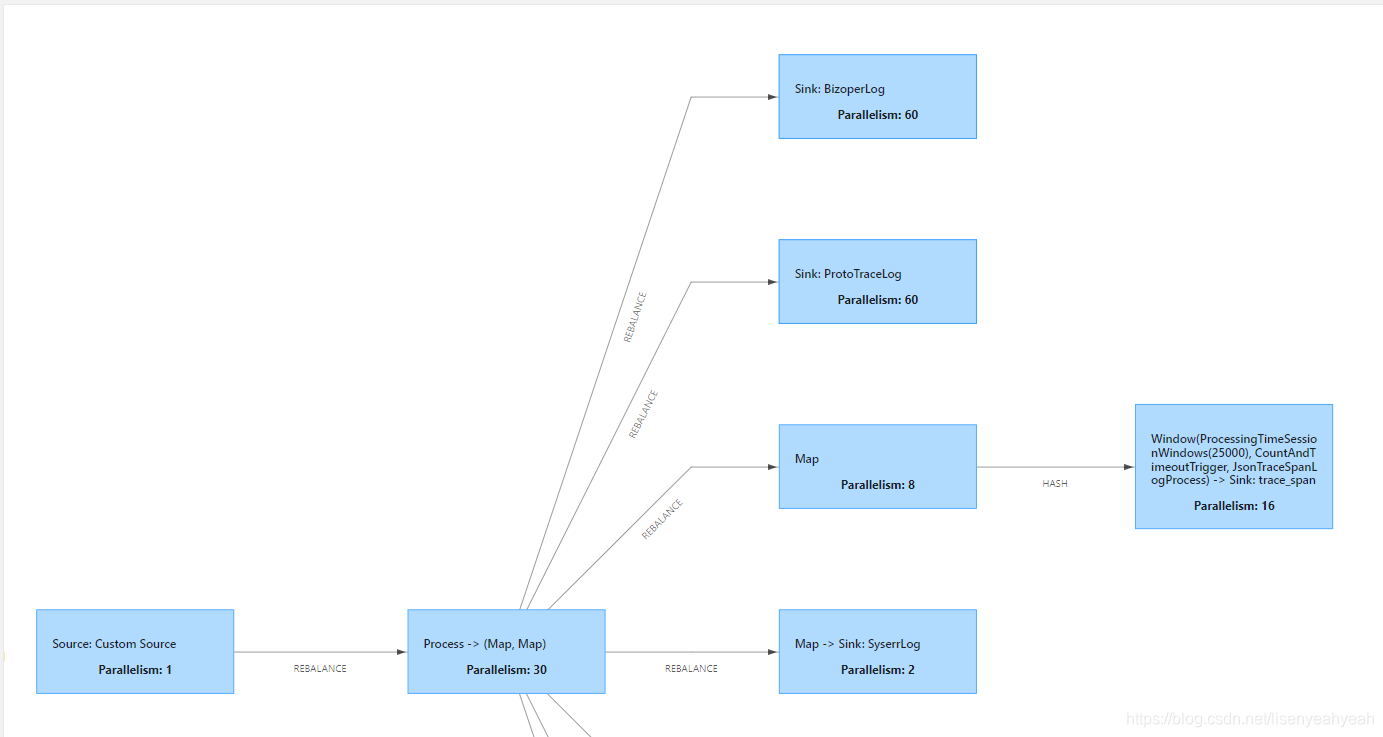
在flink standalone模式下运行job,从kafka读取数据发送到es,es版本为6.3.1,当并发度设置比较高的情况下,job运行一段时间后,出现严重反压,并且超过checkpoint超时时间(设置的10分钟)后job会重启,不断重启无法成功。
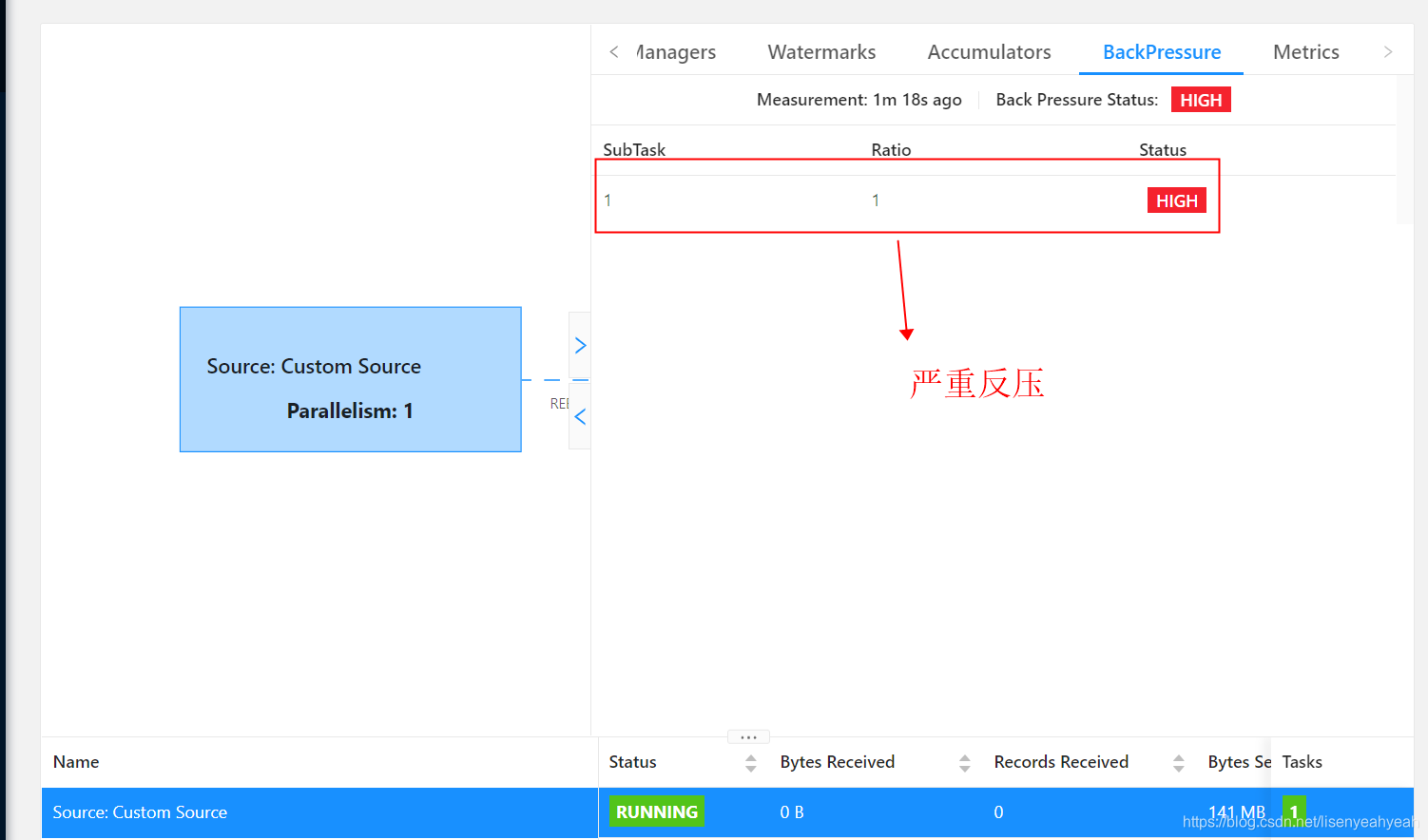
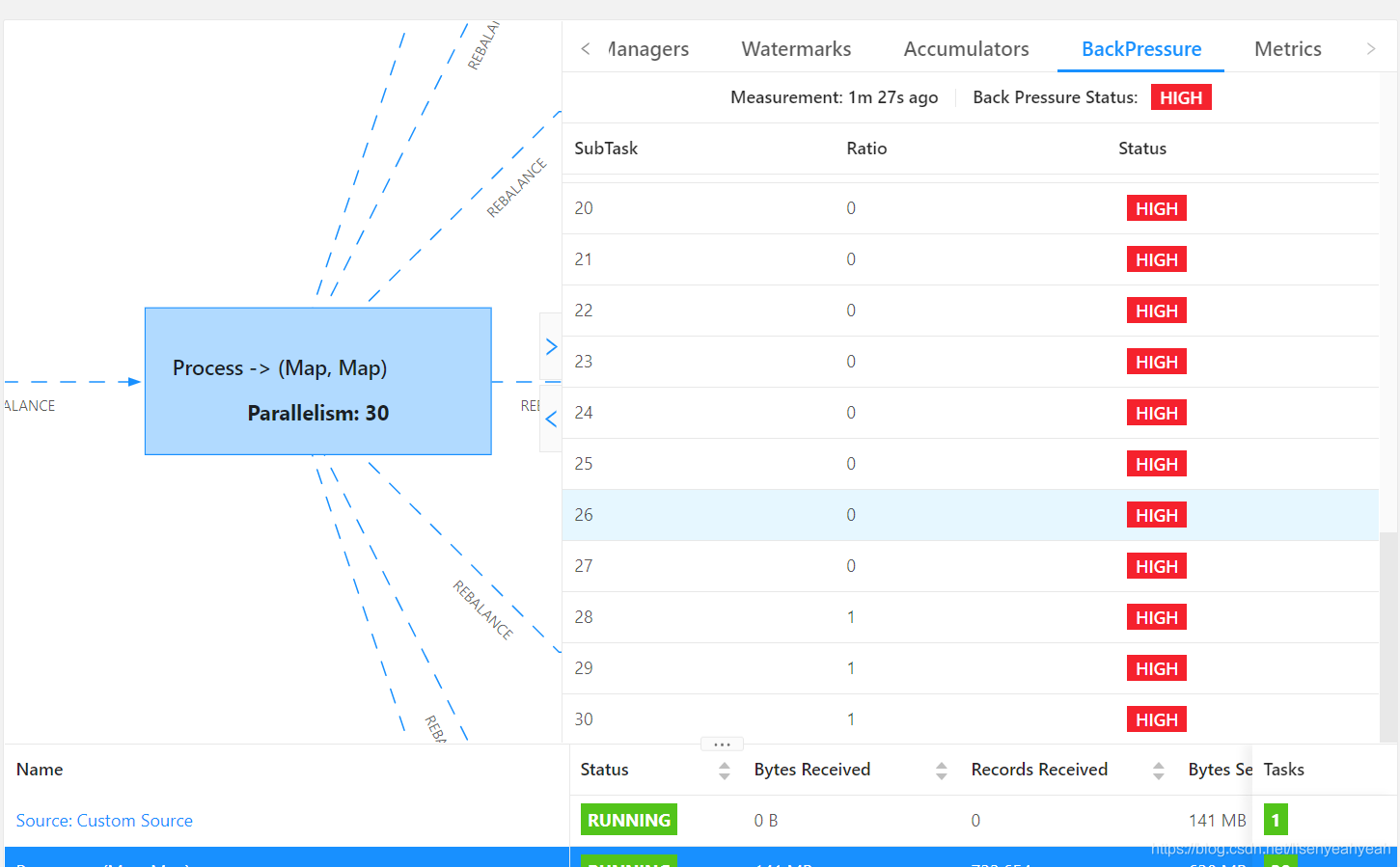
通过jstack查看堆栈信息发现大量BulkProcessor相关线程处于BLOCKED阻塞状态,查看Taskmanager日志,有did not react to cancelling signal for关键字,堆栈显示cancel job阻塞在BulkProcessor$Flush.run方法。
TaskManager堆栈信息:
"elasticsearch[scheduler][T#1]" Id=15008 BLOCKED on org.elasticsearch.action.bulk.BulkProcessor@61e178a6 owned by "Sink: ProtoTraceLog (39/60)" Id=8781
at org.elasticsearch.action.bulk.BulkProcessor$Flush.run(BulkProcessor.java:366)
- blocked on org.elasticsearch.action.bulk.BulkProcessor@61e178a6
at org.elasticsearch.threadpool.Scheduler$ReschedulingRunnable.doRun(Scheduler.java:182)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
...
Number of locked synchronizers = 1
- java.util.concurrent.ThreadPoolExecutor$Worker@15659a74
"Sink: ProtoTraceLog (39/60)" Id=8781 WAITING on java.util.concurrent.CountDownLatch$Sync@58bbbd7c
at sun.misc.Unsafe.park(Native Method)
- waiting on java.util.concurrent.CountDownLatch$Sync@58bbbd7c
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedInterruptibly(AbstractQueuedSynchronizer.java:997)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireSharedInterruptibly(AbstractQueuedSynchronizer.java:1304)
at java.util.concurrent.CountDownLatch.await(CountDownLatch.java:231)
at org.elasticsearch.action.bulk.BulkRequestHa 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2409
2409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









