




文章目录
Spark-SQL优化
前两篇文章Spark-SQL解析和Spark-SQL绑定讲到了Spark-SQL通过Antlr4生成未解析的LogicalPlan。然后通过Catalog来绑定UnresolvedRelation和UnresolvedAttribute,生成解析后的LogicalPlan。本篇文章主要讲如何将解析后的逻辑计划按照写好的规则进行优化,能够指导编译器选择效率最高的执行计划。
传统数据库(例如Oracle)的优化器有两种:基于规则的优化器(Rule-Based Optimization,RBO)和基于代价的优化器(Cost-Based Optimization,CBO)
RBO使用的规则是根据经验形成的,只要按照这个规则去写SQL语句,无论数据表中的内容怎样、数据分布如何,都不会影响到执行计划。
CBO是根据实际数据分布和组织情况,评估每个计划的执行代价,从而选择代价最小的执行计划。
目前Spark的优化器都是基于RBO的,已经有数十条优化规则,例如谓词下推、常量折叠、投影裁剪等,这些规则是有效的,但是它对数据是不敏感的。导致的一个问题就是数据表中数据分布发生变化时,RBO是不感知的,基于RBO生成的执行计划不能确保是最优的。而CBO的重要作用就是能够根据实际数据分布估算出SQL语句,生成一组可能被使用的执行计划中代价最小的执行计划,从而提升性能。目前CBO主要的优化点是Join算法选择。举个简单例子,当两个表做Join操作,如果其中一张原本很大的表经过Filter操作之后结果集小于BroadCast的阈值,在没有CBO情况下是无法感知大表过滤后变小的情况,采用的是SortMergeJoin算法,涉及到大量Shuffle操作,很耗费性能;在有CBO的情况下是可以感知到结果集的变化,采用的是BroadcastHashJoin算法,会将过滤后的小表BroadCast到每个节点,转变为非Shuffle操作,从而大大提高性能。
优化(Optimizer)
和Analyzer类似,Optimizer也是继承自RuleExecutor[LogicalPlan],所有和前一篇的套路是一样的,在batches中定义好优化规则,然后通过RuleExecutor的execute(plan: TreeType)方法来顺序执行规则。Optimizer还有一个子类SparkOptimizer,SparkOptimizer里面定义了四个规则加一个外部规则,可支持用户自己扩展规则。
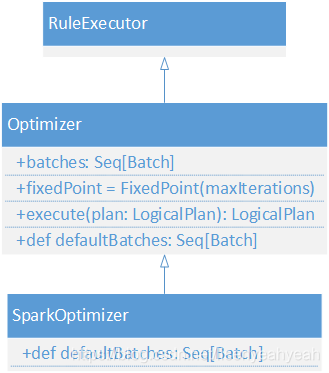
Optimizer的defaultBatches
def defaultBatches: Seq[Batch] = {
val operatorOptimizationRuleSet =
Seq(
// Operator push down
PushProjectionThroughUnion,
ReorderJoin,
EliminateOuterJoin,
...,
// Operator combine
CollapseRepartition,
CollapseProject,
CollapseWindow,
...)
val operatorOptimizationBatch: Seq[Batch] = {
val rulesWithoutInferFiltersFromConstraints =
operatorOptimizationRuleSet.filterNot(_ == InferFiltersFromConstraints)
Batch("Operator Optimization before Inferring Filters", fixedPoint,
rulesWithoutInferFiltersFromConstraints: _*) ::
Batch("Infer Filters", Once,
InferFiltersFromConstraints) ::
Batch("Operator Optimization after Inferring Filters", fixedPoint,
rulesWithoutInferFiltersFromConstraints: _*) :: Nil
}
}
SparkOptimizer的defaultBatches
override def defaultBatches: Seq[Batch] = (preOptimizationBatches ++ super.defaultBatches :+
Batch("Optimize Metadata Only Query", Once, OptimizeMetadataOnlyQuery(catalog)) :+
Batch("Extract Python UDFs", Once,
Seq(ExtractPythonUDFFromAggregate, ExtractPythonUDFs): _*) :+
Batch("Prune File Source Table Partitions", Once, PruneFileSourcePartitions) :+
Batch("Parquet Schema Pruning", Once, ParquetSchemaPruning)) ++
postHocOptimizationBatches :+
Batch("User Provided Optimizers", fixedPoint, experimentalMethods.extraOptimizations: _*)
根据defaultBatches的注释,常用的规则可以大致分为下推操作、合并操作、常量折叠和长度削减等。
一、Push Down
Filter下推:优化器可以将谓词过滤下推到数据源,从而使物理执行跳过无关数据。其实就是把查询相关的条件下推到数据源进行提前的过滤操作,之所以这里说是查询相关的条件,而不直接说是where 后的条件,是因为sql语句中除了where后的有条件外,join时也有条件。
Project下推:通常,嵌套查询中我们需要查询的字段主要以外层的为准,外层即父节点,内层即子节点,Project下推即将父节点的投影下推到子节点中,可以过滤掉一些不必要的字段。
1. PushProjectionThroughUnion(Union的Project下推)
在多个语句进行UNION时,将Project下推到多个语句分别执行。
object PushProjectionThroughUnion extends Rule[LogicalPlan] with PredicateHelper {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
// Push down deterministic projection through UNION ALL
case p @ Project(projectList, Union(children)) =>
assert(children.nonEmpty)
if (projectList.forall(_.deterministic)) {
val newFirstChild = Project(projectList, children.head)
val newOtherChildren = children.tail.map {
child =>
val rewrites = buildRewrites(children.head, child)
Project(projectList.map(pushToRight(_, rewrites)), child)
}
Union(newFirstChild +: newOtherChildren)
} else {
p
}
}
}
以下SQL的分析后的执行计划和优化后的执行计划对比:
select api from
(select api, bm_avg_visit_accumul from test
union all
select api1, bm_avg_visit_accumul1 from test1)
== Analyzed Logical Plan ==
api: string
Project [api#1]
+- SubqueryAlias `__auto_generated_subquery_name`
+- Union
:- Project [api#1, bm_avg_visit_accumul#5]
: +- SubqueryAlias `test`
: +- Relation[start#0,api#1,visit_accumul#2L,clientip_distinct_count#3L,max_batch_id#4L,bm_avg_visit_accumul#5] json
+- Project [api1#13, bm_avg_visit_accumul1#17]
+- SubqueryAlias `test1`
+- Relation[start#12,api1#13,visit_accumul#14L,clientip_distinct_count#15L,max_batch_id#16L,bm_avg_visit_accumul1#17] json
== Optimized Logical Plan ==
Union
:- Project [api#1]
: +- Relation[start#0,api#1,visit_accumul#2L,clientip_distinct_count#3L,max_batch_id#4L,bm_avg_visit_accumul#5] json
+- Project [api1#13]
+- Relation[start#12,api1#13,visit_accumul#14L,clientip_distinct_count#15L,max_batch_id#16L,bm_avg_visit_accumul1#17] json
2. EliminateOuterJoin(消除外连接)
将一些和内连接逻辑等价的外连接转化为内连接,可以过滤很多不需要的记录。
如果谓词可以限制结果集使得所有空的行都被消除:
full outer -> inner:如果两边都有这样的谓语
left outer -> inner:如果右边有这样的谓语
right outer -> inner:如果左边有这样的谓语
full outer -> left outer:仅仅左边有这样的谓语
full outer -> right outer:仅仅右边有这样的谓语
object EliminateOuterJoin extends Rule[LogicalPlan] with PredicateHelper {
/**
* Returns whether the expression returns null or false when all inputs are nulls.
*/
private def canFilterOutNull(e: Expression): Boolean = {
if (!e.deterministic || SubqueryExpression.hasCorrelatedSubquery(e)) return false
val attributes = e.references.toSeq
val emptyRow = new GenericInternalRow(attributes.length)
val boundE = BindReferences.bindReference(e, attributes)
if (boundE.find(_.isInstanceOf[Unevaluable]).isDefined) return false
val v = boundE.eval(emptyRow)
v == null || v == false
}
private def buildNewJoinType(filter: Filter, join: Join): JoinType = {
val conditions = splitConjunctivePredicates(filter.condition) ++ filter.constraints
val leftConditions = conditions.filter(_.references.subsetOf(join.left.outputSet))
val rightConditions = conditions.filter(_.references.subsetOf(join.right.outputSet))
lazy val leftHasNonNullPredicate = leftConditions.exists(canFilterOutNull)
lazy val rightHasNonNullPredicate = rightConditions.exists(canFilterOutNull)
join.joinType match {
case RightOuter if leftHasNonNullPredicate => Inner
case LeftOuter if rightHasNonNullPredicate => Inner
case FullOuter if leftHasNonNullPredicate && rightHasNonNullPredicate => Inner
case FullOuter if leftHasNonNullPredicate => LeftOuter
case FullOuter if rightHasNonNullPredicate => RightOuter
case o => o
}
}
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case f @ Filter(condition, j @ Join(_, _, RightOuter | LeftOuter | FullOuter, _)) = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1619
1619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









