




目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 腾讯混元开源HunyuanOCR轻量模型
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言:告别“多米诺骨牌”式的OCR流水线
在HunyuanOCR出现之前,传统的OCR系统更像一个多米诺骨牌游戏。一张图片进来,需要先经过文本检测、文本识别、版面分析、表格解析、公式识别等一系列独立的模型处理。这个链条上的任何一个环节出现微小偏差——比如,检测框偏了一个像素,版面顺序判断错了一行——后续的所有环节都会跟着出错,导致最终结果的崩盘。
虽然通用的多模态大模型能避免这个问题,但它们动辄几百上千亿的参数量,对于追求效率和低成本的OCR场景来说,无异于“杀鸡用牛刀”。HunyuanOCR的出现,正是为了解决这一核心矛盾。它没有在旧的流水线上修修补补,而是直接推倒重来,用“减法”的艺术,构建了一个简洁、高效且强大的新范式。

一、架构的“减法艺术”:三位一体的端到端设计
HunyuanOCR的整个系统被压缩为三个高度协同的核心组件,实现了从图像到结构化文本的直接输出,彻底根除了中间环节的误差累积。

(1)“鹰眼”——原生分辨率视觉编码器
这是模型的眼睛,基于`SigLIP-v2-400M`构建。它最大的特点是具备原生分辨率处理能力。传统的模型会粗暴地将所有输入图片缩放或裁剪到固定的尺寸,这对于一张长长的购物小票或宽幅的街景图来说是灾难性的,上面的微小文字会因此变得模糊不清。
HunyuanOCR采用自适应分块(Adaptive Patching)机制,像拼图一样,根据图像原始的宽高比将其智能地切分成多个小块。这种对原始信息的尊重,确保了任何角落的细节都不会丢失,为其精准识别打下了坚实的基础。
(2)“智能压缩机”——自适应MLP连接器
视觉编码器虽然看得清,但它输出的特征信息量巨大,如果直接全部喂给语言模型,会造成巨大的计算浪费(因为图片中有很多空白区域)。
这个自适应连接器就是视觉和语言之间的智能桥梁。它通过一种可学习的池化操作,能自动判断哪些区域是文本密集的“干货”,哪些是无关紧要的背景,然后进行智能压缩。这极大地缩短了后续语言模型需要处理的序列长度,是HunyuanOCR能在10亿参数规模下实现高效推理的关键。
(3)“空间感大脑”——轻量级语言模型
这是系统的大脑,基于`Hunyuan-0.5B`构建。普通语言模型只能理解一维的文本序列,但OCR任务中,文字在页面上的二维位置至关重要。
HunyuanOCR为此引入了创新的XD-RoPE技术。它将传统的位置编码分解,赋予了模型原生的空间理解能力。它不仅知道一个字是什么,还知道它在页面的哪个坐标(宽度、高度),甚至在视频的哪个时间点出现。这使得模型能天生看懂多栏排版、跨页逻辑,甚至能将流程图的结构关系直接转化为代码,这是其在复杂文档解析任务中脱颖而出的核心秘诀。
二、数据的“护城河”:真实与合成的双轮驱动
如果说精巧的架构决定了模型的上限,那高质量的数据则决定了它能走多远。HunyuanOCR团队构建了一个包含超过2亿图像-文本对的庞大数据“护城河”。
2.1 “数字孪生”——以假乱真的合成数据
为了让模型见多识广,特别是在处理罕见语言和复杂场景时,高质量的合成数据至关重要。团队基于`SynthDog`框架开发了一套强大的合成流水线,能做到:
(1)超广语言覆盖:支持超过130种语言的段落级渲染,包括从右到左书写的阿拉伯语等。
(2)模拟真实世界缺陷:通过扭曲合成流水线(Warping Synthesis Pipeline),模拟纸张的折痕、拍摄的透视变形、不均匀的光照和阴影等。经过这套“魔鬼训练”的数据,让模型在面对现实世界中各种不完美的图片时,依然能保持极高的鲁棒性。
2.2 “自动教练”——高效的VQA数据生产
对于信息提取、视觉问答这类高阶任务,高质量的标注数据非常稀缺。HunyuanOCR开发了一套自动化流水线,利用其他高性能大模型,专门针对低清晰度、复杂表格等“疑难杂症”图片,自动生成问答对,并通过多模型交叉验证来确保数据质量。这极大地提升了模型在语义理解层面的深度和精度。
三、训练的“杀手锏”:四阶段预训练与强化学习
拥有了好的架构和数据,还需要科学的训练方法来激发其全部潜力。
3.1 精心编排的“四重奏”训练法
HunyuanOCR的训练分为循序渐进的四个阶段,从基础的图文对齐,到全面的多任务学习,再到处理长文档的耐力训练,最后到面向实际应用的精调。这种由浅入深、由通用到专业的训练策略,确保了模型能力的全面发展,并最终能以规范的格式(如Markdown、JSON、LaTeX)输出结果,直接满足下游应用的需求。
3.2 点睛之笔——为OCR定制的强化学习
在完成预训练后,强化学习(RL)成为了提升模型性能的“点睛之笔”。团队创新地将通常用于大型推理模型的RL技术,应用到了这个轻量级OCR模型上,并设计了极其精细的奖励机制:
(1)对于检测识别:奖励函数同时考虑检测框的准确度(IoU)和文字内容的准确度(编辑距离),必须“框得准”且“认得对”才能得高分。
(2)对于翻译任务:引入大模型作为“裁判”进行0-5分的打分,让模型能感知翻译质量的细微差别,追求“信达雅”。
(3)严格的格式约束:在训练中,任何不符合预定义格式(如JSON)或超长的输出,都会被直接判为零分。这种强约束机制,迫使模型学会了生成稳定、可靠、可直接用于生产环境的结果。
四、超乎想象的实力:从看懂图表到代码生成
得益于上述设计,HunyuanOCR在实际应用中展现出了惊人的能力,远超传统“图片转文字”的范畴:

(1)图表理解:能直接“看懂”复杂的柱状图、折线图、箱线图,并自动将图表中的数据整理成结构化的Markdown表格。
(2)流程图转代码:能够理解流程图的逻辑结构,并直接输出对应的Mermaid代码,这对于文档自动化处理意义重大。
(3)高难度识别:无论是皱巴巴的发票、反光的街景,还是龙飞凤舞的艺术字体,都能实现精准识别。
(4)结构化提取:可以按照指令,从发票、卡证等图片中提取指定字段,并直接输出为标准的JSON格式,无缝对接到各类业务系统中。

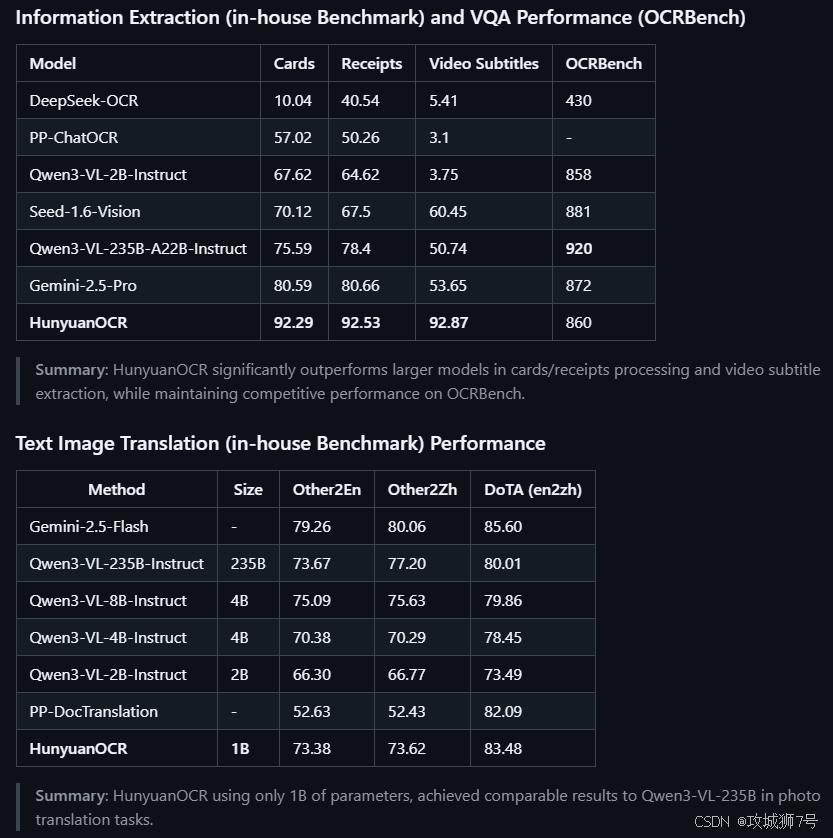
在多个权威基准测试中,仅1B参数的HunyuanOCR在文档解析、信息提取等多个核心任务上,其性能不仅远超同量级的开源模型,甚至击败了像Qwen3-VL-235B这样参数量为其200多倍的巨型模型。
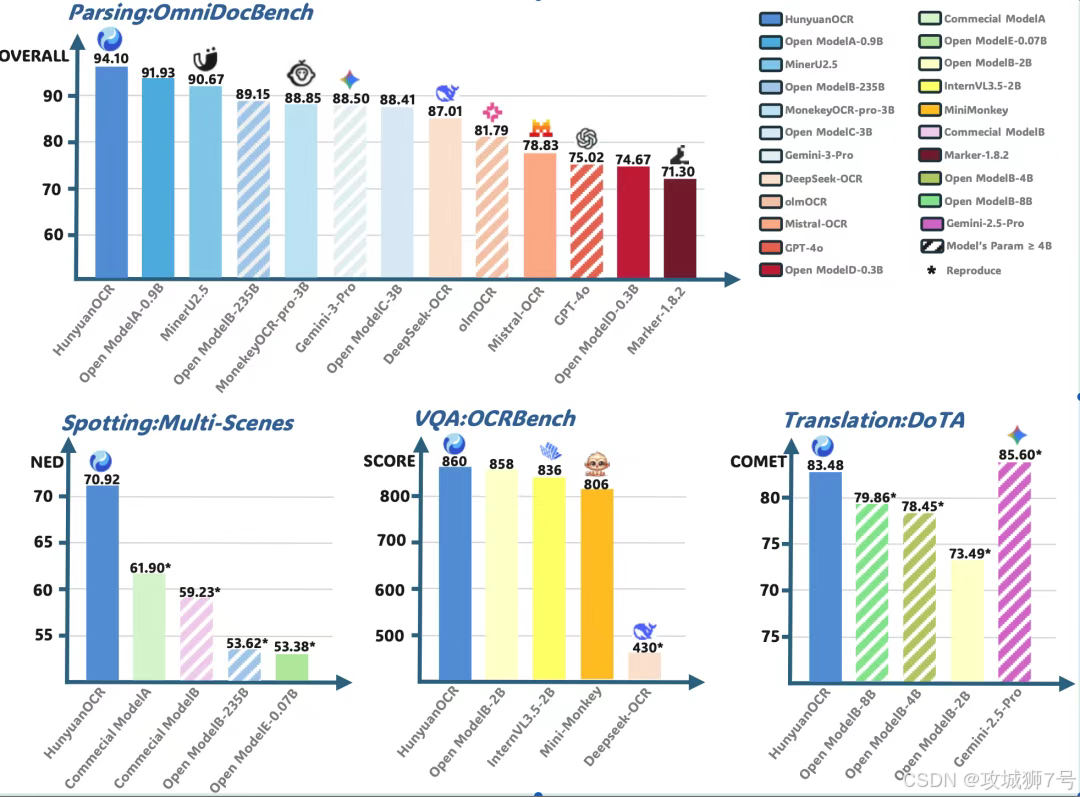
结论:OCR领域的新范式与新机遇
HunyuanOCR的成功,标志着OCR技术范式的一次重要跃迁。它证明了通过精巧的端到端架构设计、高质量的数据工程以及创新的训练策略,轻量级模型完全可以实现甚至超越传统复杂系统和通用大模型的性能。
它的开源(目前模型需要约20GB显存运行),为广大开发者和中小企业提供了一个前所未有的强大工具,极大地降低了使用商业级OCR技术的门槛。未来,无论是智能文档处理、自动化数据录入,还是与RAG系统的深度结合,HunyuanOCR都将成为一股不可忽视的推动力量。
相关链接
* GitHub: `https://github.com/Tencent-Hunyuan/HunyuanOCR`
* Hugging Face (含在线体验): `https://huggingface.co/tencent/HunyuanOCR`
* 技术论文: `https://arxiv.org/abs/2511.19575`
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 2614
2614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











