




在日常工作中,你是否遇到过这些困扰?扫描的PDF文档无法复制文字,手写笔记整理成电子档要逐字录入,多语言合同里的表格数据提取耗时又易错……现在,腾讯推出的HunyuanOCR模型,正以“轻量化+强性能”的组合,重新定义图文解析的效率与精度。
一、什么是混元OCR?用10亿参数实现“小模型大能力”
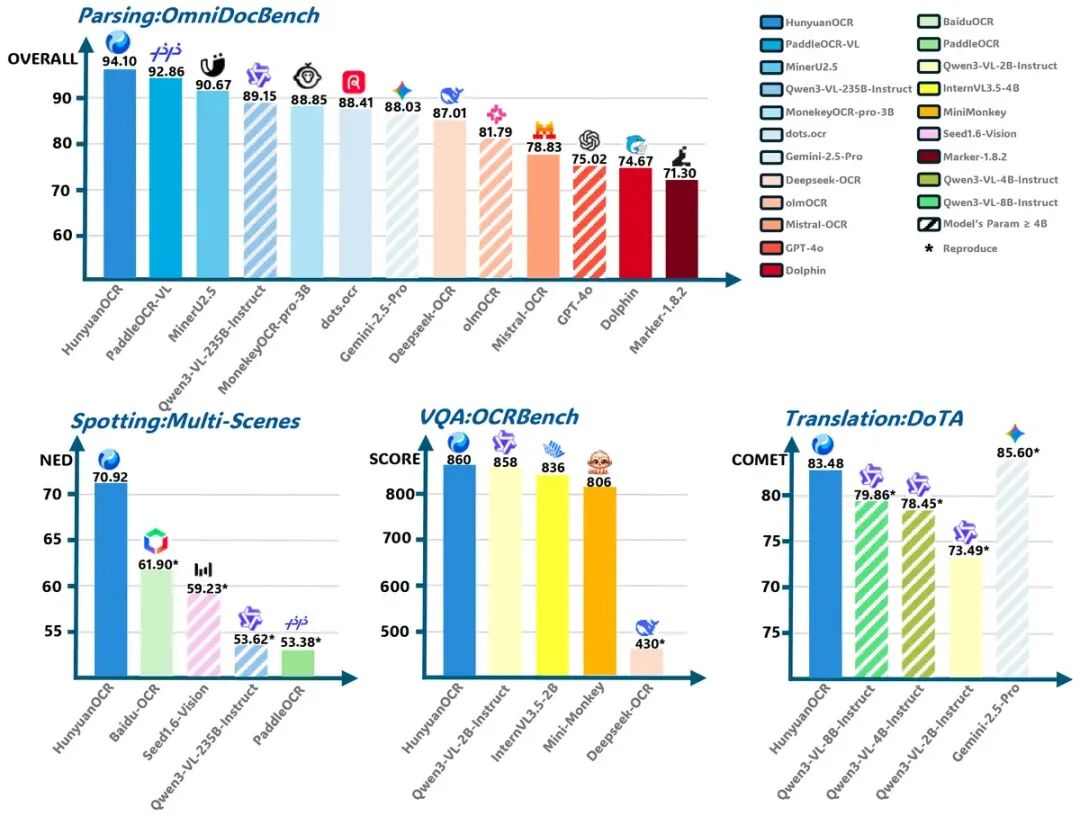
作为腾讯混元多模态体系下的专注OCR(光学字符识别)模型,HunyuanOCR最亮眼的标签是“轻量却能打”:仅10亿参数规模,却在行业权威 benchmark 中表现突出——在OmniDocBench文档解析任务中,以94.10的综合得分超越百度OCR、PaddleOCR-VL等主流模型,成为轻量化OCR领域的“性能黑马”。
它并非传统单一功能的OCR工具,而是具备“端到端图文理解” 能力的多模态模型:能同时处理图片中的文字、表格、公式、图表,甚至理解文档的排版逻辑,就像给计算机装上了“看懂图文的眼睛”。
二、5大核心能力,覆盖从日常到专业的全场景需求
无论是职场人的文档处理,还是开发者的技术集成,HunyuanOCR都能精准匹配需求,核心能力可概括为“5能”:
1. 文字检测和识别
HunyuanOCR 可以轻松实现对艺术字、街拍广告牌、截屏、广告、手写、票据中的文字完成识别,而且效果很好,如下图:
2. 复杂元素“智能拆解”
表格秒变可编辑格式:扫描件里的财务报表、实验数据表格,能直接解析为HTML格式,复制到Excel中无需二次调整;
公式精准转LaTeX:学术论文里的复杂公式,识别后自动生成LaTeX代码,插入论文文档时格式零误差;
图表逻辑“可视化还原”:流程图用Mermaid格式重现,折线图、柱状图用Markdown清晰呈现,省去重新绘图的麻烦。
这一点如果我们用编程方法,不借助AI来出来,会非常难的,很难兼顾多种情况,没想到HunyuanOCR也能处理的很好,如下图: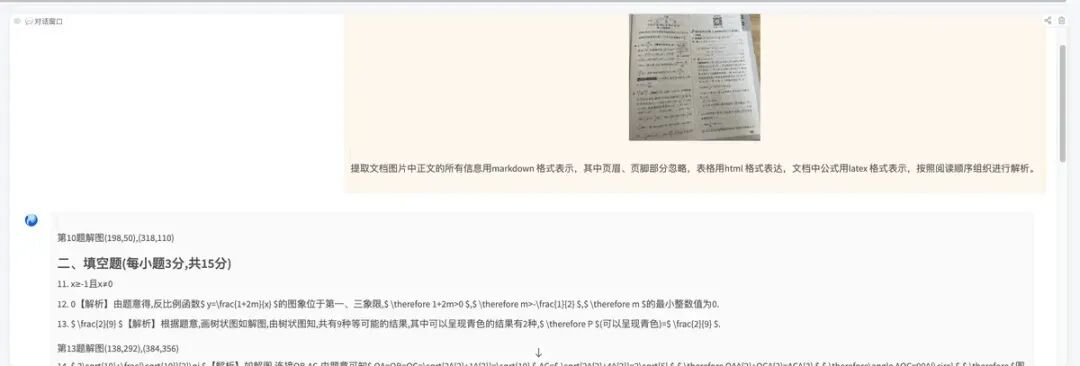
3. 发票信息抽取
大家工作中,一般出来回来,免不了要报销发票,那么发票的填写就是件头疼的事情,要一点点核对。害怕万一填写错了信息,又被财务打回来,来回折腾,大家都费事费力,通过HunyuanOCR,我们可以方便提取发票上信息,如下图:

4. 视频字幕“实时抓取”
刷海外教程、看多语言纪录片时,能提取视频帧中的字幕文本,还支持直接翻译为中文,兼顾“看视频”与“记笔记”双重需求。

5. 轻量化部署“灵活高效”
10亿参数的小巧体型,让它既能在云端提供高并发服务,也能适配边缘设备部署,开发者无需复杂配置,就能快速集成到APP、小程序或办公软件中。
三、2分钟上手!两种便捷使用方式
普通用户和开发者都能轻松玩转混元OCR,官方提供两种快速启动方案:
方案1:用Transformers快速调用
只需3步,就能实现文档信息提取:
安装依赖:
pip install git+https://github.com/huggingface/transformers@82a06db03535c49aa987719ed0746a76093b1ec4编写代码,上传图片并写指令,比如“提取文档正文,表格用HTML、公式用LaTeX表示”;
from transformers import AutoProcessor
from transformers import HunYuanVLForConditionalGeneration
from PIL import Image
import torch
def clean_repeated_substrings(text):
"""Clean repeated substrings in text"""
n = len(text)
if n<8000:
return text
for length in range(2, n // 10 + 1):
candidate = text[-length:]
count = 0
i = n - length
while i >= 0 and text[i:i + length] == candidate:
count += 1
i -= length
if count >= 10:
return text[:n - length * (count - 1)]
return text
model_name_or_path = "tencent/HunyuanOCR"
processor = AutoProcessor.from_pretrained(model_name_or_path, use_fast=False)
img_path = "path/to/your/image.jpg"
image_inputs = Image.open(img_path)
messages1 = [
{"role": "system", "content": ""},
{
"role": "user",
"content": [
{"type": "image", "image": img_path},
{"type": "text", "text": (
"检测并识别图片中的文字,将文本坐标格式化输出。"
)},
],
}
]
messages = [messages1]
texts = [
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
for msg in messages
]
inputs = processor(
text=texts,
images=image_inputs,
padding=True,
return_tensors="pt",
)
model = HunYuanVLForConditionalGeneration.from_pretrained(
model_name_or_path,
attn_implementation="eager",
dtype=torch.bfloat16,
device_map="auto"
)
with torch.no_grad():
device = next(model.parameters()).device
inputs = inputs.to(device)
generated_ids = model.generate(**inputs, max_new_tokens=16384, do_sample=False)
if "input_ids" in inputs:
input_ids = inputs.input_ids
else:
print("inputs: # fallback", inputs)
input_ids = inputs.inputs
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(input_ids, generated_ids)
]
output_texts = clean_repeated_substrings(processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
))
print(output_texts)运行代码,秒级得到结构化输出,还能自动清理重复文本,避免冗余。
方案2:用vLLM提速推理
如果需要处理大量图片,可通过vLLM实现高效推理: 安装vLLM后,配置采样参数(如temperature=0确保输出稳定),单次可处理多帧图片,适合视频字幕提取、批量文档解析等场景。
安装
uv venv hunyuanocr
source hunyuanocr/bin/activate
uv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly部署模型
vllm serve tencent/HunyuanOCR \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--gpu-memory-utilization 0.2代码测试
from vllm import LLM, SamplingParams
from PIL import Image
from transformers import AutoProcessor
def clean_repeated_substrings(text):
"""Clean repeated substrings in text"""
n = len(text)
if n<8000:
return text
for length in range(2, n // 10 + 1):
candidate = text[-length:]
count = 0
i = n - length
while i >= 0 and text[i:i + length] == candidate:
count += 1
i -= length
if count >= 10:
return text[:n - length * (count - 1)]
return text
model_path = "tencent/HunyuanOCR"
llm = LLM(model=model_path, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_path)
sampling_params = SamplingParams(temperature=0, max_tokens=16384)
img_path = "/path/to/image.jpg"
img = Image.open(img_path)
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": [
{"type": "image", "image": img_path},
{"type": "text", "text": "检测并识别图片中的文字,将文本坐标格式化输出。"}
]}
]
prompt = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = {"prompt": prompt, "multi_modal_data": {"image": [img]}}
output = llm.generate([inputs], sampling_params)[0]
print(clean_repeated_substrings(output.outputs[0].text))四、为什么选混元OCR?3个核心优势脱颖而出
在众多OCR工具中,混元OCR的竞争力主要来自三点:
性能与效率平衡:比同参数模型精度更高,比高精度大模型(如Qwen3-VL-235B)部署成本更低;
场景适配性强:从日常的身份证、发票识别,到专业的学术论文、工程图纸解析,都能应对;
开发者友好:开源在Hugging Face平台,提供完整的调用代码、应用场景Prompt模板(如文字定位、信息提取、翻译等),降低开发门槛。
目前,混元OCR已在腾讯内部多个业务场景落地,并通过Hugging Face向全球开发者开放。无论是想提升个人办公效率,还是为产品添加图文解析功能,都可以直接访问模型官网获取资源。
未来,随着多模态技术的发展,OCR或许会从“提取信息”升级为“理解意图”——比如自动根据合同条款生成风险提示,根据报表数据生成分析结论。而混元OCR,已经走在了这条探索的前列。
涉及链接:
模型地址:https://huggingface.co/tencent/HunyuanOCR
vllm部署混元OCR指南:https://docs.vllm.ai/projects/recipes/en/latest/Tencent-Hunyuan/HunyuanOCR.html#installing-vllm
直接体验地址:https://huggingface.co/spaces/tencent/HunyuanOCR


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









