




目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 华为开源UCM
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在人工智能的浪潮席卷全球的今天,我们惊叹于大模型强大的对话、编程和创作能力。但在这背后,一个极其现实的问题正日益凸显:运行这些AI,实在是太“烧钱”了。
这个成本的核心,集中在“推理”阶段——也就是AI响应你的每一个问题、生成每一段文字时所消耗的计算资源。尤其是在处理长篇报告、进行多轮复杂对话时,AI的“思考”过程会变得异常缓慢且昂贵。
而这一瓶颈的根源,很大程度上指向了一种名为HBM(High-Bandwidth Memory,高带宽内存)的高性能硬件。它就像AI进行推理时使用的一张“草稿纸”,速度极快但面积(容量)有限且价格昂贵。更关键的是,其供应链被少数国外厂商垄断,这给国内AI产业的发展带来了巨大的成本压力和供应链风险。
面对这一行业痛点,华为给出了一份创新的答卷——正式发布并开源了其AI推理创新技术UCM(Unified Cache Manager,推理记忆数据管理器)。它并非试图用更强的硬件去硬碰硬,而是用一套更聪明的“数据管理哲学”,为AI推理的降本增增效开辟了一条新路。
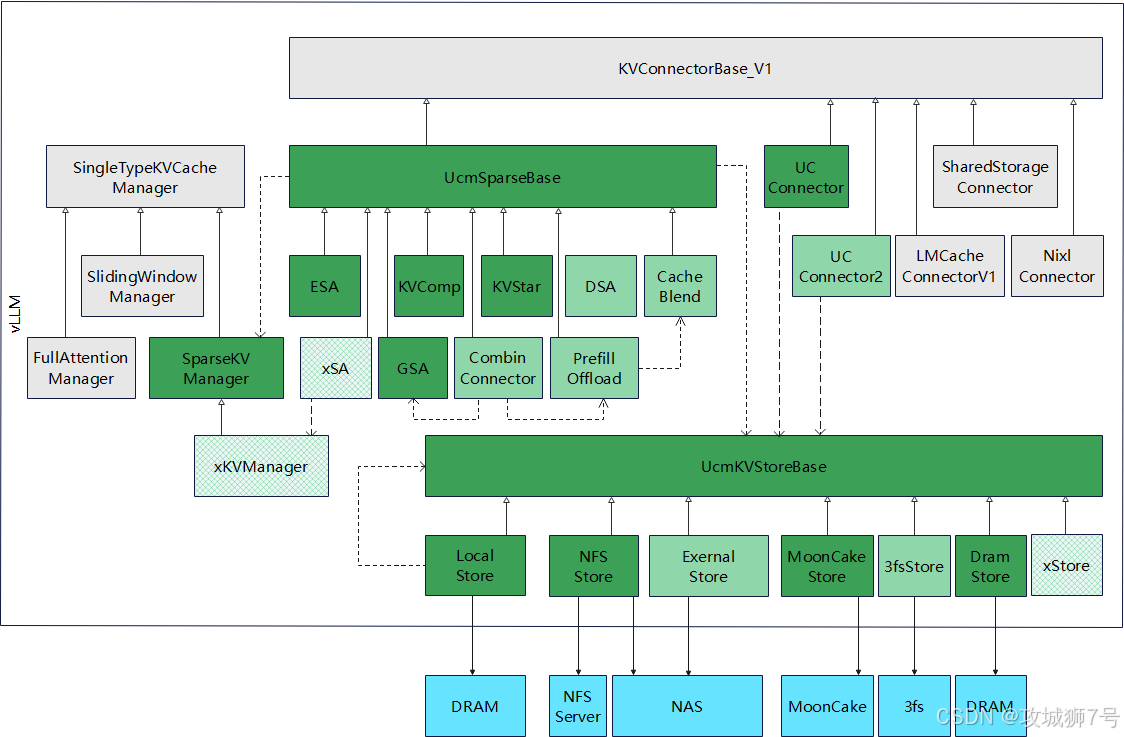
( UCM架构图:图中所有灰色框代表vLLM 0.9.2版本中的现有类,绿色框则代表UCM新增组件。浅绿色框展示了基于此框架未来规划扩展的子类。)
一、AI的“昂贵记忆”:什么是KV Cache?
要理解UCM的价值,我们首先需要了解AI推理时最占地方的是什么。答案是“KV Cache”(键值缓存)。
你可以把它通俗地理解为AI在与你对话时的“短期记忆”。当你问AI一个问题,它会记住你问题的关键信息(Key)和它需要关注的上下文(Value)。随着对话一轮一轮地进行,这个“短期记忆”会像滚雪球一样越来越大。处理一篇长达17万Token的会议纪要,这个KV Cache甚至会膨胀到数百GB。
这张“草稿纸”需要被AI极快地反复读写,因此它必须被存放在最快的内存——也就是GPU芯片上集成的HBM里。问题来了:HBM不仅贵,而且容量非常有限。当KV Cache大到HBM装不下时,系统就会频繁溢出,导致推理中断或变得极慢,严重影响用户体验。
二、华为UCM的解法:给AI的“记忆”分个三六九等
UCM的核心思想,并非是去制造更大、更快的HBM,而是像一个高明的图书管理员一样,对AI的“记忆数据”(KV Cache)进行智能化的分级管理。
如果把HBM比作你办公桌上最顺手、但空间有限的区域,那么UCM的作用就是建立了一个层次分明的智能存储系统:
(1)热数据(Hot Data)-> 留在HBM(办公桌):对于AI当前对话最核心、访问最频繁的记忆数据,UCM会将其保留在速度最快的HBM中,确保最快的响应。
(2)温数据(Warm Data)-> 移到DRAM(身后的书架):对于那些不是立刻要用,但可能很快会再次访问的数据,UCM会智能地将其“卸载”到容量更大、成本更低的服务器内存(DRAM)中。
(3)冷数据(Cold Data)-> 沉降至SSD(档案室):对于那些很久没用过的历史对话记忆,UCM会将其进一步移动到容量最大、成本最低的固态硬盘(SSD)里。
通过这套“热、温、冷”数据的自动分级和迁移机制,UCM极大地释放了宝贵的HBM空间,使其能专注于处理最关键的任务。根据华为的数据,在部分工作负载中,对HBM的依赖度最高可降低80%。这意味着,数据中心可以用成本更低的内存方案,来高效地运行大模型。
三、不止是分级:一套协同工作的系统
UCM并非一个单一的算法,而是一套由三大核心组件协同工作的推理加速套件:
(1)推理引擎插件 (Connector):负责“对接”,让UCM能够无缝接入业界主流的各种推理框架和AI算力。
(2)功能库 (Accelerator):这是UCM的“大脑”,内部集成了多级缓存管理、稀疏注意力等多种加速算法,负责执行智能的数据分级和计算优化。
(3)存取适配器 (Adapter):负责“传输”,确保数据在HBM、DRAM、SSD等不同存储介质之间能够被高性能地存取。
这三大组件通过推理框架、算力、存储的三层协同,实现了AI推理在体验和成本上的双重优化。
四、性能飞跃:数据见证实力
UCM技术带来的性能提升是实实在在的。根据华为公布的测试数据:
(1)首Token时延最高降低90%:AI的“第一反应”速度,即从接收问题到吐出第一个字的延迟,最多可降低90%。这意味着用户能更快地得到响应。
(2)系统吞吐最大提升22倍:在同等硬件条件下,系统能同时处理的用户请求数量,最多可提升22倍。
(3)上下文窗口扩展10倍:AI能“记住”的对话历史长度,实现了10倍级别的扩展,解决了以往模型处理超长文本时“推不动”的难题。
在与科大讯飞合作的MoE(专家混合)模型推理中,UCM技术将推理吞吐提升了3.2倍,端到端时延降低了50%。
更具说服力的是在金融领域的试点应用。在中国银联的“客户之声”业务中,UCM将大模型推理速度提升了125倍,仅需10秒就能精准识别客户高频问题。在“营销策划”场景中,过去需要数分钟生成的方案,现在也被缩短至10秒以内。
五、战略意义:填补生态短板,开源助力产业腾飞
UCM的发布,其意义已经超越了技术本身,对整个国产AI生态的建设具有里程碑式的意义。
首先,它填补了国产AI推理生态中的关键一环。在美国对HBM2e及以上规格芯片实施出口管制的背景下,UCM通过降低对HBM的依赖,为中国AI产业的自主创新和发展提供了强大的技术底座和战略缓冲。
其次,华为选择将UCM正式开源。这一举措,旨在构建一个开放、兼容、自主可控的国产AI推理生态。通过开放统一的接口,UCM可以适配多类型的推理引擎、算力及存储系统。这将吸引更多的开发者、厂商和生态伙伴参与进来,共同推动技术的迭代和优化,最终形成“体验提升—用户增长—投资加大—技术迭代”的良性商业循环。
结语
华为UCM技术的出现,标志着AI推理领域的一个重要转变:从单纯依赖更强硬件的“蛮力”竞争,转向依靠更优架构和算法的“巧劲”竞争。
它不仅是一次技术上的重大突破,更是在当前国际环境下,一次意义深远的战略布局。通过开源这把“利剑”,华为正在为中国AI产业的长远发展注入源源不断的动力,帮助整个生态在全球AI的竞争舞台上,占据更有利的位置。
GitCode开源地址:
https://gitcode.com/ModelEngine/unified-cache-management
Github开源地址:
https://github.com/ModelEngine-Group/unified-cache-management
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











