




目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 阶跃星辰开源的音频编辑大模型Step-Audio-EditX
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
引言:我们受够了没有感情的 AI 语音
“您好,您的话费余额已不足,请及时充值。”
这句我们再熟悉不过的语音提示,完美地概括了过去 AI 语音给我们留下的印象:字正腔圆、清晰标准,但毫无生气,像一个永远不会疲倦的机器。在过去的几年里,AI 技术飞速发展,AI 绘画已经能创作出以假乱真的艺术品,AI 视频生成也开始崭露头角,但在音频领域,我们似乎还在与“机械感”作斗争。
问题出在哪里?传统的音频编辑和生成,是一个高度技术化的过程。专业人士需要在 Adobe Audition 或 Pro Tools 这样的软件中,面对着复杂的波形图和数不清的参数滑块,像雕刻艺术品一样,一点点地调整音调、节奏、混响。这个门槛,将绝大多数普通创作者拒之门外。
而阶跃星辰(StepFun AI)近期开源的 “Step-Audio-EditX”模型,正是要拆掉这堵高墙。它的核心理念简单而颠覆:如果编辑图片可以用“一句话出图”,那么编辑音频,为什么不能用“一句话调音”?
这个模型的出现,让 AI 语音终于开始摆脱“没有感情的朗读者”这一刻板印象,学会了“察言观色”,学会了用声音表达喜怒哀乐。

一、Step-Audio-EditX 是什么?
想象一下,你正在为你的播客或短视频制作配音,但对其中一句话的语气不满意。在过去,你可能需要说服自己“就这样吧”,或者硬着头皮重新录制一遍。现在,有了 Step-Audio-EditX,你可以像给演员讲戏一样,直接下达指令:
(1)对一段平淡的录音,输入指令:“让这句话听起来愤怒一点”。
(2)想让气氛变得俏皮,输入:“用撒娇的风格重说一遍”。
(3)觉得一句话结尾太空洞,输入:“在句末加上一声叹息”。
(4)甚至,你可以直接在文本前加上 `[四川话]` 或 `[粤语]` 标签,让 AI “秒切”方言。
这就是 Step-Audio-EditX 的核心魔力:将复杂的音频参数调节,转化为了直观的自然语言指令。
它不仅仅能从零开始生成语音(Text-to-Speech, TTS),更强大的能力在于“编辑”。它支持:
(1)情感编辑:涵盖开心、悲伤、愤怒、兴奋、恐惧等十几种情绪,并且可以“迭代”增强。觉得不够悲伤?那就再来一次“更悲伤”的指令。
(2)风格编辑:无论是模仿老人、小孩,还是切换到耳语、夸张的戏剧腔,都能轻松实现。
(3)副语言插入:这是让声音“活”起来的关键。呼吸、笑声、叹气、惊讶声(oh/ah)、确认(en)等 10 种自然的副语言元素,可以像插入标点符号一样,精确地添加到语音的任意位置。
更重要的是,它具备强大的“零样本语音克隆”能力。你只需要提供一小段目标人物的音频(几秒钟即可),模型就能“学会”这个人的音色,然后用这个音色去说任何你想让它说的话,并且还能叠加以上所有的情感和风格编辑。
最关键的是,这一切都是开源的。它遵循 Apache 2.0 协议(对商业使用友好),并且对硬件要求相对亲民,官方称单张 12GB 显存的消费级 GPU 就能运行。这意味着,无论是独立开发者、小型工作室还是大型企业,都可以免费地将其集成到自己的产品中,一个全新的音频应用生态呼之欲出。
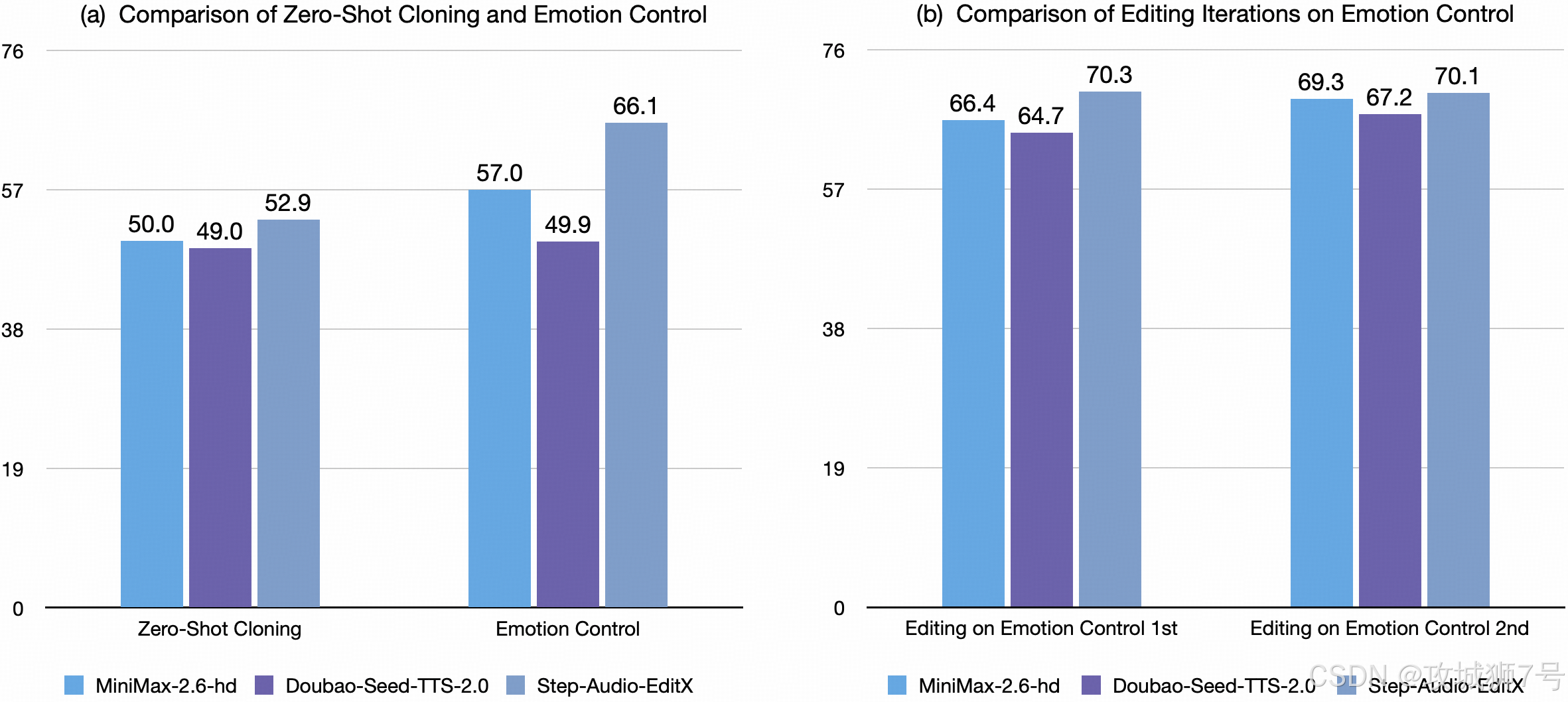
与闭源模型对比
二、它是如何做到的?“左右互搏”式的聪明训练法
用文字控制如此精细的声音属性,听起来像是魔法。这背后的技术原理,虽然复杂,但其核心思想却异常巧妙。我们可以称之为“大边距数据驱动”法,或者通俗地讲,是一种“左右互搏”式的训练。
传统的 AI 模型在学习解耦声音属性(比如把“音色”和“情感”分开)时,往往需要设计复杂的模块,像是在机器内部建造精密的隔离墙,成本高且效果不佳。
Step-Audio-EditX 另辟蹊径。它不纠结于模型内部的“结构隔离”,而是从“数据喂养”上着手。它的训练方式是这样的:
研究人员让模型去听大量的“对比样本对”。每一对样本,说的文字内容完全一样,但情感或风格却截然相反。比如:
* 用“极度开心”的语气说:“今天天气真好。”
* 用“极度悲伤”的语气说:“今天天气真好。”
通过海量地学习这种“大边距”(Large-margin)数据,模型被迫去思考一个问题:“既然文字一模一样,那是什么造成了听感的巨大差异?” 答案,就是情感和风格本身。
这种训练方法,就像教一个孩子分辨冷热。你不需要向他解释分子运动的原理,只需要让他摸一下冰块,再感受一下热水,他就能通过巨大的体感差异,瞬间理解“冷”和“热”的概念。
Step-Audio-EditX 就是通过这种方式,在没有额外复杂模块的情况下,聪明地学会了将情感、风格从语音内容中解耦出来,并将其与特定的文字指令(如“开心”、“悲伤”)关联起来。
整个系统的技术架构也顺应了这一思路,由三个简洁的部分组成:

(1)音频分词器:把听到的声音波形,翻译成 AI 能理解的“语音文字”(离散 Token)。
(2)音频大语言模型(Audio LLM):这是一个 30 亿参数的大脑,负责理解你的文字指令和输入的“语音文字”,然后规划出修改后的新“语音文字”序列。
(3)音频解码器:将这个新的“语音文字”序列,再翻译回我们能听到的声音波形。
整个流程一气呵成,在一个统一的框架内完成了所有任务,无论是从零生成还是编辑,都遵循这一管线,大大降低了系统的复杂度和推理成本。
三、这为什么是一个重要的进步?
Step-Audio-EditX 的出现,其意义远不止于一个好玩的开源工具。
(1)音频创作的民主化:它将专业级的音频编辑能力,下放给了每一个普通人。播客主可以轻松丰富自己节目的情感色彩,视频博主可以低成本制作多角色的配音,甚至普通用户也可以为自己的有声日记增添情绪。创作的瓶颈,将不再是技术,而是创意本身。
(2)人机交互的“升温”:冰冷的智能客服和语音助手,一直以来都是用户体验的痛点。通过 Step-Audio-EditX 的技术,未来的客服机器人可以在感知到用户焦虑时,用更“安抚”的语气回应;导航软件在播报堵车信息时,可以带上一丝“同情”。这让人机交互变得更温暖、更人性化。
(3)对行业的“范式冲击”:它证明了,在 AI 时代,解决复杂问题的思路正在转变。过去那种依赖专家知识、设计精巧模块的“流水线”式方法,正在被基于海量数据、由大模型自主学习的“端到端”方法所取代。从图像到视频,再到今天的音频,“用自然语言 Vibe 一切”的趋势已然不可阻挡。
四、应用场景:从有声书到虚拟偶像
这项技术的应用前景几乎是无限的,文档中也列举了几个极具想象力的方向:
(1)有声内容升级:一键为有声书、新闻朗读赋予情感,甚至可以为不同角色快速克隆和切换音色,让一个人就能演一台“广播剧”。
(2)游戏与虚拟偶像:为游戏 NPC 或 VTuber 注入灵魂。不再是重复几句预设的台词,而是可以根据与玩家的互动,实时生成带有笑声、呼吸、叹息的鲜活语音。
(3)教育与语言学习:生成不同年龄、风格的读音,帮助语言学习者模仿。或者将标准普通话,一键切换为粤语、四川话进行跟读练习。
(4)会议与无障碍:自动对会议录音进行“降噪”和“静音修剪”,然后生成清晰、流畅的会议纪要音频,造福所有参会者,尤其是听障人士。
结论:声音的未来,始于“共情”
Step-Audio-EditX 的开源,是 AI 音频领域的一个里程碑。它不仅在技术上展示了“大边距数据驱动”这一方法的强大潜力,更重要的是,它在理念上指明了方向:未来音频技术的核心竞争力,将不再是单纯的“拟真”,而是“共情”与“可控”。
我们追求的,不再是让 AI 说话像一个完美无瑕的播音员,而是希望它能像一个真正的同伴,能理解我们的意图,能表达细腻的情感,能用声音传递温度。
当然,强大的技术也伴随着伦理的挑战,尤其是“零样本语音克隆”可能被滥用于身份冒用和欺诈。开发团队也在项目主页明确提醒了相关风险,这需要整个社区共同建立规范,确保技术向善。
总而言之,Step-Audio-EditX 打开了一扇通往未来的大门。在这扇门后,声音不再是固定的波形,而是一种可以被语言自由塑造的流体。我们每个人,都有可能成为自己声音世界的“导演”。
GitHub地址:
https://github.com/stepfun-ai/Step-Audio-EditX
在线Demo地址:
https://stepaudiollm.github.io/step-audio-editx/
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!




















 1529
1529









 到【灌水乐园】发言
到【灌水乐园】发言









