




目录
2.4 DeepSeek V3.1:“思考者”与“行动派”合体

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 DeepSeek主动公开大模型训练细节
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
2025年9月,中国AI行业迎来了一个标志性事件。随着国家《人工智能生成合成内容标识办法》的正式生效,各大AI公司纷纷开始为自家模型生成的内容打上“AI生成”的标签。在这波浪潮中,国内的头部玩家DeepSeek(深度求索)不仅迅速响应,还做出了一个让业界颇为震动的决定——主动公开其核心大模型(从V2到V3.1)的《模型原理与训练方法说明》。
这相当于一位顶级魔术师,不仅承认了自己在表演魔术,还把魔术的部分诀窍写下来公之于众。在技术壁垒森严的AI领域,此举非同寻常。DeepSeek的这份文档,为我们提供了一个绝佳的窗口,去窥探一个顶尖AI“大脑”是如何被一步步“炼成”的,以及它在进化过程中都经历了哪些关键的“思想蜕变”。
今天,我们就以这份官方文档为蓝本,结合行业背景,深入浅出地聊一聊,DeepSeek究竟公开了什么?一个强大的AI模型是如何从零开始,逐步学会思考、推理,乃至成为一个“智能体”的?
一、AI的“义务教育”与“高等教育”
理解AI先看其“学习”过程,DeepSeek将其分为预训练和优化训练(微调) 两阶段,可通俗理解为AI的“义务教育”与“高等教育”。
1.1 预训练:读万卷书,认识世界
这是AI的“义务教育”,目标是让模型建立世界基本认知,掌握语言规律与海量背景知识。
“教材”分两类:互联网公开网页、文档,及合作授权数据。模型通过自监督学习海量阅读,默默掌握词语搭配、句子构成与知识关联。
此阶段有两个关键:
- 规模定下限:DeepSeek V3参数量达6850亿,所需数据量远超人类一生阅读量;
- “洗数据”关键:剔除仇恨、色情等不良信息,筛查隐私,确保“教材”干净安全。
预训练后,模型“博览群书”却显青涩——能写通顺句子、懂不少事实,但不会“好好说话”、精准答题,也不懂人类价值观,需进入“高等教育”阶段。
1.2 优化训练(微调):学以致用,融入社会
这是AI的“高等教育”,目标是教模型运用知识,以符合人类期望的方式交流、完成任务。
“教材”不再是海量互联网文本,而是人类精心标注的“高质量问答对”,像给AI请“私教”。
DeepSeek主要用两种“教学方法”:
- 有监督微调(SFT):给模型看大量“标准答案”,让其模仿学习;
- 强化学习(RL):模型尝试答题后,由人类或其他模型打分(奖惩),模型持续调整以得高分(如DeepSeek R1用的GRPO算法)。
经此“特训”,模型从“知识库”变身“善解人意的对话伙伴”——会遵指令、拒不当请求,还能激发编程、数学等专业能力。值得一提的是,若用用户输入构造训练数据,DeepSeek会严格匿名化,并允许用户选择退出,体现对隐私的重视。
二、DeepSeek模型进化史:从V2到V3.1的技术跃迁
了解训练流程后,再看DeepSeek的进化——不止是版本更迭,更是“思考”能力与效率的本质飞跃。
2.1 DeepSeek V2:奠定基础的“记忆优化大师”
作为技术基石,V2引入两大核心架构:DeepSeekMoE(混合专家模型,节约算力)和MLA(多头潜在注意力)。MLA通过压缩KV缓存(临时记忆区),解决大模型长文本记忆效率问题,减少内存占用、提升速度,为后续处理128k+长上下文打下基础。
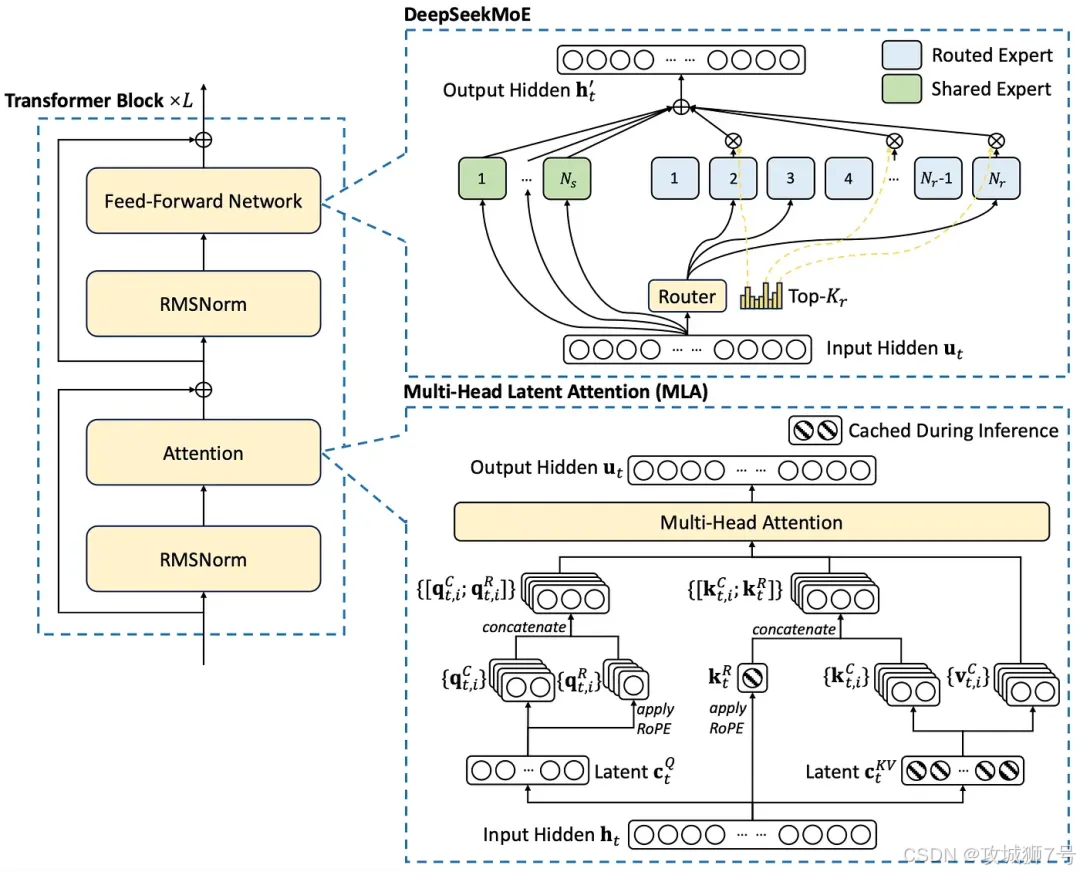
2.2 DeepSeek V3:极致效率的“训练加速器”
继承V2架构,两项关键升级:
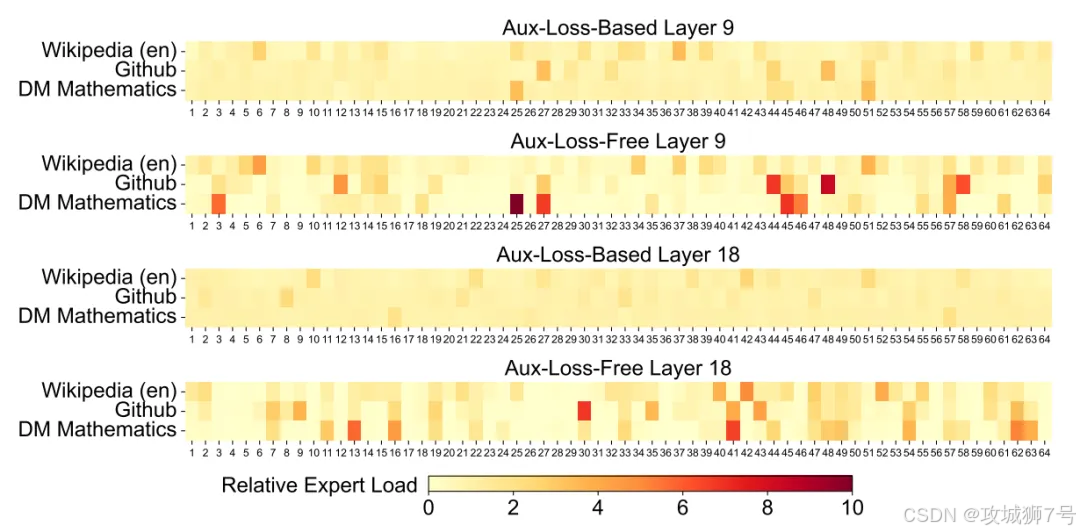
(1)优化MoE负载均衡,动态分配任务,避免专家“闲忙不均”,系统更稳效;
(2)引入“多token预测”,从“逐字学习”升级为“一次性预测多词”,提升学习效率,加速模型收敛。

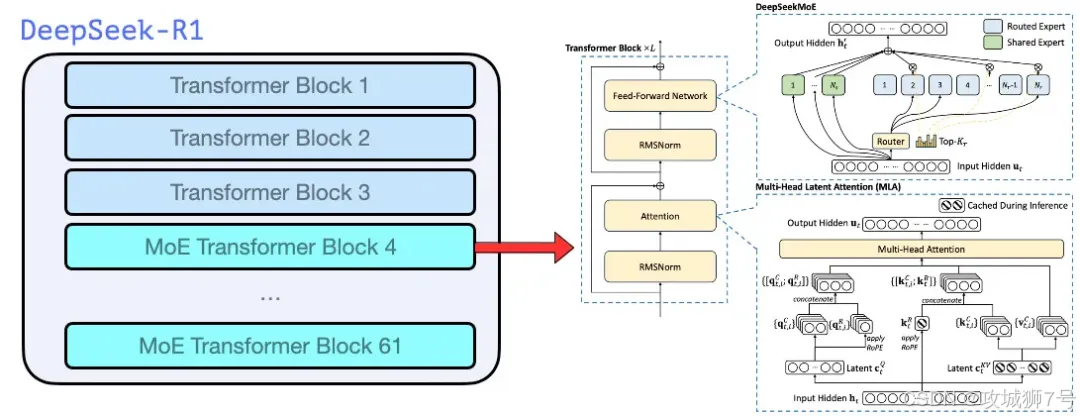
2.3 DeepSeek R1:学会“思考”的推理者
核心是“推理能力”,回答复杂问题前先进行“思维链”(内心独白),分步解题再给答案,擅长逻辑、编程、数学等深度任务,但响应比V3慢。
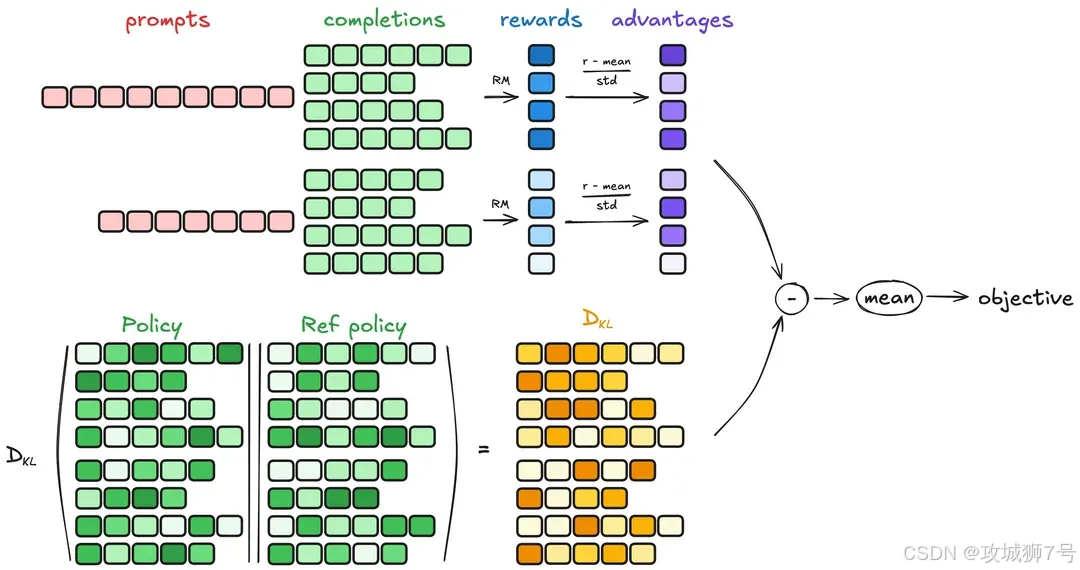
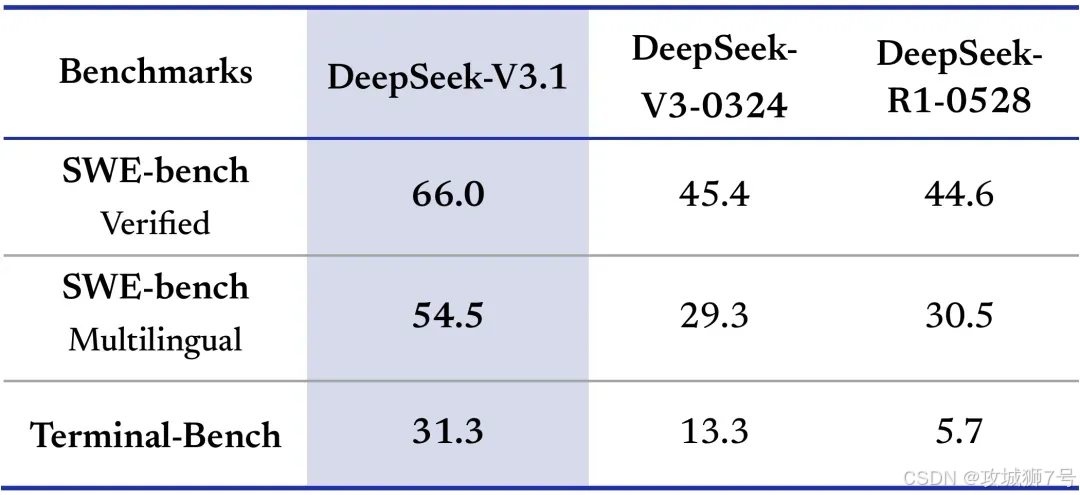
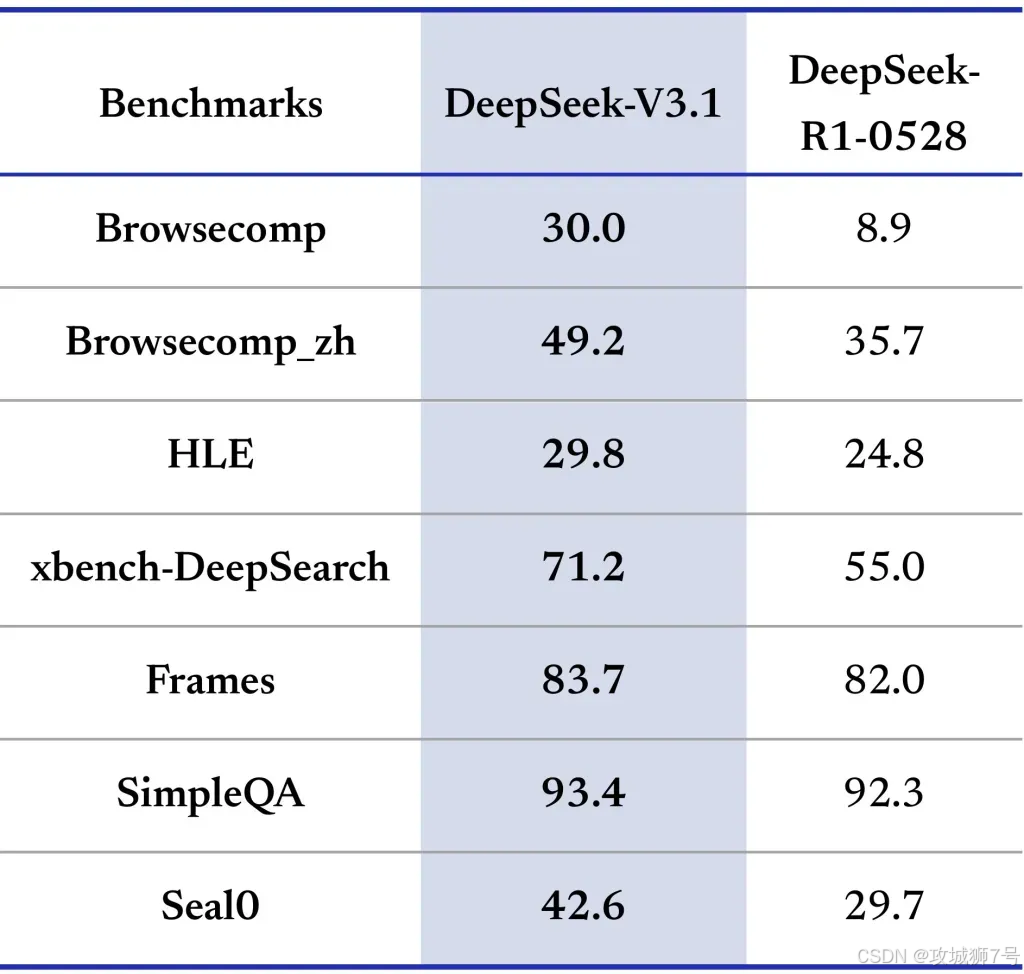
2.4 DeepSeek V3.1:“思考者”与“行动派”合体
核心是“混合推理架构”,融合V3的快与R1的深,支持两种模式切换:
- 非思考模式:如V3,适合快速问答、创作,追速度;
- 思考模式:如R1,适合复杂推理,追精准,且比R1更快。
此外,V3.1智能体能力增强(善用外部工具),代码修复、命令执行能力提升,“幻觉”现象减少38%,可靠性显著提高。
三、第三部分:直面“幻觉”与风险,透明是最好的解药
在公开的技术说明中,DeepSeek非常坦诚地剖析了当前AI技术无法回避的局限性,最核心的就是“幻觉”问题。
“幻觉”是整个AI行业的共同挑战。模型基于概率生成内容,这决定了它有时会“编造”出看似合理但不符合事实的答案。DeepSeek表示,他们正通过使用更高质量的训练数据、优化对齐策略、引入RAG(检索增强生成,即让模型先去搜索再回答)等技术来降低幻觉率,但现阶段无法完全根除。
因此,他们在产品界面添加了显著的提示,提醒用户“内容由AI生成,可能不准确”,并建议不要将AI的回答作为医疗、法律、金融等专业领域的决策依据。
除了技术局限性,滥用风险同样不容忽视。DeepSeek表示,他们建立了贯穿模型全生命周期的风险管理体系,包括内部评估、红队测试(模拟黑客攻击以发现漏洞)等。
更重要的是,他们将选择权和控制权交还给用户。用户可以查询模型信息,可以拒绝自己的数据被用于训练,也可以删除历史数据。
结语:一次主动的透明,一场行业的进步
DeepSeek这次主动“交底”,虽然有响应国家新规的背景,但其公开的深度和广度,依然超出了许多人的预期。这不仅展现了其技术自信,更在客观上推动了整个行业的透明化进程。
从V2的“记忆优化”,到V3的“效率至上”,再到R1的“深度思考”,最后到V3.1的“智能体觉醒”,DeepSeek的进化之路,是中国乃至全球顶尖大模型技术发展的一个缩影。它告诉我们,AI的未来,不仅在于参数的堆砌和知识的广度,更在于推理的深度、效率的提升和与物理世界交互的能力。
当AI不再是一个神秘的“黑箱”,当它的原理、能力边界和潜在风险都被更清晰地摆在台面上时,我们才能更好地利用它、监管它,并最终与它共创一个更智能、也更值得信赖的未来。从这个角度看,DeepSeek的这次“交底”,无论对用户还是对整个行业,都是一件好事。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!




















 344
344





 到【灌水乐园】发言
到【灌水乐园】发言









