



Datawhale分享
最新:DeepSeek V3/R1训练细节
来源:新智元
其中,第四条要求:对符合要求的AI生成合成内容添加显式标识。
刚刚,DeepSeek 官微发布了最新回应公告——凡是 AI 生成的内容,都会清楚标注「AI 生成」。
它还郑重提醒,用户严禁恶意删除、篡改、隐匿标识,更别提用 AI 传播、制作虚假信息。

此外,这次还发布了《模型原理与训练方法说明》,可以一瞥 DeepSeek 的技术路径。
接下来,深入探索一下 DeepSeek V3/R1 的一些训练细节。

文档链接:https://cdn.deepseek.com/policies/zh-CN/model-algorithm-disclosure.html
一、回应新要求,DeepSeek公开技术说明
DeepSeek 主要介绍了大模型的训练和推理阶段,包括预训练、优化训练(微调)以及训练数据等。
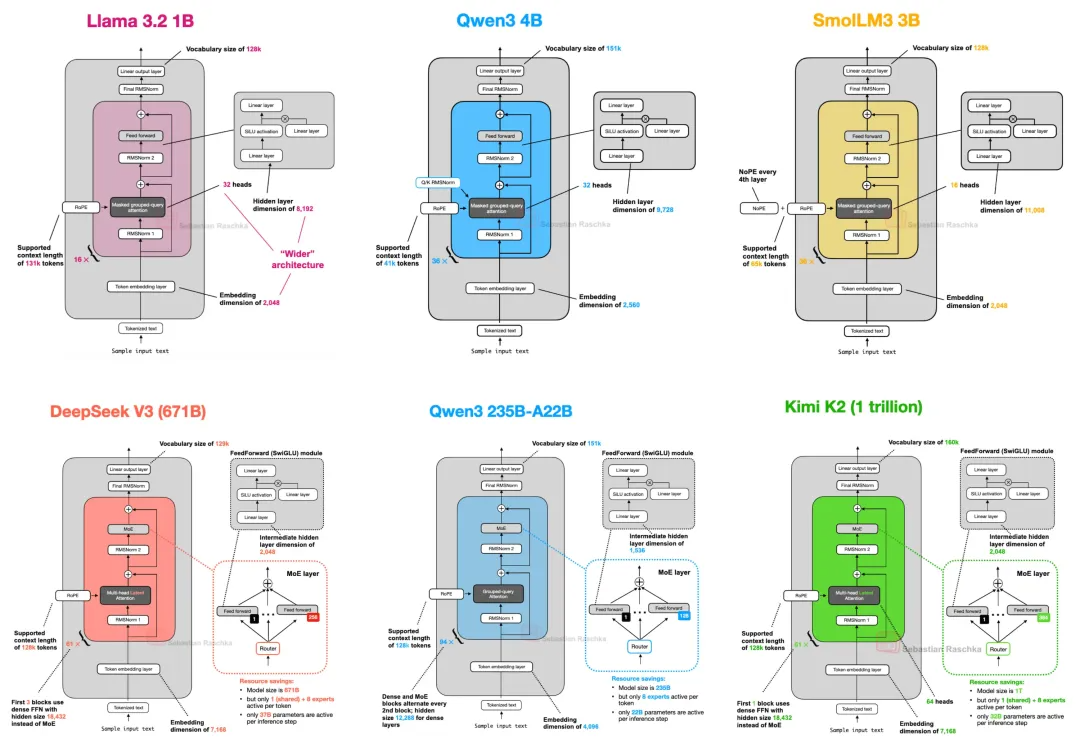
不同大模型的神经网络架构
1. 模型训练
模型训练阶段即模型的开发阶段:通过设计好的深度神经网络架构和训练方法,开发人员开发出可被部署使用的模型。
模型由多层神经网络组成,不同的架构直接影响模型的性能。此外,模型性能也受参数规模的制约,而训练的目的就是找到具体的参数值。
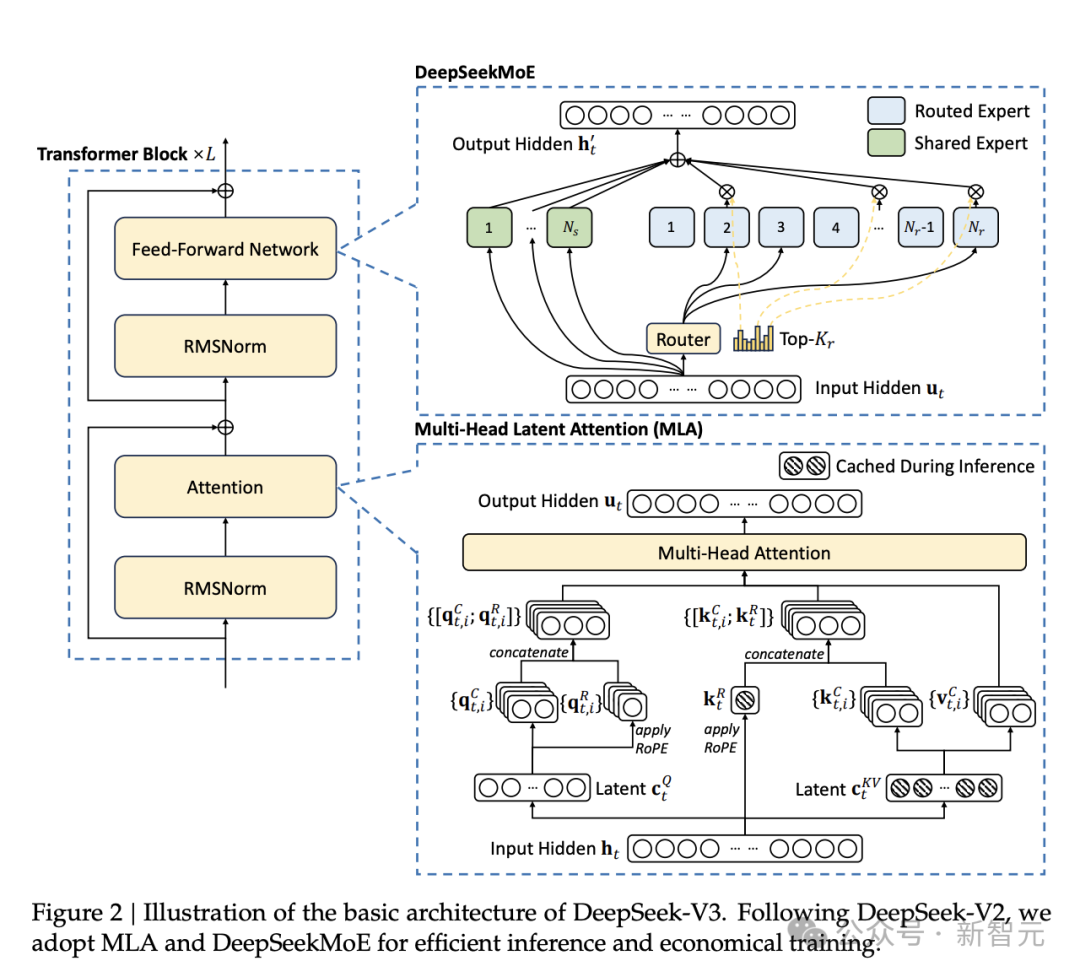
目前,大模型的参数规模数以亿计。最新的 DeepSeek-V3-0324,参数总量为 6850 亿。
在训练过程中,这些参数通过梯度下降算法迭代优化。
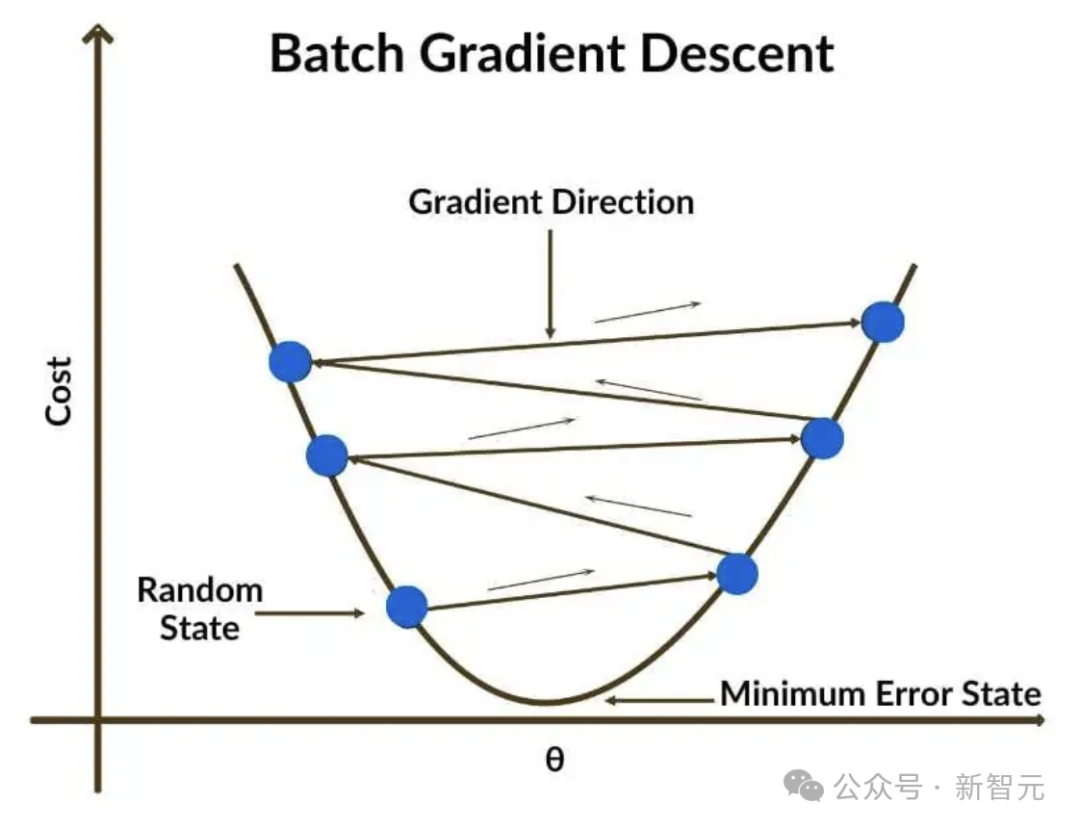
这次,DeepSeek 把模型训练分为预训练和优化训练两个环节。
预训练:预训练目标是通过数据训练模型,使模型掌握通用的语言理解与生成能力。
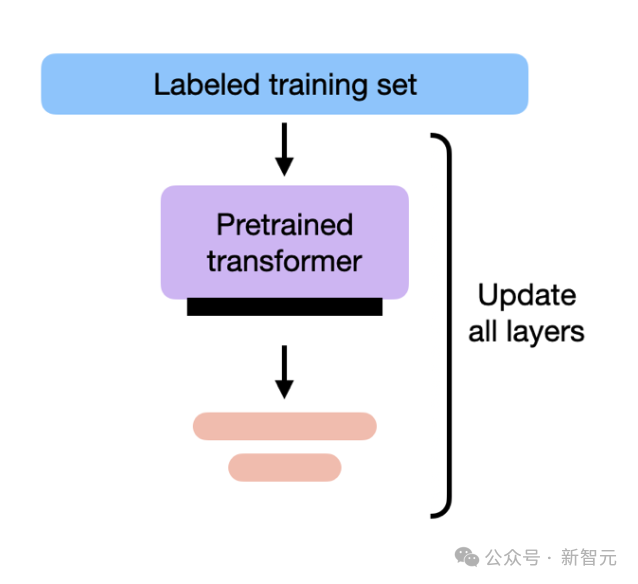
优化训练:也称为微调,是在预训练模型的基础上通过特定任务的数据进一步调整模型参数,使模型适应实际应用场景。
在预训练阶段,模型通过大规模自监督学习,从文本数据中学习语言模式与知识关联。预训练完成后,模型能理解并生成连贯的文本,但还不会精准地回答问题或执行任务,因此需要进一步的训练微调。
在优化训练阶段,模型一般通过 SFT、RL 等方法,学会根据指令回答问题,符合人类的偏好和需求,并激发在特定领域的专业能力。
经过优化训练的模型能更好地满足实际需求,可被部署使用。
二、DeepSeek的训练过程
DeepSeek 模型的能力,是建立在高质量、大规模、多样化的数据之上。
在「预训练阶段」和「优化训练阶段」,各有不同。
1. 预训练阶段
在预训练阶段,主要使用了两类数据:
互联网公开可用的信息,比如网页、公开文档等。
与第三方合作获取许可的数据需要强调的是,在此阶段,根本无需获取个人信息用于训练,DeepSeek 不会有意关联至任何特定账户和个人,更不会主动将其用于训练模型。
不过,预训练数据规模过于庞大,可能偶然包含了一些个人信息。
对此,DeepSeek 会通过技术手段,尽力筛查并移除这些信息,确保数据「干干净净」。
为了保证数据质量、安全、多样,他们还打造了一套硬核数据治理流程——
首先,通过「过滤器」自动剔除仇恨言论、色情低俗、暴力、垃圾信息,以及可能侵权的原始数据。
其次,通过算法+人工审核,识别并降低数据中的统计性偏见,让模型更公平、更客观。
2. 优化训练阶段
到了优化训练阶段,一般需要通过人工或自动化的方式构造、标注一批问答对数据来对模型进行训练。
DeepSeek 这次表示:这些问答对数据是由研究团队生成提供的,其中少部分数据的构造可能会基于用户的输入。

在 DeepSeek-R1 训练中,研究人员直接提示模型生成包含反思和验证的详细答案;收集并整理 DeepSeek-R1-Zero 的输出,使其具有可读性;以及通过人工注释者的后期处理来提高数据质量
如涉及利用用户的输入构造训练数据,DeepSeek 会对数据进行安全加密技术处理、严格的去标识化和匿名化处理,从而尽可能避免训练数据关联到任何特定个人,且不会在模型给其他用户的输出中带有个人信息,更不会将其用于用户画像或个性化推荐。
同时,DeepSeek 为用户提供了选择退出的权利。
为了确保模型的安全性,在模型优化训练阶段,DeepSeek 构造了专门的安全数据对模型进行安全对齐,教会模型的回复符合人类的价值观,增强模型内生的安全能力。
3. 模型推理
模型的推理阶段即模型被部署提供服务。
模型训练完成并被部署后,可以通过对输入信息进行编码和计算来预测下一个 token,从而具备文本生成和对话等能力。
部署后的模型能够熟练执行基于文本生成的广泛多样的任务,并可以集成到各种下游系统或应用中。
具体到 DeepSeek 的产品服务,基于用户的输入,模型采用自回归生成方式,基于输入的上下文内容,通过概率计算预测最可能的接续词汇序列。
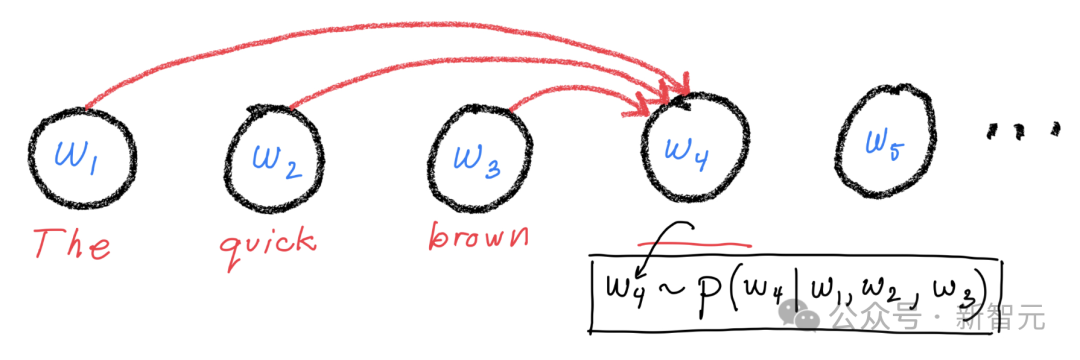
推理完成后,模型输出相应的内容作为响应,包括文字、表格和代码等。
此并非简单检索或「复制粘贴」训练数据中的原始文本,模型也并未存储用于训练的原始文本数据副本,而是基于对语言结构和语义关系的深度理解,动态生成符合语境的回答。
DeepSeek 这次还强调模型开源。
我们通过开源平台对外公开发布了所有模型的权重、参数以及推理工具代码等,并采用宽松的 MIT 协议,供使用者自由、免费下载部署使用。
同时,DeepSeek 发布各模型的完整技术报告,供社区和研究人员参考,并帮助公众更深入地了解每个模型的技术原理和细节。
三、全周期对抗LLM的局限性和风险
毋庸置疑,当前 AI 发展还在早期阶段,存在无法避免的局限性。
若是再被加以滥用,将会带来严重的后果。
1. 局限性
AI 往往会生成错误、遗漏,或不符合事实的内容,这种现象统一称之为「幻觉」。
这个问题,是整个 AI 行业面临的挑战。
对此,DeepSeek 正通过一些技术手段降低幻觉率,包括高质量的训练数据、优化对齐策略、RAG等,但现阶段依无法完全消灭。
同时,他们还在欢迎页、生成文本的末尾,以及交互界面底部,添加显著的提示标识。
特别提醒用户——内容由人工智能生成,可能不准确。
因此,AI 生成的内容仅供参考,所有人不应将输出的内容作为专业建议。
尤其是,在医疗、法律、金融等专业领域,DeepSeek 不提供任何建议或承诺,专业的事儿还得找专业的人。

滥用风险
AI 技术本身是中立的,但滥用可能带来隐私保护、版权、数据安全、内容安全、偏见歧视等风险。
DeepSeek 对此也是高度重视,采取了一系列硬核措施,贯穿了模型研发、训练、部署的全生命周期。
制定内部风险管理制度
开展模型安全性评估
进行红队测试
增强模型和服务透明度等
更重要的是,DeepSeek 还赋予了用户知情权、选择权、控制权——
你可以查询服务的基本信息、拒绝其数据用于模型训练、删除其历史数据等。
参考资料:
1. https://cdn.deepseek.com/policies/zh-CN/model-algorithm-disclosure.html

一起“点赞”三连↓

















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









