







目录

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 AI“偷书”学习,算不算偷?
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
咱们先来做个思想实验。
假如你想成为一个写作大师,你走进一家图书馆,把海明威、莎士比亚、村上春树的所有作品都读了一遍。你不是为了背诵或抄袭,只是为了学习他们的文风、结构和遣词造句,最终形成了自己独特的风格。
这听起来没毛病,对吧?
但如果,你不是走进图书馆,而是从一个盗版网站,一口气下载了几百万本书存到你的硬盘里,再开始学习呢?
这个行为,性质是不是就变了?
这正是最近AI圈吵得最凶的版权问题的核心。以Anthropic(Claude的开发商)和Meta(Llama的开发商)为代表的AI公司,被一群作家告上了法庭,罪名就是——未经授权,用了我们的书来训练你们的大模型。
最近,美国加州北区联邦法院对这两起案件,接连给出了两次里程碑式的判决。判决结果很有意思,它既给AI公司开了绿灯,也划下了一条清晰的红线。
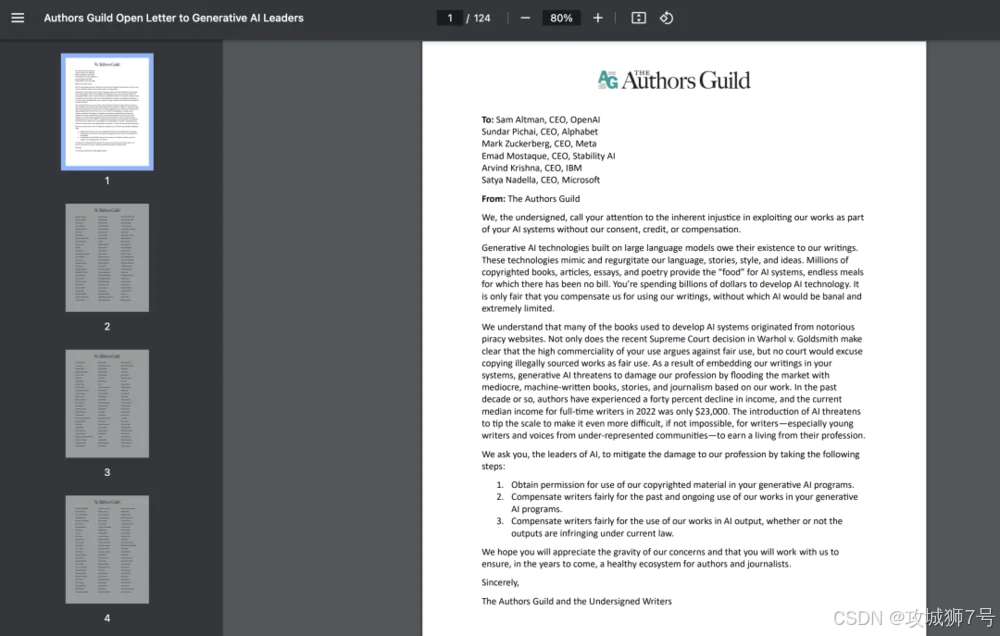
万名作家联名反对信
一、“学习”无罪:AI训练被认定为“合理使用”
首先,是让所有AI公司都松了一口气的好消息:法院认为,使用受版权保护的作品来训练AI大模型,这个行为本身,属于“合理使用”(Fair Use)。
这是什么意思呢?“合理使用”是版权法里的一个重要原则,它允许在某些特定情况下,你可以在未经许可的情况下使用别人的作品。
法官给出的理由非常关键,他认为AI训练是一个“极具转化性的(exceedingly transformative)”过程。
目的不同:AI“阅读”这些书籍,不是为了把书的内容再复述给用户,而是为了学习语言的模式和结构,最终生成全新的、完全不同的东西,比如帮你写一封邮件、一段代码。这和原书的用途完全不同。
不构成市场替代:你不会因为用了Claude,就不去买那本它学习过的实体书了。AI的产出,并没有直接抢占原作者的市场。
法官甚至用了一个很经典的“人类读书”比喻:“(AI训练过程)就像一个学生阅读了海明威的作品,然后用简短的陈述句写作一样。”
这个判决,可以说是给全球的AI训练行为定下了一个基调:只要你不是为了原样复制,而是为了学习和创造新东西,那么“学习”这个动作本身,是受法律保护的。
二、“藏书”有罪:建立“盗版图书馆”是绝对的红线
但是,别高兴得太早。法院紧接着就给出了一个“但是”。
在Anthropic的案子中,法官明确指出,虽然“学习”本身没问题,但你是从哪搞来的书,以及你拿到书之后干了什么,这很重要。
Anthropic被发现,他们不仅从Books3、LibGen这类臭名昭著的“影子图书馆”(也就是盗版网站)下载了海量的书籍,还把这些书存在了自己的服务器上,建立了一个永久性的、内部可以检索的“中央数据库”。
法官认为,这个行为不具有任何“转化性”,它和训练AI是两码事。你这就是赤裸裸地建立了一个“盗版图书馆”,直接剥夺了作者通过销售和授权获取收入的机会。
判决书里的这句话说得非常重:
“只要盗取本可合法获取的内容,本质就是侵权,即便下载后立即用于转换性用途(AI训练)并立即删除也是如此。”
简单来说,法院的逻辑是:
学习(训练AI):可以,这是“合理使用”。
偷书(用盗版)并藏书(建永久数据库):不行,这是“直接侵权”。
这两件事必须分开看。你不能因为你学习的目的很高尚,就为自己偷书的行为辩护。
因此,Anthropic虽然在“训练合法性”上赢了,但接下来,他们必须为自己建立“盗版图书馆”的行为,面临可能高达天文数字的巨额赔偿。
三、小小的分歧:Meta案带来了新的争议点
就在大家以为规则已经清晰的时候,同一家法院的另一位法官,在审理Meta的案子时,却提出了一个略有不同的看法,让事情变得更有趣了。
Meta同样也使用了“影子图书馆”的数据来训练Llama。但这位法官在判决时,更倾向于做一个“整体性判断”。
他认为:“因为合理使用本身就是判断某种使用是否合法,而非单纯看使用渠道是否合法……即便使用了非法渠道,也不代表不构成合理使用”。
这位法官似乎认为,既然最终的“使用目的”(训练AI)是合理的,那么数据来源的“原罪”似乎就可以被一定程度上地“豁免”。当然,他也强调,Meta曾经尝试过花钱寻求授权但失败了,这可能影响了他的判断,他不认为Meta是“恶意侵权”。
这就产生了一个微妙的分歧:
Anthropic案的法官:偷书和学习,两罪并罚,偷书的罪逃不掉。
Meta案的法官:主要看学习成果,如果学习是正当的,偷书的罪可以酌情从轻。
这个分歧,为未来的AI版权诉讼留下了巨大的争论空间。
四、给所有人的启示:游戏规则正在被重写
这两起判决,就像在混沌的AI版权领域投下的两颗探路石,虽然没有照亮所有角落,但至少为我们划出了几条清晰的道路:
(1)对AI公司来说:野蛮生长的时代结束了。“先上车后补票”甚至“只上车不买票”的玩法行不通了。想用数据,就必须走正规渠道,老老实实地去和出版商、媒体、创作者谈授权、付费用。未来,“先授权,后使用”将成为行业主流。
(2)对创作者来说:这是一个好消息。判决虽然认可了训练的“合理性”,但也捍卫了版权的根基——你不能无偿、非法地获取我的作品。这为创作者在与AI公司的谈判中,提供了坚实的法律武器。未来的诉讼,重点将不再是争论AI该不该“学”,而是AI公司如何证明自己“学”的东西是合法买来的。
(3)对我们普通用户来说:这意味着AI服务的成本可能会上升。当AI公司需要为数据支付高昂的授权费时,这部分成本最终无疑会传导到我们这些使用者身上。但从长远来看,一个尊重版权、规则清晰的行业生态,才能持续产出高质量的AI服务。
总而言之,这两场判决远非终点。Anthropic的赔偿案还没审,判决也可能被上诉。但无论如何,一个全新的时代已经开启:AI的创新,必须与对创作者的尊重并行。
这堂课,不仅是给AI公司的,也是给我们每一个身处这场技术变革中的人的。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!



















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











