







目录
六、教训六:Agent犯错了?别擦,把“犯罪现场”留给它看!
七、教训七:警惕“少样本提示”陷阱,别让你的Agent变成复读机

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 Manus创始人亲述Agent经验
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
嘿,各位还在被AI Agent折磨的兄弟们,大家好。
如果你也正在折腾AI Agent,那你一定懂那种感觉:你以为自己是运筹帷幄的架构师,结果干着干着,就成了AI的全职保姆。你得手把手教它怎么用工具,一步步引导它别跑偏,它一犯错你就得赶紧给它“擦屁股”。
最近,一直备受争议的AI Agent产品 Manus 的联合创始人兼首席科学家季逸超(Peak Ji),亲自下场,分享了他们团队是怎么从这个“保姆坑”里爬出来的。
剧透一下:他们重写了整整4遍框架,才总结出了一堆血泪教训。其中很多,都和我们之前的“共识”背道而驰。
这篇文章,就是把他们的“武功秘籍”扒出来,希望能让大家在造Agent的路上,少走点弯路。

一、教训一:别迷信微调,死磕“上下文工程”才是性价比之王
在项目一开始,Manus团队就面临一个灵魂拷问:是像传统炼丹一样,拿个开源模型玩命微调(fine-tuning)一个专属Agent?还是直接站在巨人肩膀上,基于GPT-4o或Claude 3.5这些顶级大模型的“上下文学习”(in-context learning)能力来构建?
季逸超用他上一个创业公司的惨痛经历,果断选了后者。当年他从零开始训练自己的模型,结果GPT-3一出,他几年的心血一夜归零。
那个教训让他们明白一个道理:对于一个追求快速迭代、还在找产品方向(PMF)的应用来说,花几周甚至几个月去搞微调,简直是“自杀行为”。
所以,Manus选择押注“上下文工程”(Context Engineering)。
这词听着高大上,说白了就是:不想着怎么去改变模型本身,而是琢磨怎么把喂给模型的信息(也就是上下文Context)组织好、设计好、操控好,让模型能“读懂空气”,乖乖听你使唤。
这样做的好处是,产品迭代能从“几周”缩短到“几小时”。而且,底层模型再怎么升级,Manus这艘船都能跟着“水涨船高”,而不是被钉死在海床上的柱子。
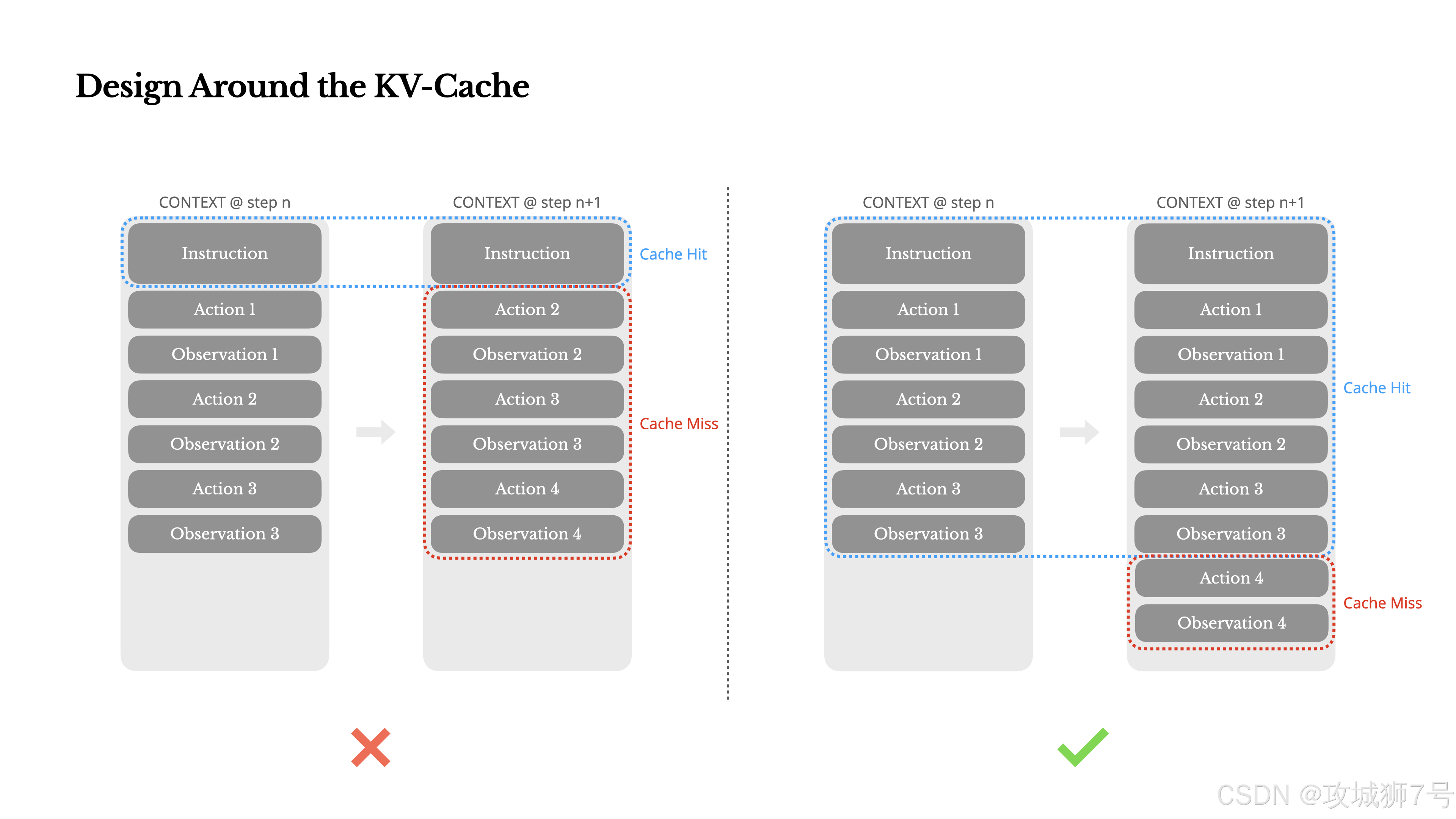
二、教训二:性能指标千千万,唯有“KV缓存命中率”是爹
如果只能选一个指标来优化Agent,那会是什么?Manus的答案是:KV缓存命中率 (KV-cache hit rate)。
这玩意儿听着玄乎,简单说就是大模型的“短期记忆”。
Agent干活,是一轮一轮的:看一眼上下文 -> 采取一个动作 -> 得到一个观察结果 -> 把动作和结果加到上下文里 -> 开始下一轮。
这就导致上下文会越滚越长,而Agent每轮的输出(比如一个函数调用)却很短。如果你每次都让模型把几万字的上下文从头到尾读一遍,那延迟和成本都会爆炸。
KV缓存就是来救命的。如果下一轮输入的开头部分和上一轮完全一样,模型就能直接从“短期记忆”里读取计算结果,速度飞起,成本暴降10倍!
所以,Manus一切设计的核心,都是为了伺候好这位“爹”。他们总结了几个关键实践:
(1)保持提示词前缀稳定:系统提示词(System Prompt)里千万别加时间戳这种每秒都在变的东西,那会让缓存全废。
(2)上下文只许追加,不许修改:别想着回去改前面的对话历史,那会破坏缓存。序列化JSON时也要保证key的顺序稳定。
(3)明确标记缓存断点:告诉模型,哪部分是固定不变的,可以大胆缓存。
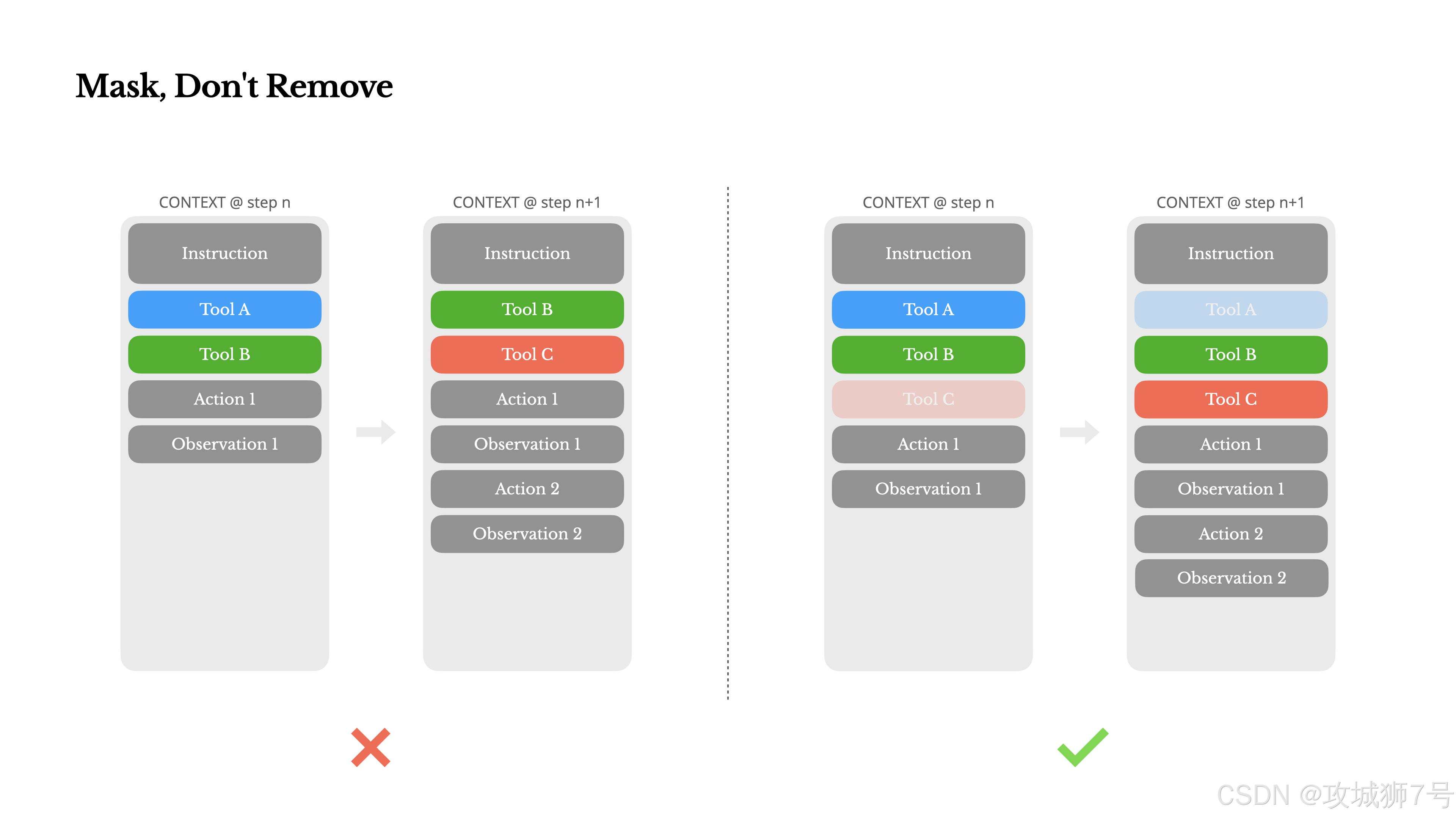
三、教训三:工具太多怎么办?给它“蒙上眼”,而不是“拿走”
当你的Agent学会的工具越来越多,它就开始犯傻了,不知道该用哪个。
常规思路是什么?按需加载工具,这轮用不到的工具,我就不放在上下文里,免得干扰它。
Manus踩坑后告诉你:这是个巨坑!
因为工具定义通常放在上下文的开头,你每动一次工具列表,就等于改了“考卷”的开头,后面的KV缓存又双叒叕全废了。而且模型看着上下文里之前的操作记录里有某个工具,但现在工具列表里又没了,它会当场“精神错乱”。
Manus的骚操作是:工具我不删,我只给你“蒙上眼睛”(Masking)。
工具列表永远是固定的、完整的。但在某个特定状态下,他们通过技术手段(掩码token logits)在模型生成答案的最后一刻告诉它:“喂,虽然你有很多工具,但你现在只能用那几个以 `browser_` 开头的!”
这样一来,缓存保住了,模型也不懵了。
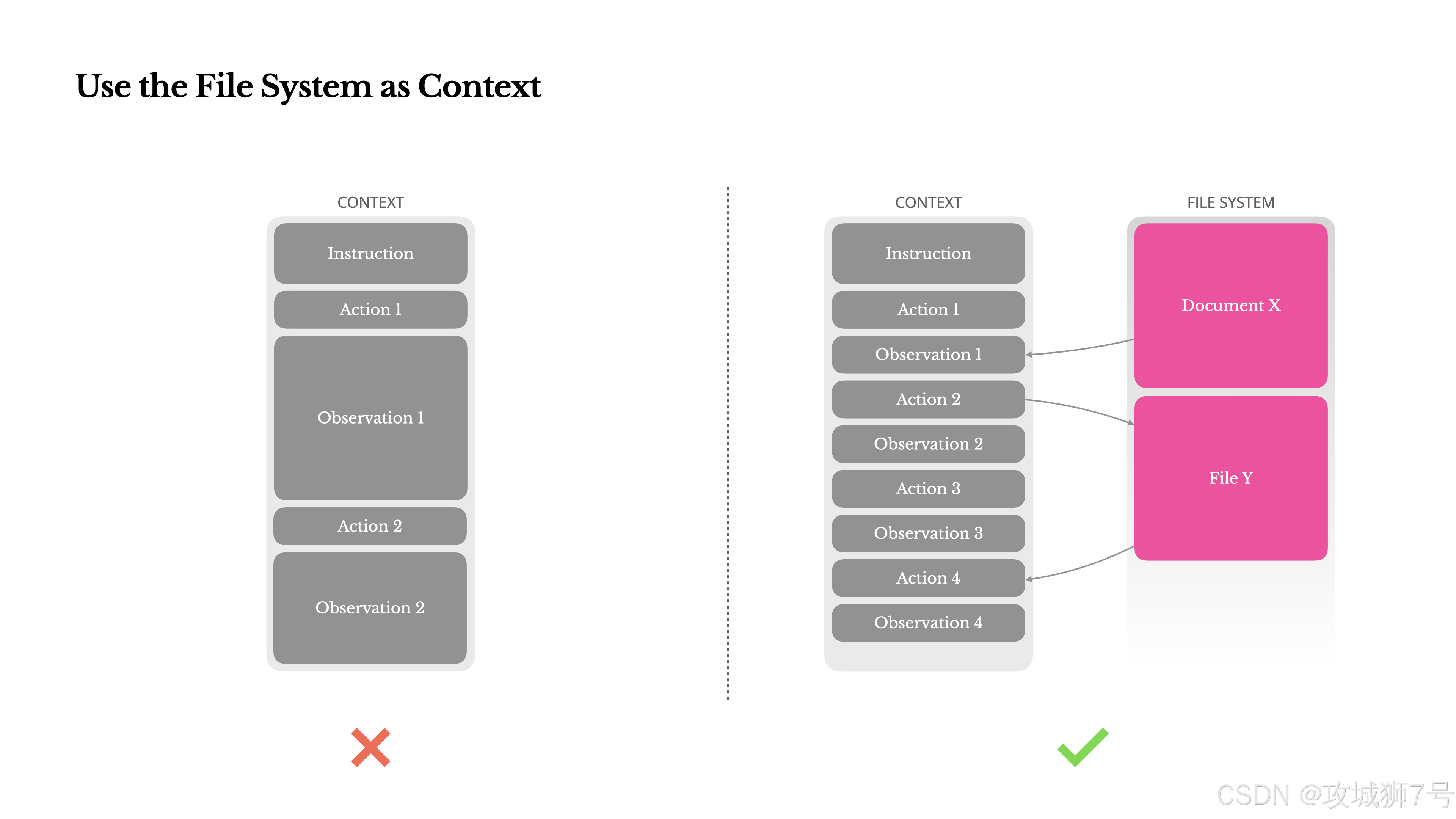
四、教训四:上下文窗口再大也没用,把文件系统当“草稿纸”
128K甚至1M的上下文窗口,听起来很爽,但在Agent场景里,通常不够用,甚至是个累赘。
(1)随便爬个网页内容,上下文就爆了。
(2)上下文太长,模型性能会下降,还容易“忘事”。
(3)长上下文的推理成本,谁用谁肉疼。
很多方案是搞上下文压缩,但压缩就意味着信息丢失。你怎么知道被你压缩掉的某句话,在10步之后不会成为关键线索呢?
Manus的思路是:把文件系统当成无限大的上下文,或者说,Agent的“草稿纸”。
模型学会了自己去读写文件。它不再把所有东西都傻乎乎地记在脑子里(上下文),而是把中间结果、网页内容、长文档都存到文件里,用的时候再去读。
这样,上下文里只需要保留一个URL或者一个文件路径就行了。信息没有丢失,上下文长度还大大缩减,完美!
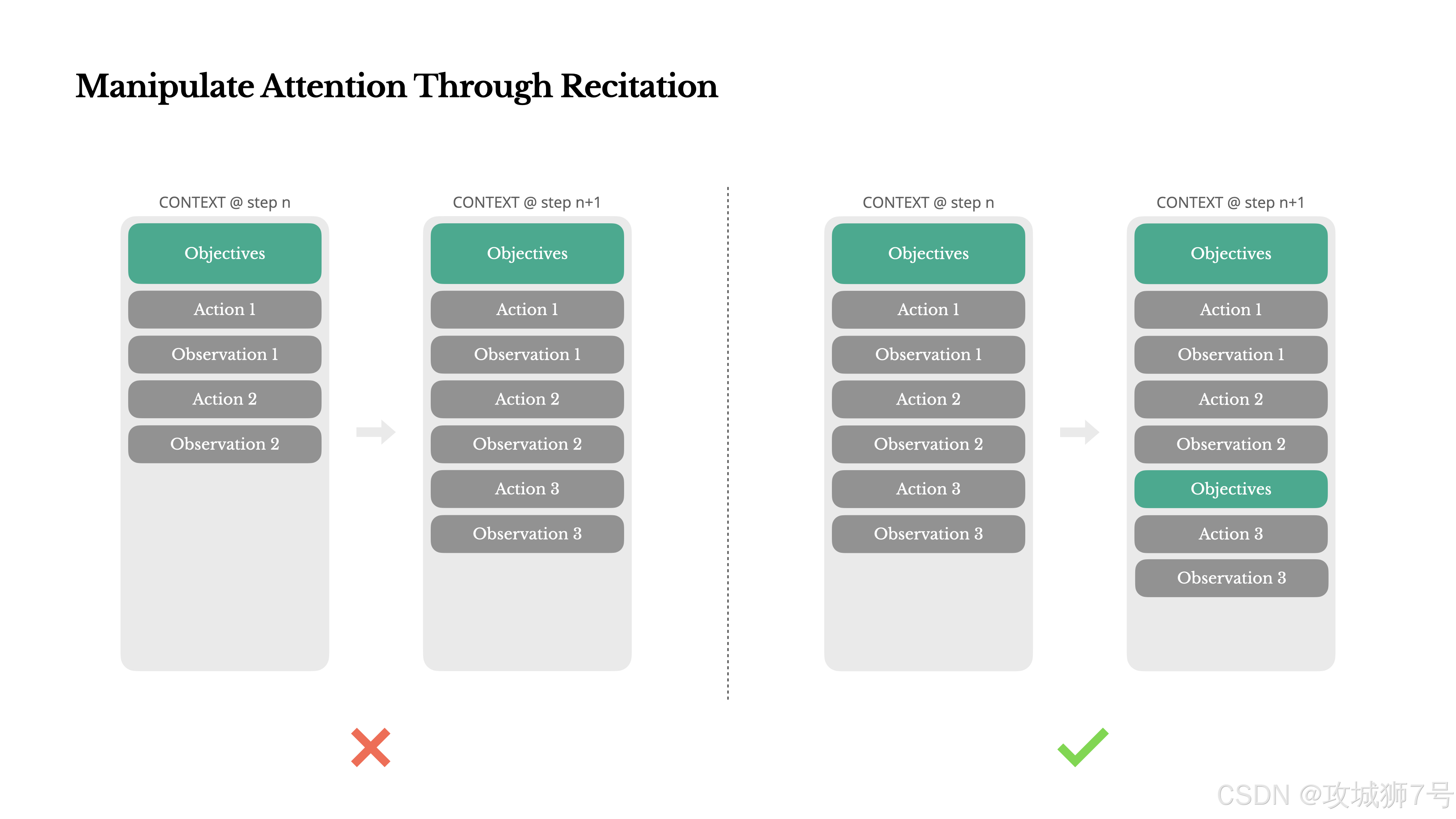
五、教训五:怕它“忘事”?让它自己写“待办清单”
如果你用过Manus,会发现一个有趣的现象:它干活时,总喜欢自己建一个`todo.md`,做完一件就划掉一件。
这可不是为了卖萌。这是Manus团队设计的一种“注意力操控机制”。
一个复杂的任务可能需要几十步,Agent跑着跑着就“迷路”了,忘了最初的目标是啥(这就是著名的大模型“中间遗忘”问题)。
通过不断地重写`todo.md`,Manus实际上是把“全局计划”这个最重要的信息,不断地“复述”到上下文的末尾。这就相当于一直在提醒模型:“兄弟,别跑偏,咱今天的KPI是这个!”
用自然语言,引导它自己的注意力,这招真是聪明。
六、教训六:Agent犯错了?别擦,把“犯罪现场”留给它看!
Agent犯错了怎么办?大部分人的第一反应是:赶紧删掉错误信息,清理现场,假装无事发生,然后让它重试。
Manus的经验恰恰相反:把错误现场(比如报错的堆栈跟踪 stack trace)原封不动地保留下来,喂给模型‘看’。
当模型看到自己上一步的操作导致了一个血淋淋的报错,它就像被电了一下,下次再遇到类似情况,它内部的“信念”就变了,会下意识地避开这个坑。
Manus团队认为,错误恢复能力,才是衡量一个Agent是否真正智能的核心标志。一个只会走阳光大道的Agent是脆弱的,一个能从泥坑里爬出来的Agent,才是真正可靠的。

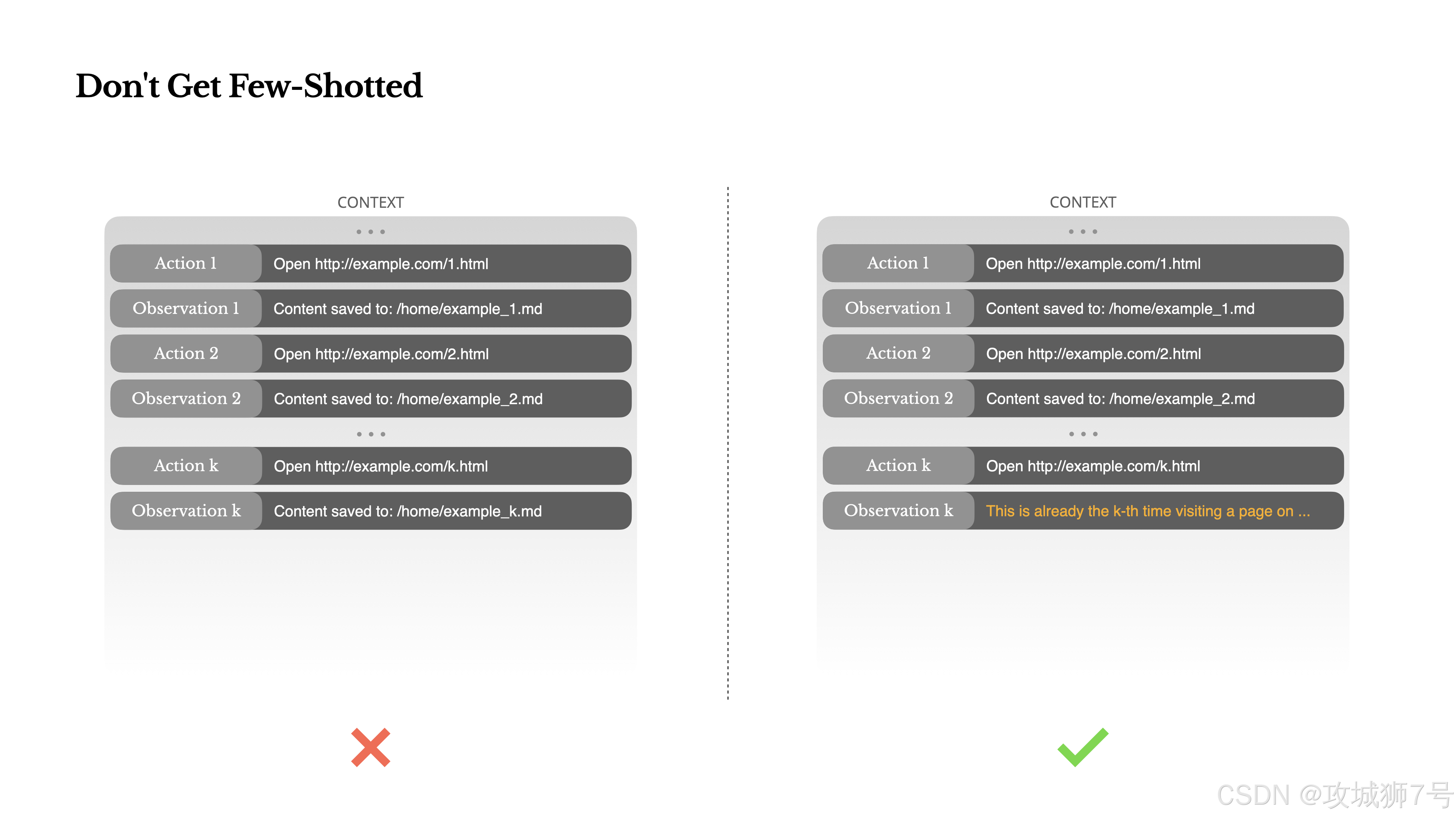
七、教训七:警惕“少样本提示”陷阱,别让你的Agent变成复读机
“少样本提示”(Few-shot prompting)是Prompt工程的基操,给几个例子,模型就能学得有模有样。
但在Agent系统里,这可能是个“毒药”。
因为模型是出色的模仿者。如果它在上下文里看到一堆相似的“动作-观察”对,它就会陷入一种惯性,不断重复这个模式,哪怕情况已经变了。比如你让它审阅20份简历,它可能审到后面就开始“路径依赖”,不过脑子了。
Manus的解法是:主动在上下文里引入“噪音”。
比如,用不同的模板来序列化信息、换几种说法、或者在格式上做点微小的调整。这种“受控的随机性”会打破模型的惯性,让它时刻保持“清醒”,而不是变成一个无情的复读机。
结语
看完Manus的这些“反常识”操作,你会发现,构建一个强大的AI Agent,并非一味地追求更大的模型、更牛的算法。更多时候,它是一门充满妥协与智慧的“工程学”。
如何与模型的“脾气”共舞,如何“欺骗”它的注意力机制,如何利用它的弱点来达成我们的目标……这里面充满了各种有趣的手艺活(craftsmanship)。
Manus分享的这些教训,无疑为所有Agent开发者,提供了一份宝贵的“避坑指南”。
参考原文:Context Engineering for AI Agents: Lessons from Building Manus
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











