




 本文介绍了Bloom Filter作为一种高效的数据去重工具,它在处理海量数据时提供HashSet类似功能,但存在误判可能性。文章详细阐述了Bloom Filter的基本原理、误判率计算、实战应用,并提及在Java和Scala中的实现库,同时对比了分布式计算中更适用的HyperLogLog算法。
本文介绍了Bloom Filter作为一种高效的数据去重工具,它在处理海量数据时提供HashSet类似功能,但存在误判可能性。文章详细阐述了Bloom Filter的基本原理、误判率计算、实战应用,并提及在Java和Scala中的实现库,同时对比了分布式计算中更适用的HyperLogLog算法。
Bloom Filter一般用于数据的去重计算,近似于HashSet的功能;但是不同于Bitmap(用于精确计算),其为一种估算的数据结构,存在误判(false positive)的情况。
1. 基本原理
Bloom Filter能高效地表征数据集合\(S = \lbrace x_1 ,x_2 ,...,x_n \rbrace\),判断某个数据是否属于这个集合。其基本思想如下:用长度为\(m\)的位数组\(A\)来存储集合信息,同时是有\(k\)个独立的hash函数\(h_i(1\le i \le k)\)将数据映射到位数组空间。具体流程如下:
- 将长度为\(m\)的位数组全置为0;
- 对于数据\(x \in S\),依次计算其\(k\)个hash函数值\(h_i(x)=w,且1\le i \le k, 1 \le w \le m\),将位数组中的第\(a\)位bit置为1,即A[w]=1.
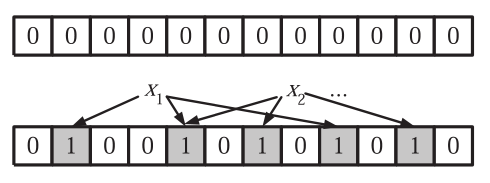
当查询数据\(y\)是否属于集合\(S\)时,计算其\(k\)个hash函数值,如果\(h_i(y)\)对应的位数组均为1,则数据\(y\)属于集合\(S\);反之,则不属于。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











