




论文提出了多尺度视觉
Transformer模型MViT,将多尺度层级特征的基本概念与Transformer模型联系起来,在逐层扩展特征复杂度同时降低特征的分辨率。在视频识别和图像分类的任务中,MViT均优于单尺度的ViT。来源:晓飞的算法工程笔记 公众号
论文: Multiscale Vision Transformers

Introduction
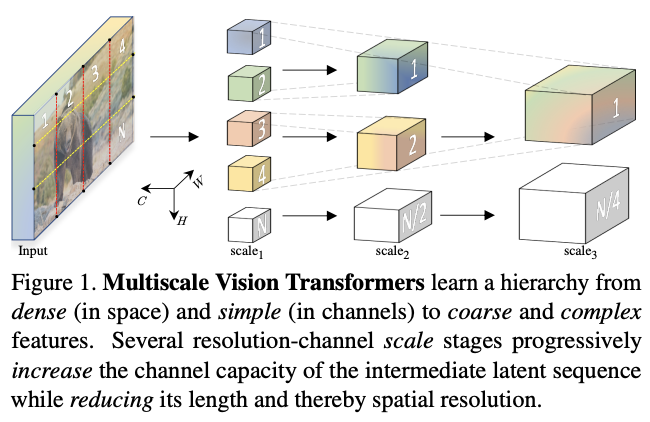
论文提出了用于视频和图像识别的多尺度ViT(MViT),将FPN的多尺度层级特征结构与Transformer联系起来。MViT包含几个不同分辨率和通道数的stage,从小通道的输入分辨率开始,逐层地扩大通道数以及降低分辨率,形成多尺度的特征金字塔。

在视频识别任务上,不使用任何外部预训练数据,MViT比视频Transformer模型有显着的性能提升。而在ImageNet图像分类任务上,简单地删除一些时间相关的通道后,MViT比用于图像识别的单尺度ViT的显着增益。
Multiscale Vision Transformer (MViT)
通用多尺度Transformer架构的核心在于多stage的设计,每个stage由多个具有特定分辨率和通道数的Transformer block组成。多尺度Transformers逐步扩大通道容量,同时逐步池化从输入到输出的分辨率。
Multi Head Pooling Attention
多头池化注意(MHPA)是一种自注意操作,可以在Transformer block中实现分辨率灵活的建模,使得多尺度Transformer可在逐渐变化的分辨率下运行。与通道和分辨率固定的原始多头注意(MHA)操作相比,MHPA池化通过降低张量的分辨率来缩减输入的整体序列长度。
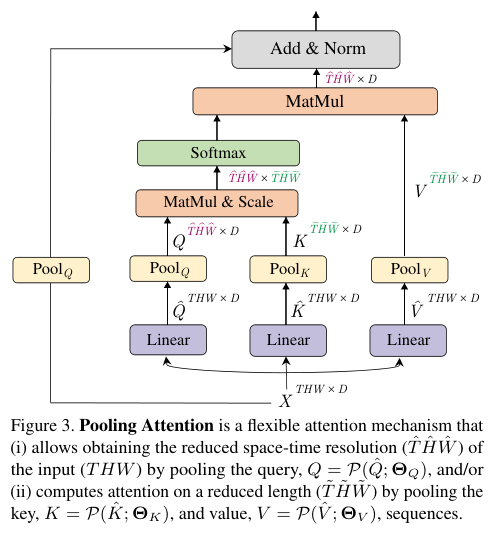
对于序列长度为 L L L 的 D D D 维输入张量 X X X, X ∈ R L × D X \in \mathbb{R}^{L\times D} X∈RL×D,根据MHA的定义先通过线性运算将输入 X X X映射为Query张量 Q ^ ∈ R L × D \hat{Q} \in \mathbb{R}^{L\times D} Q^∈RL×D,Key张量 K ^ ∈ R L × D \hat{K} \in \mathbb{R}^{L\times D} K^∈RL×D和Value张量 V ^ ∈ R L × D \hat{V} \in \mathbb{R}^{L\times D} V^∈RL×D。
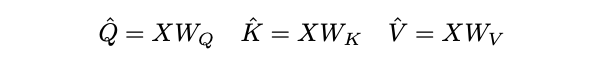
然后通过池化操作 P \mathcal{P} P将上述张量缩减到特定长度。
在进行计算之前,中间张量 Q ^ \hat{Q} Q^、 K ^ \hat{K} K^、 V ^ \hat{V} V^需要经过池化运算 P ( ⋅ ; Θ ) \mathcal{P}(·; \Theta) P(⋅;Θ)的池化,这是的MHPA和MViT的基石。
运算符 P ( ⋅ ; Θ ) \mathcal{P}(·; \Theta) P(⋅;Θ)沿每个通道对输入张量执行池化核计算。将 Θ \Theta Θ分解为 Θ : = ( k , s , p ) \Theta := (k, s, p) Θ:=(k,s,p),运算符使用维度 k k k为 k T × k H × k W k_T\times k_H\times k_W kT×kH×kW、步幅 s s s为 s T × s H × s W s_T\times s_H \times s_W sT×sH×sW
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1888
1888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









