




论文将
Multiscale Vision Transformers(MViTv2) 作为图像和视频分类以及对象检测的统一架构进行研究,结合分解的相对位置编码和残差池化连接提出了MViT的改进版本来源:晓飞的算法工程笔记 公众号
论文: MViTv2: Improved Multiscale Vision Transformers for Classification and Detection

Introduction
为不同的视觉识别任务设计架构一直很困难,而最广泛采用的架构是结合了简单性和有效性的架构,例如VGGNet和ResNet。最近,Vision Transformers(ViT) 已经显示出能够与卷积神经网络 (CNN) 相媲美的性能,涌现出大量将其应用于不同的视觉任务中的工作来。
虽然ViT在图像分类中很流行,但在高分辨率目标检测和视频理解任务中的应用仍然具有挑战性。视觉信号的密度对计算和内存要求提出了严峻的挑战,主要因为基于Transformer的模型的自注意力块的复杂度与输入长度呈二次方增长。目前有大量的研究来解决这个问题,比较主要的两个为:
- 使用窗口注意力,在一个窗口内进行局部注意力计算以及对象检测,主要用于目标检测任务。
- 使用池化注意力,在计算自注意力之前先聚合局部特征的,主要用于视频任务。
后者推动了Multiscale Vision Transformers(MViT)的研究,以简单的方式扩展ViT的架构。整个网络不再固定分辨率,而是构造从高分辨率到低分辨率的多个阶段的特征层次结构。
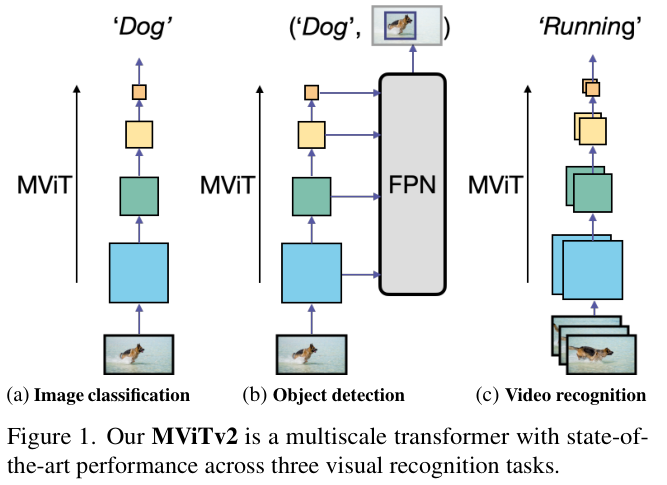
MViT专门为视频任务设计,具有最先进的性能。论文将MViT作为一个模型系列在图像分类、目标检测和视频分类中进行研究,从而了解它是否能够作为通用的视觉任务的主干网络。
根据研究结果,论文提出了改进的架构 (MViTv2),并包含以下内容:
- 从两个方面来大幅提升池化注意力的性能:
- 使用坐标分离的位置距离构造相对位置编码,在
Transformer块中注入平移不变的位置信息。 - 使用残差池化连接来补偿注意力计算中池化缩放带来的影响。
- 使用坐标分离的位置距离构造相对位置编码,在
- 根据标准的密集预测框架
Mask R-CNN with Feature Pyramid Networks(FPN)改进MViT结构,并将其应用于目标检测和实例分割。实验表明,池化注意力比窗口注意力机制(例如Swin)更有效。另外,论文进一步开发了一种简单的混合池化注意力和窗口注意力的方案,可以实现更好的准确性/计算权衡。 - 论文提供了五种尺寸的
MViT2架构,只需很少的修改就能作为图像分类、对象检测和视频分类的通用视觉架构。实验表明,MViT在ImageNet分类的准确率为88.8%,COCO对象检测的APbox准确率为58.7%,Kinetics-400视频分类的准确率为86.1%。其中,在视频分类任务上的准确率是非常出色的。
Revisiting Multiscale Vision Transformers
MViTv1的关键思想是为低级和高级视觉建模构建不同的阶段,而不是像ViT那样全是单尺度块。MViTv1缓慢地扩展通道宽度 D D D,同时降低网络输入到输出阶段的序列长度 L \boldsymbol{\mathit{L}} L,具体可以看之前的文章 【MViT:性能杠杠的多尺度ViT | ICCV 2021】。
为了在Transformer块内执行下采样,MViT引入了池化注意力(Pooling Attention)。具体来说,对于输入序列 X ∈ R L × D X\in{\mathbb{R}}^{L\times D} X∈RL×D,分别对查询、键和值张量应用线性投影 W Q {W}_{Q} WQ、 W K {W}_{K} WK、 W V ∈ R D × D {W}_{V}\in\mathbb{R}^{D\times D} WV∈RD×D,以及池化运算符 ( P {\mathcal{P}} P):
$$
Q={\mathcal P}{Q}\left(X W{Q}\right),;K={\mathcal P}{K}\left(X W{K}\right),;V={\mathcal P}{V}\left(X W{V}\right)
\quad\quad(1)
$
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1356
1356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









