







 文章介绍了一种使用能量函数进行out-of-distribution(OOD)输入检测的方法,它通过非概率的energyscore有效区分训练集中和训练集外的数据,相较于softmax置信度,这种方法更稳定,提高了OOD检测的准确性,对实际算法具有重要意义。
文章介绍了一种使用能量函数进行out-of-distribution(OOD)输入检测的方法,它通过非概率的energyscore有效区分训练集中和训练集外的数据,相较于softmax置信度,这种方法更稳定,提高了OOD检测的准确性,对实际算法具有重要意义。
论文提出用于out-of-distributions输入检测的energy-based方案,通过非概率的energy score区分in-distribution数据和out-of-distribution数据。不同于softmax置信度,energy score能够对齐输入数据的密度,提升OOD检测的准确率,对算法的实际应用有很大的意义
来源:晓飞的算法工程笔记 公众号
论文: Energy-based Out-of-distribution Detection

Introduction
今天给大家分享一篇基于能量函数来区分非训练集相关(Out-of-distribution, OOD)输入的文章,连LeCun看了都说好。虽然文章是2020年的,但里面的内容对算法实际应用比较有用。这篇文章提出的能量模型想法在之前分享的《OWOD:开放世界目标检测,更贴近现实的检测场景 | CVPR 2021 Oral》也有应用,有兴趣的可以去看看。
现实世界是开放且未知的,OOD由于与训练集差异很大,使用通过特定训练集训练出来的模型进行预测的话,往往会出现不可控的结果。因此,确定输入是否为OOD并过滤掉,对算法在高安全要求场景下的应用是十分重要的。
大部分OOD研究依赖softmax置信度来过滤OOD输入,将低置信度的认定为OOD。然而,由于网络通常已经过拟合了输入空间,softmax对跟训练集差异较大的输入时常会不稳定地返回高置信度,所以softmax并不是OOD检测的最佳方法。还有部分OOD研究则从生成模型的角度来产生输入的似然分数 l o g p ( x ) logp(x) logp(x),但这种方法在实践中难以实现而且很不稳定,因为需要估计整个输入空间的归一化密度。
为此,论文提出energy-based方法来检测OOD输入,将输入映射为energy score,能直接应用到当前的网络中。论文还提供了理论证明和实验验证,表明这种energy-based方法比softmax-based和generative-based方法更优。
Background: Energy-based Models
EBM(energy-based model)的核心是建立一个函数 E ( x ) : R D → R E(x): \mathbb{R}^D\to\mathbb{R} E(x):RD→R,将输入 x x x映射为一个叫energy的常量。
一组energy常量可以通过Gibbs分布转为概率分布 p ( x ) p(x) p(x):
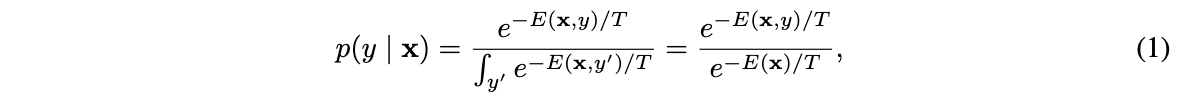
这里将 ( x , y ) (x,y) (x,y)作为输入,对于分类场景, E ( x , y ) E(x,y) E(x,y)可认为是数据与标签相关的energy常量。分母 ∫ y ′ e − E ( x , y ′ ) / T \int_{y^{'}}e^{-E(x,y^{'})/T} ∫y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1624
1624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









