




 文章探讨了在大型语言模型(LLM)如ChatGLM的基础上,如何构建应用生态系统。通过继承和改造LLM类,实现了ChatGLM到langchain的适配。同时,展示了如何创建定制化工具集,如使用RapidAPI的搜索工具,并结合LLM进行信息检索和整合。文章通过示例代码展示了如何将这些工具集成到智能代理中,以增强LLM的功能。最后,文章强调了围绕LLM构建生态的重要性及其潜在价值。
文章探讨了在大型语言模型(LLM)如ChatGLM的基础上,如何构建应用生态系统。通过继承和改造LLM类,实现了ChatGLM到langchain的适配。同时,展示了如何创建定制化工具集,如使用RapidAPI的搜索工具,并结合LLM进行信息检索和整合。文章通过示例代码展示了如何将这些工具集成到智能代理中,以增强LLM的功能。最后,文章强调了围绕LLM构建生态的重要性及其潜在价值。
背景:
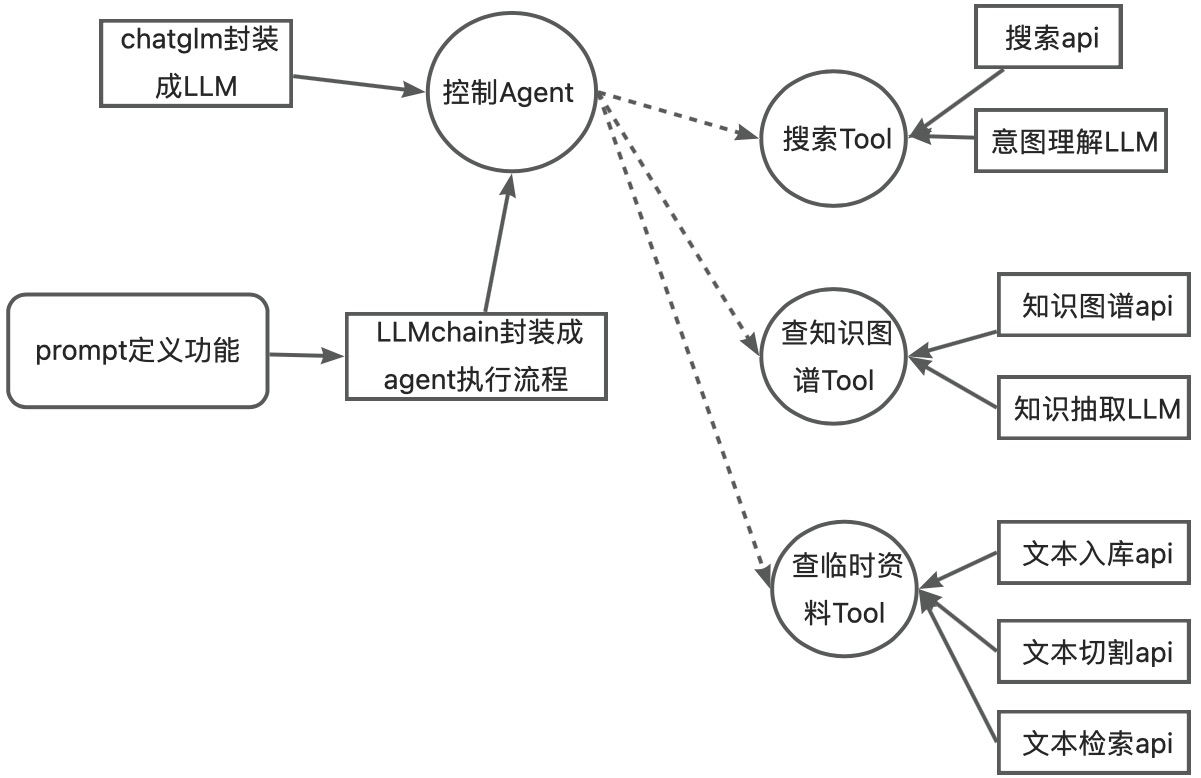
这个系列文章,会从LLM搭建应用生态角度来写。从0到1训练一个大的通用的模型对于大部分人和团队来讲是不现实的。重资金,重技术含量、重投入这几个门槛可以把很多团队直接劝退。那么在LLM蓬勃发展的时候我们可以做些什么呢,是否可以围绕LLM来搭建生态,搭建应用市场;针对LLM模型的不足做一些小的设计训练呢。这个其实很像发动机引擎,无论是汽车发动机引擎、柴油发动机引擎还是航空发动机引擎,能造的其实全球也不超过20家。但是围绕着这些引擎,延展出了汽车、农用器械、矿产机械、船舶、海洋、火车、飞机.....一系列的产业链、产业生态,编织出了现代工业的网。同理不从0造LLM引擎,深入的理解引擎原理,基于LLM引擎搭建应用生态是否也是可行呢。这一系列的文章尝试来做这件事情,如何打造LLM的生态,如何把LLM引擎能力引出、如何做各种转接头把LLM能力转成适配的动力。
这篇文章主要会介绍下面3部分:
1.Chatglm转成适配langchian的llm模式
2.搭建定制化的工具集
3.基于llm、工具结合构建有一定自主性Agent
代码实现
model
实现思路,继承langchain.llm.base中的LLM类,重写_call方法、_identifying_params属性类,load_model方法用transformer的AutoModel.from_pretrained来加载chatglm模型,把实例化的model传给LLM的model,chatglm基于prompt生成的逻辑封装在generate_resp方法,LLM的_call方法调用generate_resp获取生成逻辑。
### define llm ###
from typing import List, Optional, Mapping, Any
from functools import partial
from langchain.llms.base import LLM
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from transformers import AutoModel, AutoTokenizer
### chatglm-6B llm ###
class ChatGLM(LLM):
model_path: str
max_length: int = 2048
temperature: float = 0.1
top_p: float = 0.7
history: List = []
streaming: bool = True
model: object = None
tokenizer: object = None
@property
def _llm_type(self) -> str:
return "chatglm-6B"
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {
"model_path": self.model_path,
"max_length": self.max_length,
"temperature": self.temperature,
"top_p": self.top_p,
"history": [],
"streaming": self.streaming
}
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
add_history: bool = False
) -> str:
if self.model is None or self.tokenizer is None:
raise RuntimeError("Must call `load_model()` to load model and tokenizer!")
if self.streaming:
text_callback = partial(StreamingStdOutCallbackHandler().on_llm_new_token, verbose=True)
resp = self.generate_resp(prompt, text_callback, add_history=add_history)
else:
resp = self.ge 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8718
8718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









