



 本文介绍了如何在Google Colab中使用暗黑模式,读取CSV文件,快速访问StackOverflow,重启内核,将Notebook提交到GitHub,以及如何分享Notebook。此外,还提供了详细步骤,帮助开发者更好地利用Colab进行AI和数据科学项目。
本文介绍了如何在Google Colab中使用暗黑模式,读取CSV文件,快速访问StackOverflow,重启内核,将Notebook提交到GitHub,以及如何分享Notebook。此外,还提供了详细步骤,帮助开发者更好地利用Colab进行AI和数据科学项目。

来源:机器之心
切换暗黑模式、读取 CSV 文件… 这些非常实用的小技巧为开发者使用谷歌 Colab Notebooks 提供了便利。

Google Colab 给广大的 AI 爱好者和开发者提供了免费的 GPU,他们可以在上面轻松地跑 Tensorflow、PyTorch 等深度学习框架。特别地,Colab 实时 Notebooks 在数据共享方面为广大开发者提供了便利,通过链接即可与其他的开发者共享文件。
在本文中,数据科学家 Iden W. 为读者详细地介绍了使用 Google Colab Notebooks 的小技巧,主要包括以下几个方面:
切换暗黑模式
读取 CSV 文件
IT问答的快捷方式
启动内核
提交至 GitHub 存储库并共享
分享 Google Colab Notebooks
切换暗黑模式
如果开发者想使用 Google Colab 的暗黑模式,请点击「Tools」选项卡,然后按照下图所示的步骤进行设置。
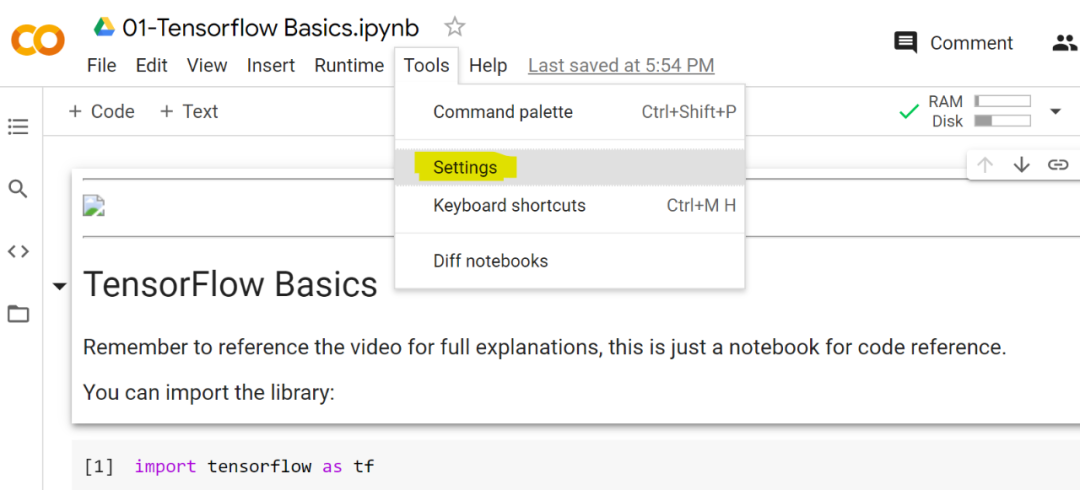
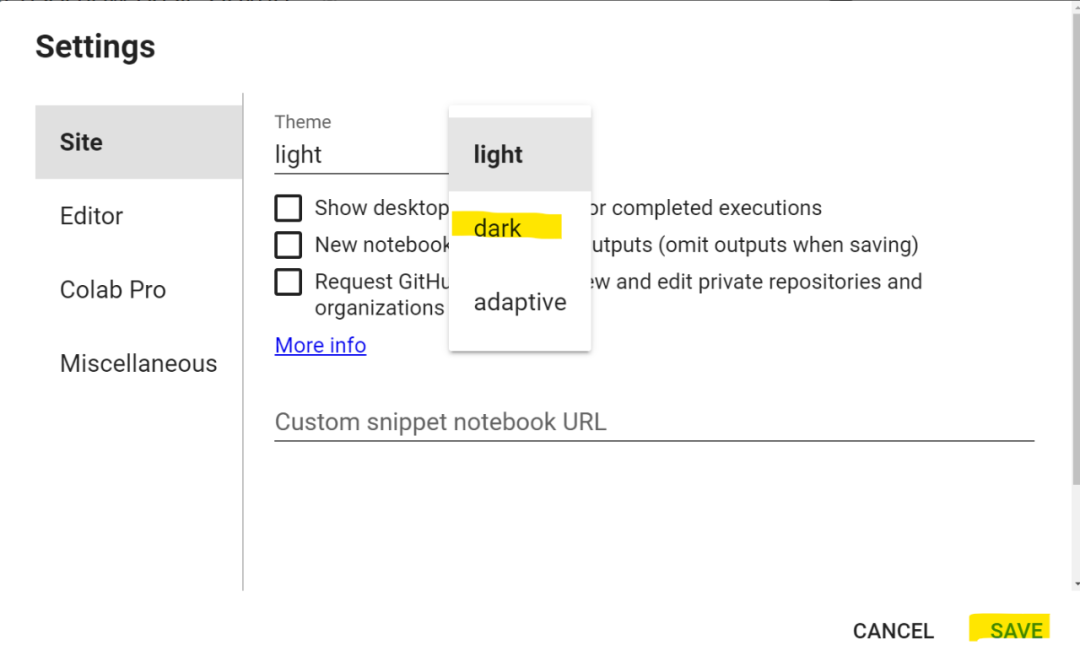
在「settings」中,你可以单击「Site」菜单,然后选择「dark」功能,单击保存。操作完成后即可切换暗黑模式。
读取 CSV 文件
从 Google Drive 云端硬盘读取 CSV 文件非常容易,你可能在 Google Drive 云盘上为 notebooks 或数据文件创建或指定了文件夹。或者你将数据自动上传至创建的文件夹「drive/MyDrive/Colab Notebooks」。
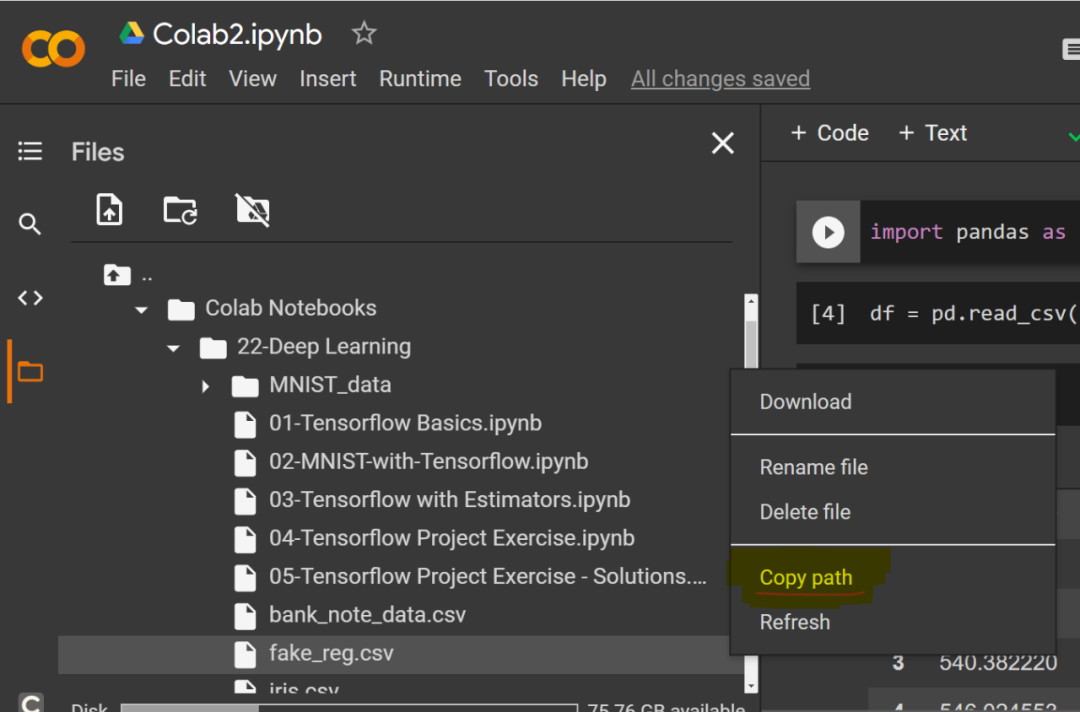
你只需在「Drive-MyDrive-Colab Notebooks」文件夹找到自己的文件就可以了。右键单击要读取的文件名,你将看到如下所示的菜单。左键单击「Copy path」选项。
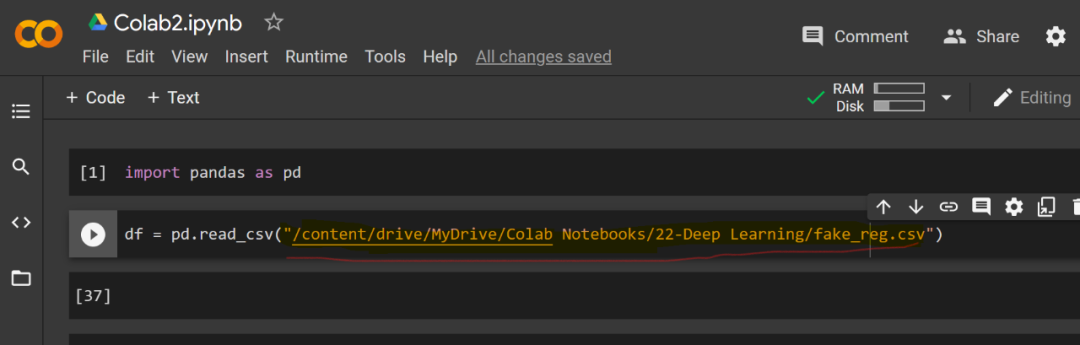
有了文件路径后,你可以将路径地址粘贴在代码行中的引号之间。当运行单元格时,「df」也会运行,如下所示
df=pd.read_csv(‘/content/drive/MyDrive/Colab Notebooks/22-Deep Learning/fake_reg.csv’)
Stack Overflow
如果你的代码有问题,则可以点击输出单元格(output cell)下方的「SEARCH STACK OVERFLOW」按钮。
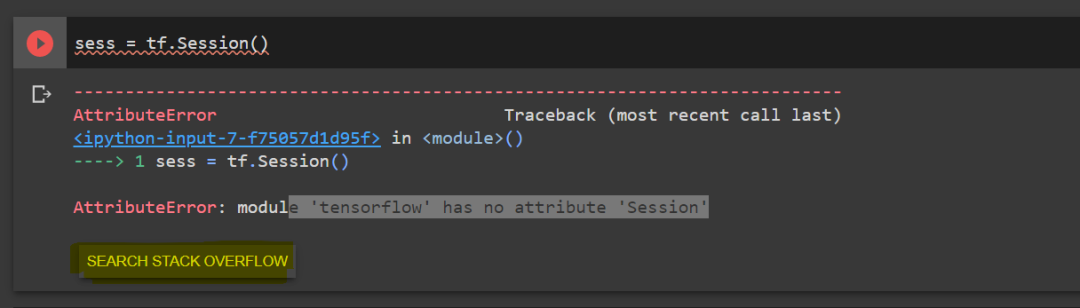
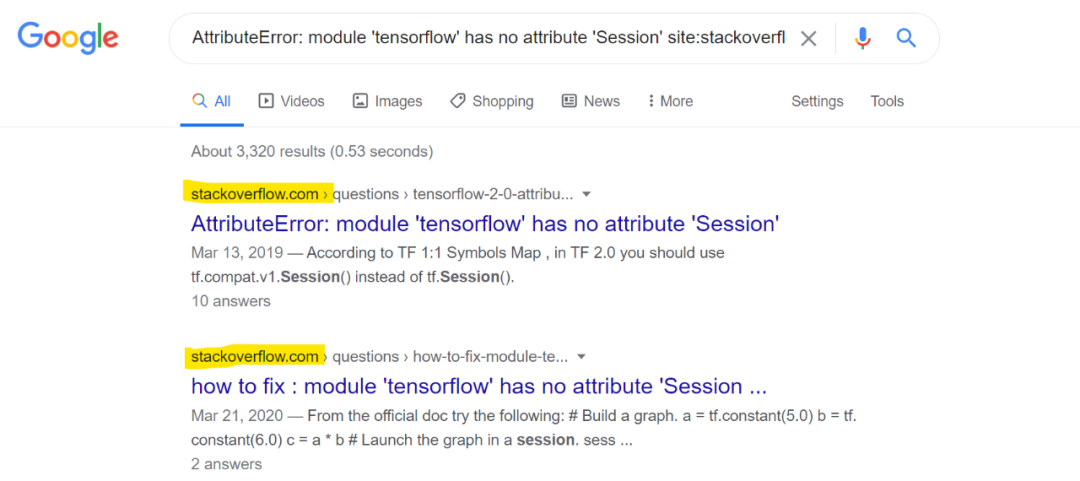
在进行深入研究时,你难免要用到 Google。这时,你可以在页面搜索解决方案,然后返回到浏览器上的 Google Colab 标签。
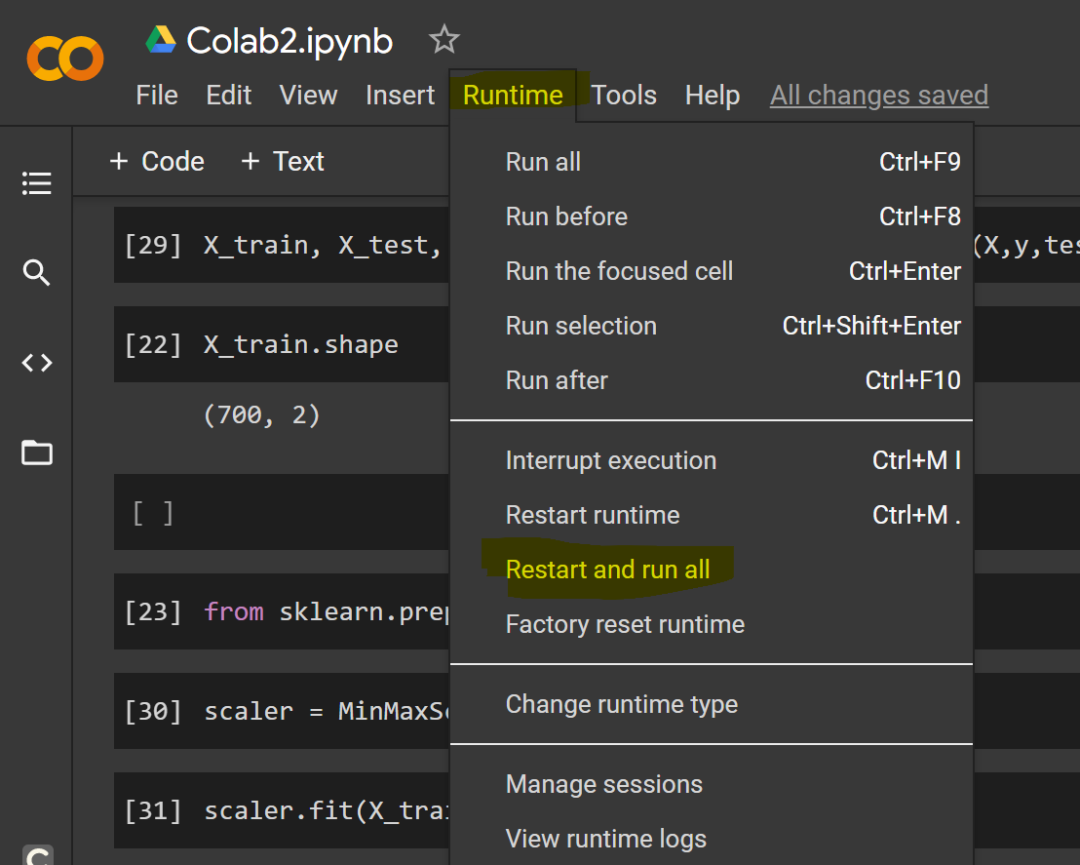
启动内核
如果 Google Colab 内核有问题,你可以重新启动并运行所有代码,也可以像在 Jupyter notebooks 中那样从菜单中选择选项。具体来讲,选择「Runtime」,然后选择所需的选项。
提交至 GitHub 存储库并共享
当文件在 notebook 中处理完后,你既可以将文件保存到 Google Drive 云盘,也可以将其上传至 GitHub 存储库。
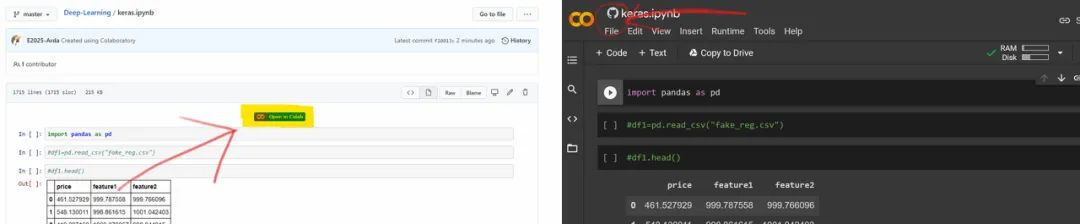
将文件提交至 GitHub 存储库后,你可以使用文件上方的快捷链接(shortcut link)从 GitHub 帐户打开文件。当使用 Google Colab 链接打开文件时,你将看到文件左上角的 GitHub 图标。
如果你想分享 GitHub 文件,则可以点击右上角的「share」按钮。同时会出现一个警告:「警告:共享链接将不包含你的编辑或输出。如果想要包含编辑内容,请选择 File→将副本保存在驱动器(Drive )中,并基于该副本生成链接。」
通过上述方式可以复制并分享 notebook。但是,如果你想分享文件,并希望同事可以看到文件更新和变更,则可以通过 notebook 左上角的链接(Copy to Drive)将其保存到 Drive 中,并共享来自 Google Drive 的链接。
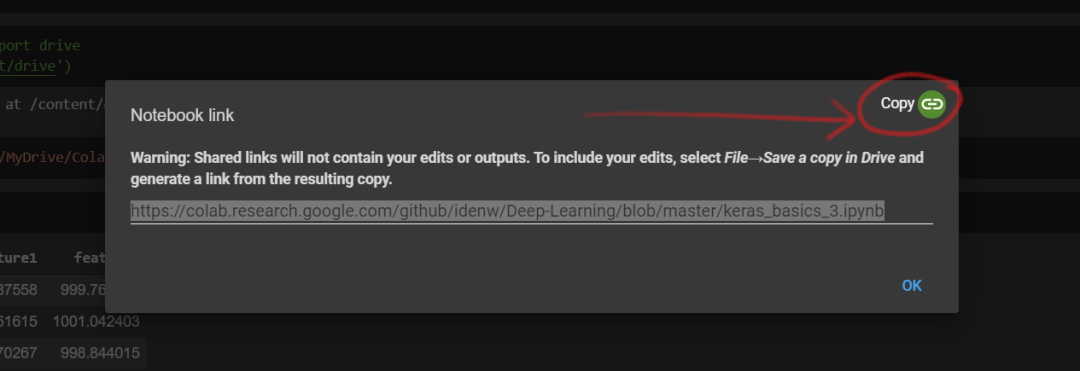
分享 Google Colab Notebook
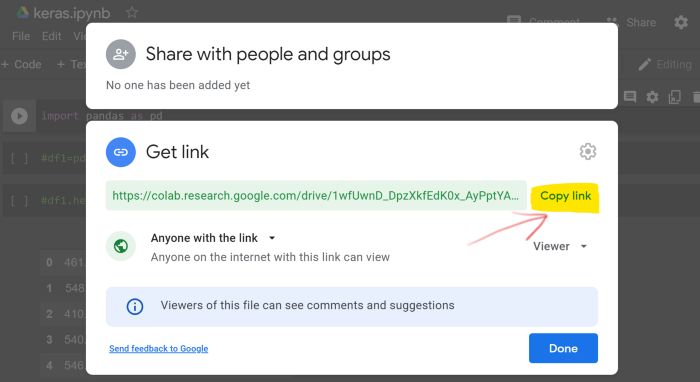
当你想要分享 notebook(在 Google Drive 文件夹中操作文件),则可以单击「Share」按钮。
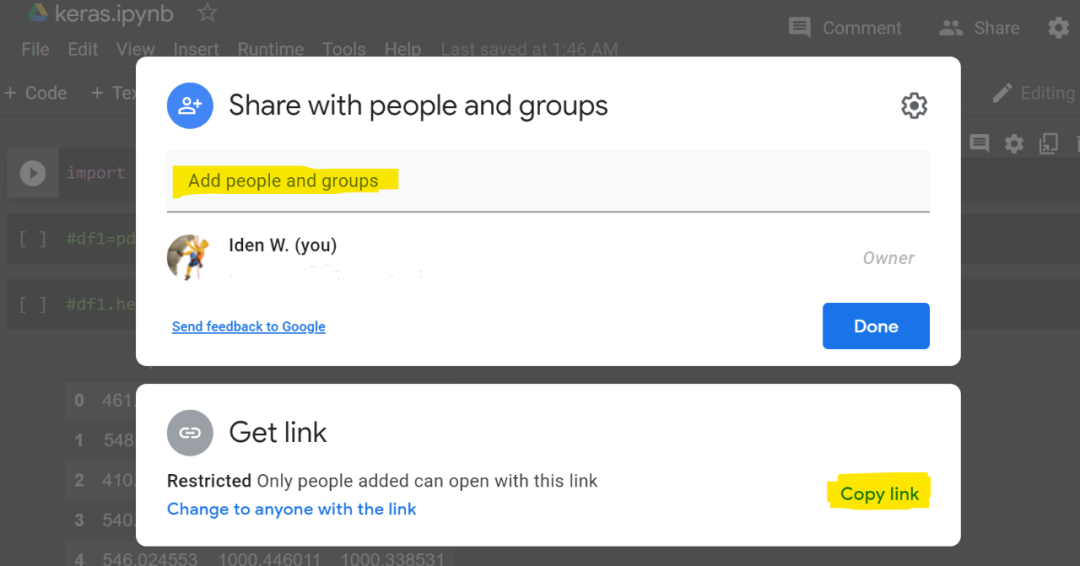
你可以将同事的邮件地址添加到下面的行中来分享你的 notebook,然后单击「Done」。
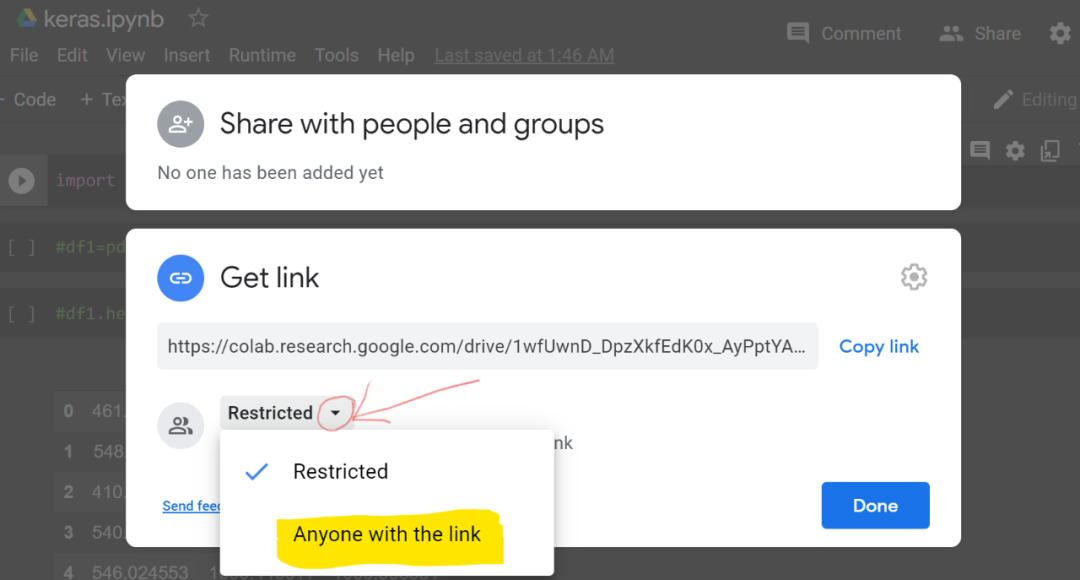
或者,你可以单击「Get link」窗格中的任意位置,然后单击「Restricted 」选项附近的小三角形图标,并将选项更改为「Anyone with the link」,如下所示:
然后单击查看「Viewer」附近的小三角形图标,有 3 个共享选项。「viewer」选项仅显示具有链接的文件;「Commenter」选项可以为他人提供链接,访问者不会对你的文件进行修改,但可以评论;「Editor」选项允许拥有链接的人查看、提交和编辑你的文件。
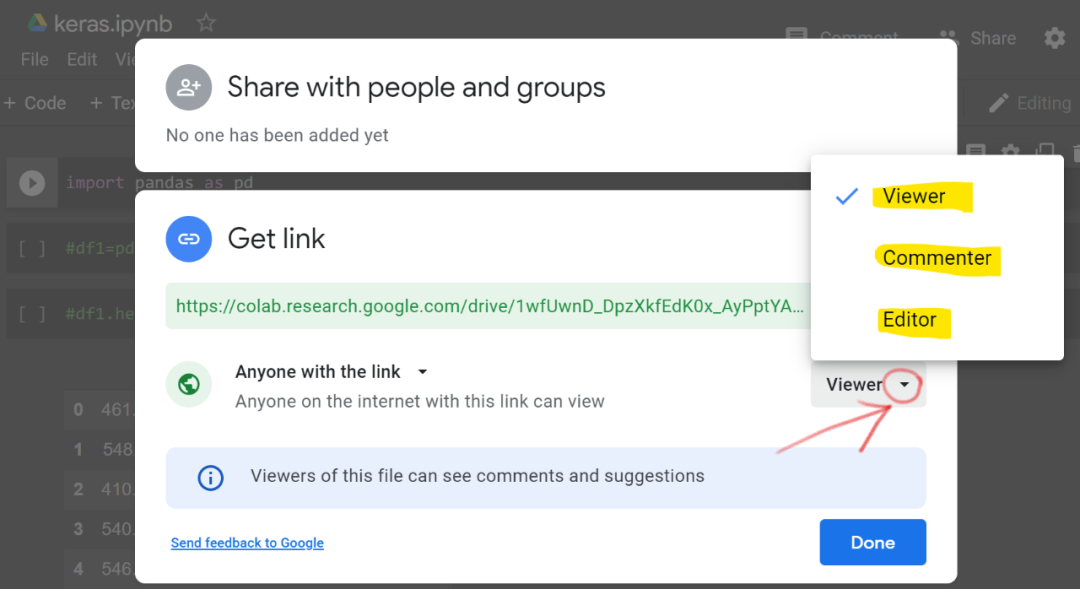
一旦你设置了其中一个选项,则可以将链接分享给其他人。
原文链接:https://idenw.medium.com/google-colab-2-dark-mode-runtime-share-github-69498e9057e2
---------End---------

后台回复「微信群」,将邀请加入读者交流群。

《Python知识手册》| 《Markdown速查表》|《Python时间使用指南》|《Python字符串速查表》|《SQL经典50题》|《Python可视化指南》|《Plotly可视化指南》|《Pandas使用指南》|《机器学习精选》

????分享、点赞、在看,给个三连击呗!????

















 9724
9724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









