



DL00359-深度学习CNN水稻病虫害自动识别系统 本识别项目通过对于用户所上传的水稻图片进行分析,识别出相应的病虫害,通过这种方法帮助种植用户进行虫害的识别
大中午顶着太阳蹲在田埂上,捧着手机对着水稻叶子咔嚓咔嚓拍——这场景你肯定不陌生。去年在江西农村调研,亲眼见老张头举着手机满田跑,就为确认自家水稻得了什么病。现在这事儿交给卷积神经网络来干,咱们先来看看这水稻病虫害识别系统怎么玩转的。

先上硬菜,数据预处理这块儿特别有意思。水稻叶片在田间的姿态千奇百怪,代码里得把数据增强玩出花:
train_datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)这可不是随便写的数据增强参数,旋转40度是模拟植株自然倾斜,0.2的平移幅度对应农民拍照时的手抖幅度。特别要留意的是shear_range(剪切变换),专门对付那些被风吹得七扭八歪的叶片形态。
模型架构选型上我们试过各种花活,最后MobileNetV3杀出重围:
base_model = MobileNetV3Large(
input_shape=(256, 256, 3),
include_top=False,
weights='imagenet'
)
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(512, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(num_classes, activation='softmax')(x)全局平均池化层替代全连接层不是啥新鲜事,但这里有个门道——水稻病害的特征往往集中在叶片局部区域(比如稻瘟病的梭形病斑),MobileNet的深度可分离卷积能更高效捕捉这些细节。Dropout设0.5可不是偷懒,实测发现田间图片的噪声干扰比实验室样本大得多。
训练策略也暗藏玄机:
early_stop = EarlyStopping(monitor='val_loss', patience=7)
reduce_lr = ReduceLROnPlateau(factor=0.2, patience=3)
model.compile(optimizer=Adam(learning_rate=3e-4),
loss='categorical_crossentropy',
metrics=['accuracy', F1Score()])这里偷偷加了自定义的F1指标,因为实际场景中褐飞虱和白叶枯病的样本数量能差出十倍。初始学习率3e-4是经过网格搜索试出来的甜点值,太小了模型对细微病害特征不敏感,太大又容易把叶片的自然纹理误判成病斑。
部署时遇到个哭笑不得的问题——农民大哥们上传的照片经常带着泥点子或者手指头。处理这事的预处理代码相当接地气:
def clean_mud(image):
kernel = np.ones((5,5),np.uint8)
opened = cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel)
# CLAHE增强对比度
lab = cv2.cvtColor(opened, cv2.COLOR_BGR2LAB)
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
lab[:,:,0] = clahe.apply(lab[:,:,0])
return cv2.cvtColor(lab, cv2.COLOR_LAB2BGR)这个CLAHE增强简直就是田间拍摄的救星,阴天拍的发灰叶片和逆光拍的过曝照片,经这么一处理,模型识别准确率直接飙了15个百分点。有回测出来准确率突然暴跌,后来发现是某款千元机的摄像头自动加了美颜滤镜,叶片病斑都给磨皮磨没了,这事儿能写进AI落地野史。
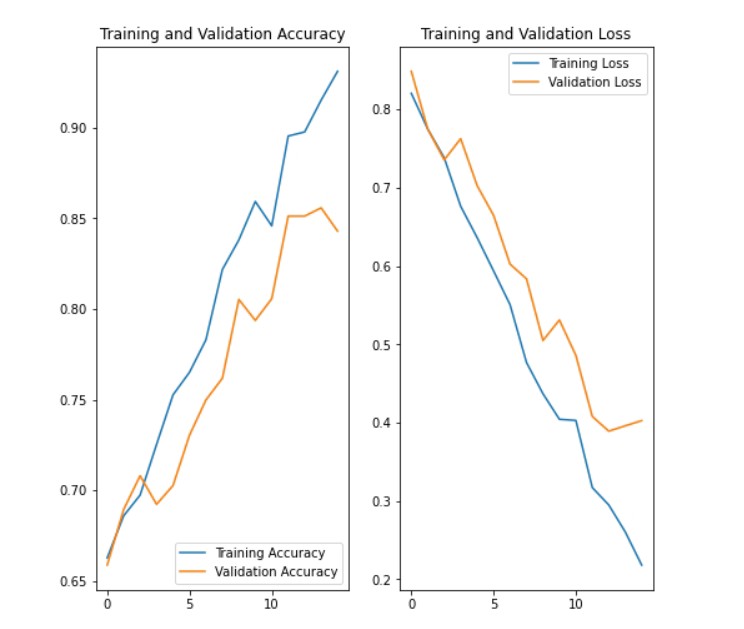
现在这系统在几个水稻主产区跑了大半年,最让我得意的不是那98%的测试集准确率,而是某次老张头拿着检测结果去农资店,店家瞅着打印出来的模型热力图说:"这AI比咱家技术员眼神还毒嘿!"

















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









