



RNN预测模型做多输入单输出预测模型,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2021及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。 PS:以下效果图为测试数据的效果图,主要目的是为了显示程序运行可以出的结果图,具体预测效果以个人的具体数据为准。 2.由于每个人的数据都是独一无二的,因此无法做到可以任何人的数据直接替换就可以得到自己满意的效果。 这段程序主要是一个基于循环神经网络(RNN)的预测模型。它的应用领域可以是时间序列预测、回归分析等。下面我将对程序的运行过程进行详细解释和分析。 首先,程序开始时清空环境变量、关闭图窗、清空变量和命令行。然后,通过xlsread函数导入数据,其中'数据的输入'和'数据的输出'是两个Excel文件的文件名。 接下来,程序对数据进行归一化处理。首先使用mapminmax函数将输入数据P_train和P_test归一化到0到1的范围内,并保存归一化的参数ps_input。然后,使用mapminmax函数将输出数据T_train和T_test归一化到0到1的范围内,并保存归一化的参数ps_output。 接着,程序将归一化后的数据转换为特定的格式。使用for循环将p_train和p_test转换为vp_train和vp_test,其中vp_train和vp_test是每个样本的列向量。这样做是为了适应RNN模型的输入格式。 然后,程序定义了一些基础参数。numFeatures表示特征维度,即特征变量的列数;numResponses表示输出维度,这里是1。 接下来,程序设计了一个RNN结构。该结构包含了输入层、GRU层、ReLU激活层、LSTM层、丢弃层、全连接层和回归层。其中,GRU层和LSTM层是循环神经网络的一种变体,用于处理序列数据。 然后,程序根据当前计算环境(GPU或CPU)设置网络参数。如果有GPU设备,则使用GPU进行训练,否则使用CPU。 接着,程序定义了训练选项。使用adam优化算法进行训练,最大训练次数为2000次,梯度阈值为1,初始学习率为0.01,学习率调整策略为piecewise,训练850次后开始调整学习率,学习率调整因子为0.25,最小批量大小为96,关闭训练过程中的详细输出,每个epoch后对数据进行洗牌,训练环境根据之前判断的设备类型进行设置,最后画出训练过程的曲线。 接下来,程序使用trainNetwork函数对vp_train和t_train进行训练,使用之前定义的网络结构和训练选项。 然后,程序使用训练好的网络对vp_train和vp_test进行预测,得到t_sim1和t_sim2。 接着,程序使用mapminmax函数将预测结果进行反归一化,得到T_sim1和T_sim2。 然后,程序计算均方根误差(RMSE),分别计算训练集和测试集的误差。误差的计算公式为每个样本的预测值与真实值之差的平方和除以样本数,再开平方。 接下来,程序计算R2值,用于评估预测模型的拟合程度。R2值的计算公式为1减去预测值与真实值之间的平方和与真实值与均值之间的平方和的比值。 然后,程序计算平均绝对误差(MAE),用于评估预测模型的预测精度。MAE的计算公式为预测值与真实值之差的绝对值之和除以样本数。 接着,程序绘制训练集和测试集的预测结果对比图。图中包含真实值和预测值,以及RMSE、R2和MAE的值。 然后,程序绘制训练集和测试集的真实值与预测值的线性拟合图。图中包含真实值和预测值,以及拟合直线。 接下来,程序绘制所有样本的真实值与预测值的线性拟合图。图中包含真实值和预测值,以及拟合直线。 然后,程序打印出评价指标,包括RMSE、R2和MAE。 最后,程序绘制测试集的预测误差图,用于分析预测模型的误差情况。 总结来说,这段程序是一个基于循环神经网络的预测模型,用于时间序列预测或回归分析。它通过对输入数据进行归一化处理,设计了一个包含GRU和LSTM层的RNN结构,使用adam优化算法进行训练,并计算了预测结果的误差和评价指标。程序的主要思路是通过训练RNN模型来学习输入数据的模式,并预测输出数据。涉及到的知识点包括循环神经网络、归一化处理、优化算法等。希望这个解释对你有帮助!如果还有其他问题,请随时提问。
时间序列预测是机器学习领域中的重要应用场景,尤其在金融、气象、工业控制等领域具有广泛的应用价值。本文介绍一种基于循环神经网络(RNN)的多输入单输出预测模型,该模型结合了GRU和LSTM的优势,能够有效处理序列数据的长期依赖关系。
模型架构设计
该RNN预测模型采用了混合神经网络架构,充分利用了不同类型循环神经网络的特点:
网络层结构
模型包含多个精心设计的网络层:
- 输入层:接收多特征时间序列数据
- GRU层:128个单元,使用He初始化方法,有效捕捉序列中的短期依赖关系
- ReLU激活层:引入非线性变换,增强模型表达能力
- LSTM层:64个单元,处理更复杂的长期依赖关系
- Dropout层:丢弃率25%,防止过拟合
- 输出LSTM层:32个单元,输出模式设为"last",仅返回序列最后一个时间步的输出
- 全连接层:将特征映射到最终输出维度
- 回归层:完成回归预测任务
这种混合架构既保留了GRU计算效率高的优点,又利用了LSTM处理长期依赖的强大能力,同时通过Dropout层增强模型的泛化性能。
数据处理流程
数据准备与划分
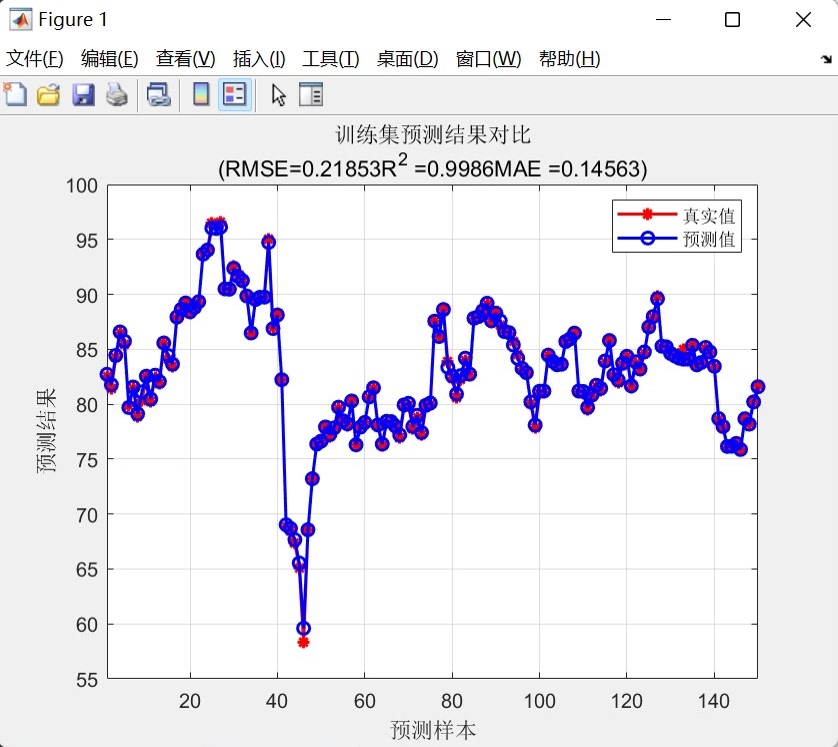
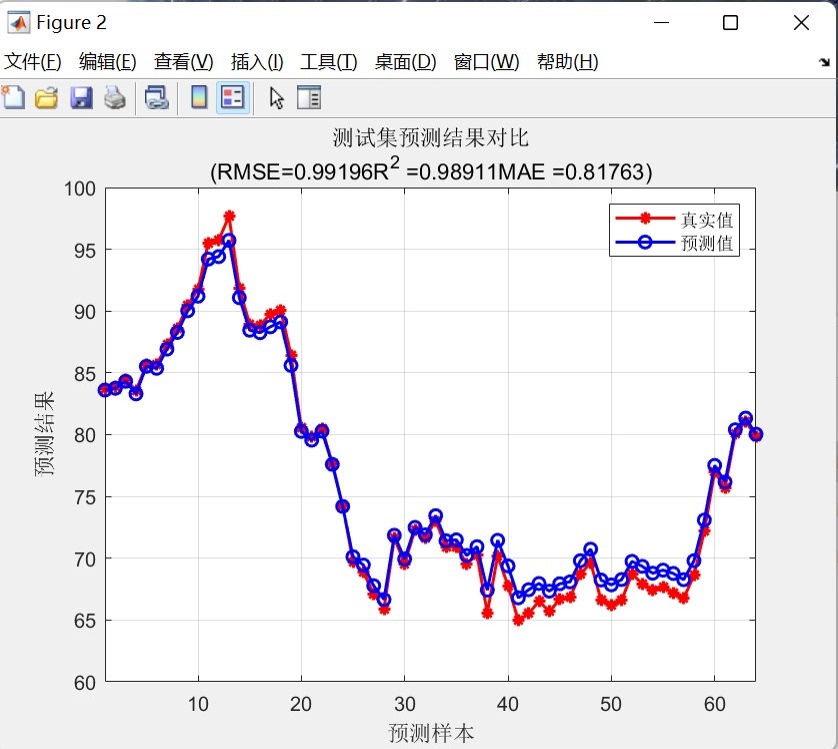
模型支持多输入特征的单输出预测。数据预处理阶段将原始数据集划分为训练集和测试集,其中前150个样本用于训练,剩余样本用于测试。这种划分方式确保了模型既能在足够数据上训练,又能有效评估泛化能力。
数据归一化
采用min-max归一化方法将数据缩放到[0,1]区间,这一步骤对神经网络训练的稳定性和收敛速度至关重要。归一化参数从训练数据中计算,并同样应用于测试数据,确保数据分布的一致性。
训练策略与优化
训练参数配置
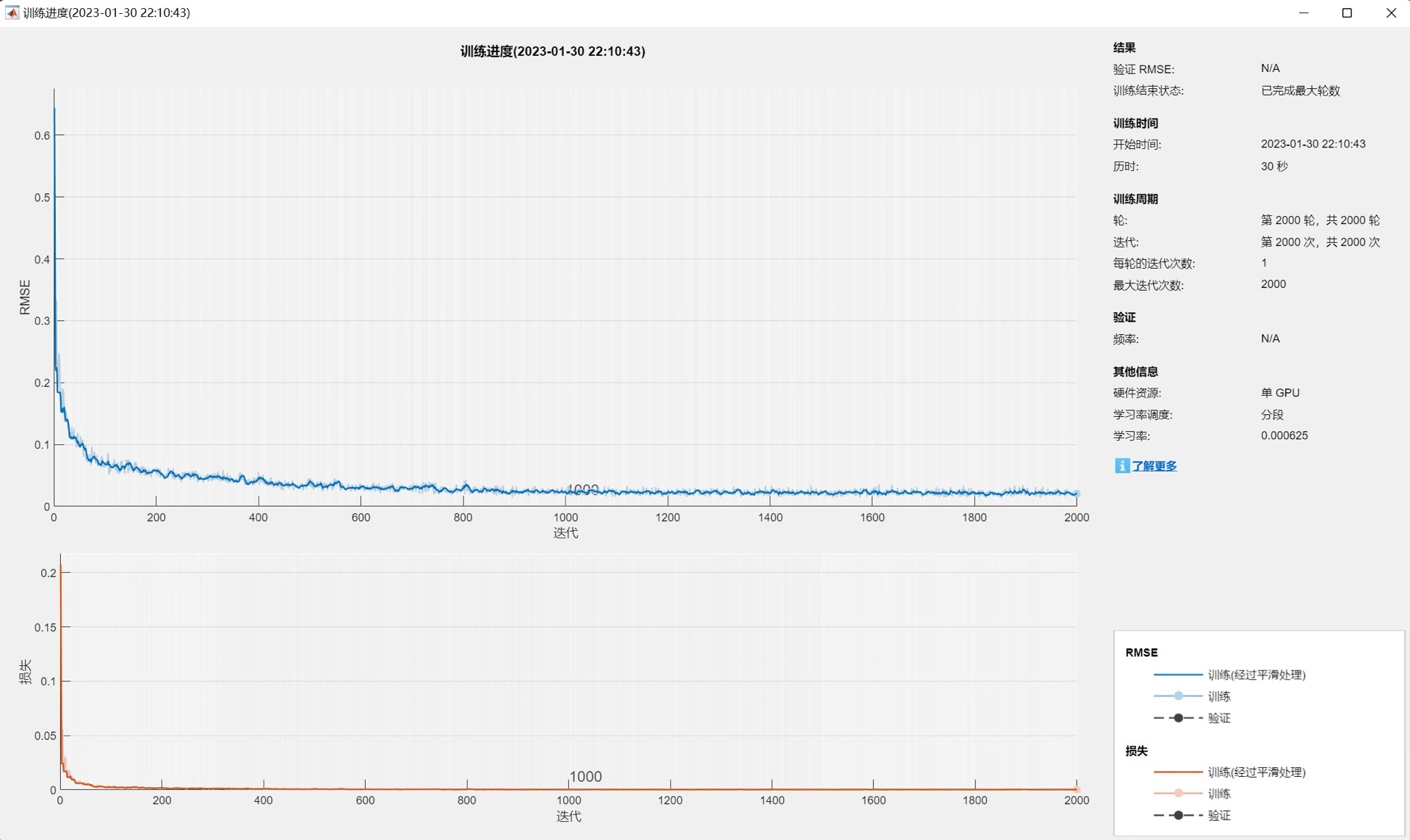
模型使用Adam优化算法,这是一种自适应学习率的优化方法,结合了AdaGrad和RMSProp算法的优点。训练过程设置了以下关键参数:
- 最大训练轮数:2000
- 初始学习率:0.01
- 学习率调度策略:分段常数衰减
- 学习率下降周期:850轮后
- 学习率下降因子:0.25
- 最小批大小:96
硬件加速支持
代码自动检测可用的计算资源,优先使用GPU进行训练,如无GPU则回退到CPU计算。这种设计使得模型既能利用GPU的并行计算优势,又保证了在无GPU环境下的可运行性。
模型评估体系
该实现提供了全面的模型评估指标,包括:
误差指标
- 均方根误差(RMSE):衡量预测值与真实值之间的偏差
- 平均绝对误差(MAE):反映预测误差的绝对大小
拟合优度指标
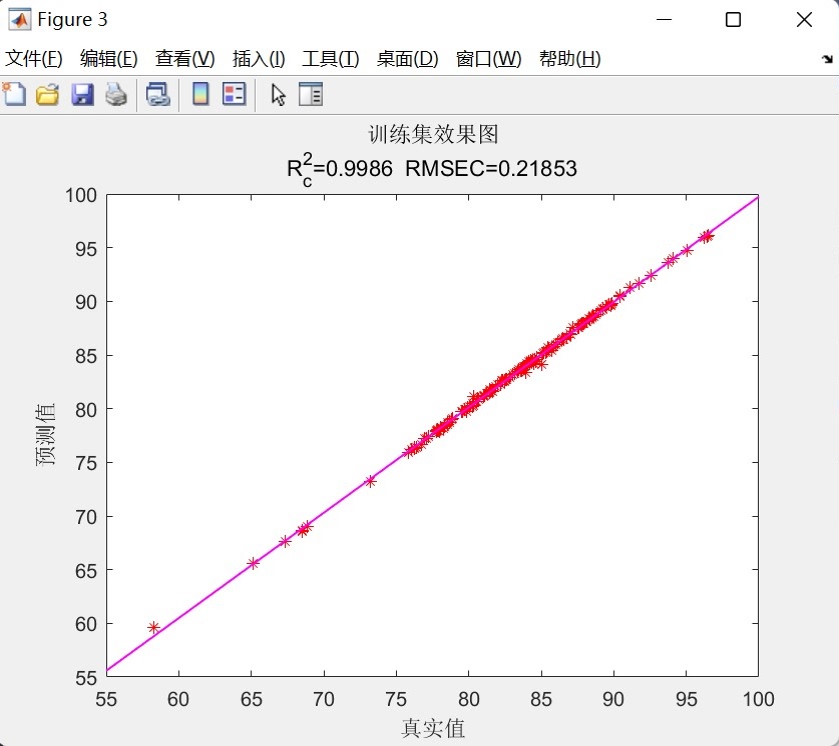
- 决定系数(R²):评估模型对数据变动的解释能力
这些指标分别计算训练集和测试集上的表现,使开发者能够全面了解模型的拟合程度和泛化能力。
可视化分析
模型提供了多种可视化结果,帮助用户直观理解预测效果:
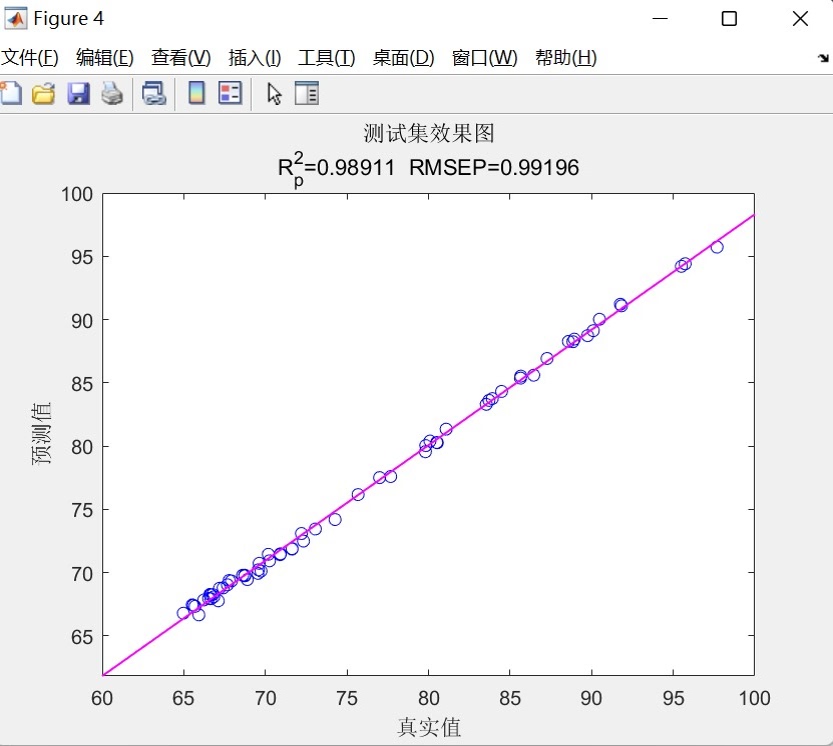
- 训练集/测试集预测对比图:展示预测值与真实值的对比趋势
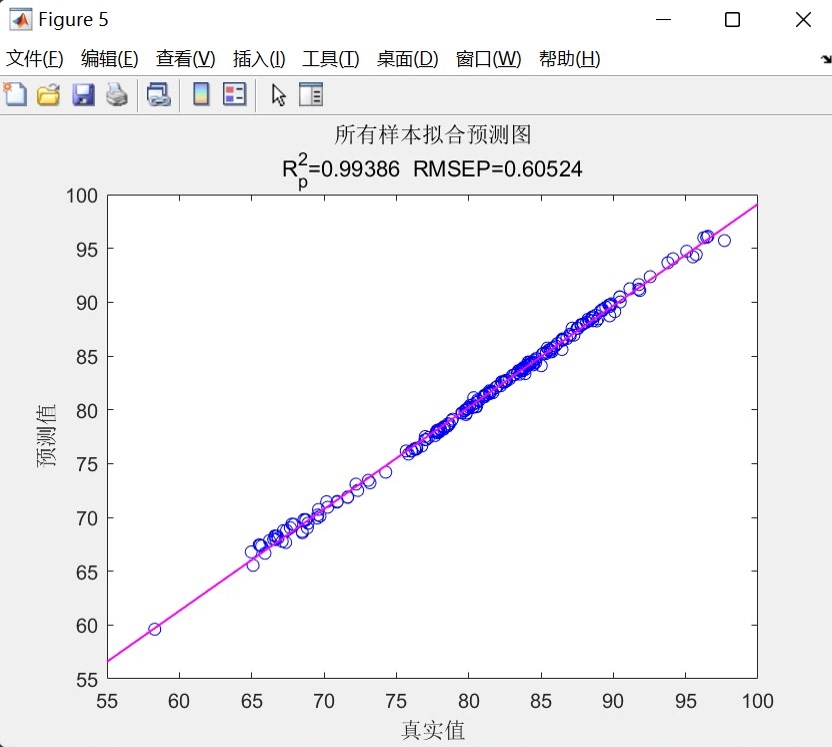
- 线性拟合图:显示预测值与真实值的线性关系
- 误差分布图:呈现测试集上预测误差的分布情况
这些可视化工具为模型调优和结果分析提供了有力支持。
应用特点与优势
该RNN预测模型具有以下显著特点:
- 即插即用:用户只需替换数据文件即可应用于自己的预测任务
- 架构灵活:混合RNN结构适应多种时间序列模式
- 全面评估:提供多角度模型评估指标
- 自动化流程:从数据预处理到结果可视化全自动完成
- 资源自适应:自动选择GPU/CPU计算资源
适用场景
该模型适用于各类多变量时间序列预测问题,如:
- 股票价格预测
- 销售量 forecasting
- 气象数据预测
- 工业过程控制
- 能源消耗预测
通过适当调整网络结构和超参数,用户可以针对特定领域的问题进行优化,获得更好的预测性能。
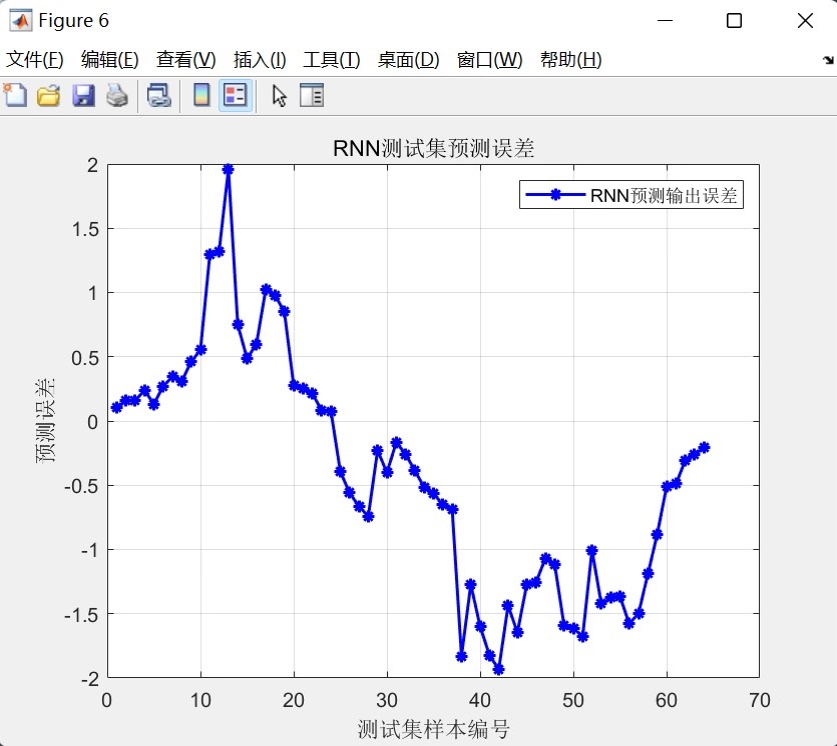
这种基于RNN的多输入单输出预测模型为时间序列分析提供了一个强大而灵活的工具,结合了现代深度学习技术与传统统计评估方法,在实际应用中表现出良好的预测准确性和稳定性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









