




 本文深入探讨Transformer模型中的FFN层,分析其计算过程和算力消耗,包括第一层升维和第二层降维的点积运算,以及与注意力层算力的综合。此外,还提到了在NLG任务中softmax层的算力需求,并预告了后续关于显存、中间计算结果和推理算力的内容。
本文深入探讨Transformer模型中的FFN层,分析其计算过程和算力消耗,包括第一层升维和第二层降维的点积运算,以及与注意力层算力的综合。此外,还提到了在NLG任务中softmax层的算力需求,并预告了后续关于显存、中间计算结果和推理算力的内容。
第一篇链接:LLM 参数,显存,Tflops? 训练篇(1) (qq.com)
第一篇我们讲完了Self-Attention层的算力要求和每一步生成的形状,
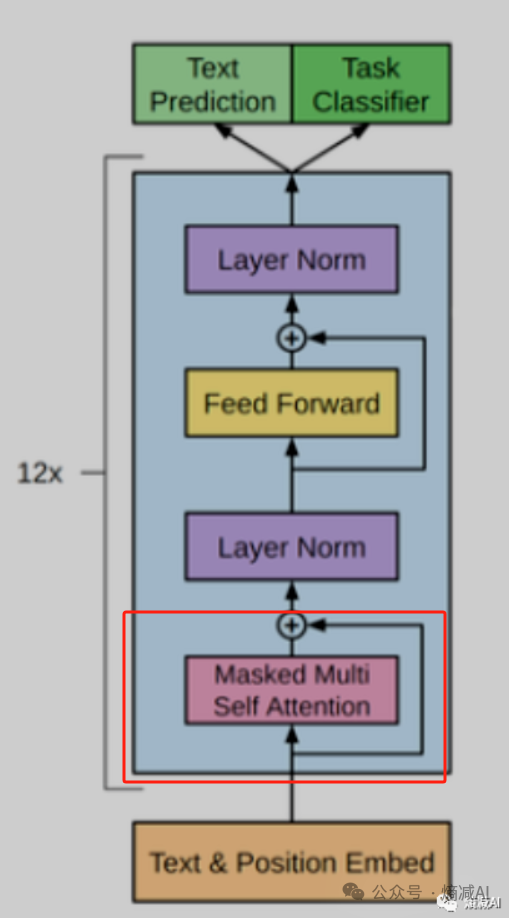
上节课我们讲的红框里的内容,我们继续从下往上看, 两个LN层就别看了也没啥特别多的可学习对象(跟MHA和FFN相比),其实还有什么drop out啥的,因为这玩意都没可学习的参数,所以都忽略,所以我们就看FFN层需要消耗多少算力
我们之前讲过FFN是干啥的,需要了解的读者请看这个系列:
小周带你读论文-2之"草履虫都能看懂的Transformer老活儿新整"Attention is all you need(1) (qq.com)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









